 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Post Training Neural Quantization: Layer-wise Calibration and Integer Programming
Paper and Code
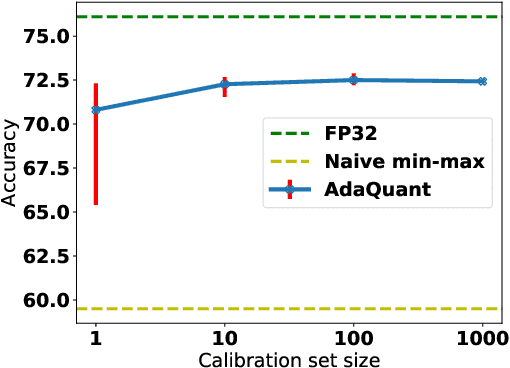

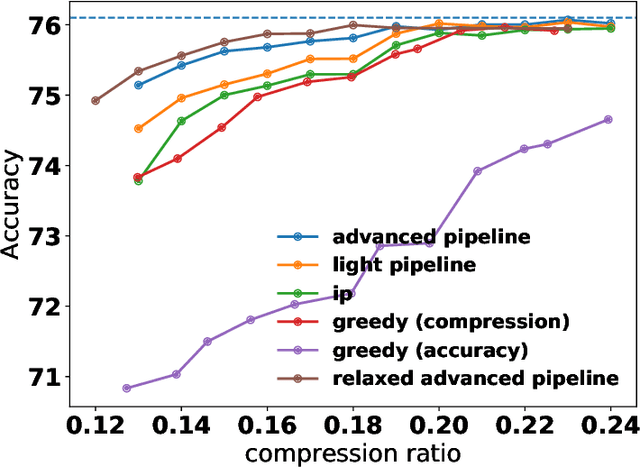
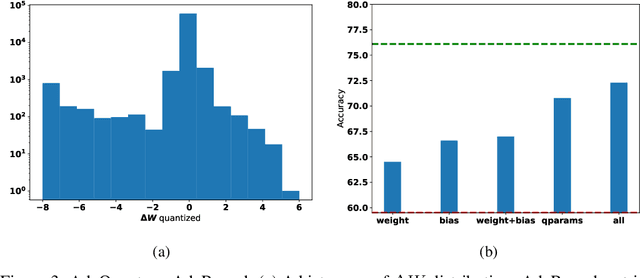
Most of the literature on neural network quantization requires some training of the quantized model (fine-tuning). However, this training is not always possible in real-world scenarios, as it requires the full dataset. Lately, post-training quantization methods have gained considerable attention, as they are simple to use and require only a small, unlabeled calibration set. Yet, they usually incur significant accuracy degradation when quantized below 8-bits. This paper seeks to address this problem by introducing two pipelines, advanced and light, where the former involves: (i) minimizing the quantization errors of each layer by optimizing its parameters over the calibration set; (ii) using integer programming to optimally allocate the desired bit-width for each layer while constraining accuracy degradation or model compression; and (iii) tuning the mixed-precision model statistics to correct biases introduced during quantization. While the light pipeline which invokes only (ii) and (iii) obtains surprisingly accurate results; the advanced pipeline yields state-of-the-art accuracy-compression ratios for both vision and text models. For instance, on ResNet50, we obtain less than 1% accuracy degradation while compressing the model to 13% of its original size. We open-sourced our code.