 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Content Safety: Real-Time Monitoring for Reasoning Vulnerabilities in Large Language Models
Mar 26, 2026Large language models (LLMs) increasingly rely on explicit chain-of-thought (CoT) reasoning to solve complex tasks, yet the safety of the reasoning process itself remains largely unaddressed. Existing work on LLM safety focuses on content safety--detecting harmful, biased, or factually incorrect outputs -- and treats the reasoning chain as an opaque intermediate artifact. We identify reasoning safety as an orthogonal and equally critical security dimension: the requirement that a model's reasoning trajectory be logically consistent, computationally efficient, and resistant to adversarial manipulation. We make three contributions. First, we formally define reasoning safety and introduce a nine-category taxonomy of unsafe reasoning behaviors, covering input parsing errors, reasoning execution errors, and process management errors. Second, we conduct a large-scale prevalence study annotating 4111 reasoning chains from both natural reasoning benchmarks and four adversarial attack methods (reasoning hijacking and denial-of-service), confirming that all nine error types occur in practice and that each attack induces a mechanistically interpretable signature. Third, we propose a Reasoning Safety Monitor: an external LLM-based component that runs in parallel with the target model, inspects each reasoning step in real time via a taxonomy-embedded prompt, and dispatches an interrupt signal upon detecting unsafe behavior. Evaluation on a 450-chain static benchmark shows that our monitor achieves up to 84.88\% step-level localization accuracy and 85.37\% error-type classification accuracy, outperforming hallucination detectors and process reward model baselines by substantial margins. These results demonstrate that reasoning-level monitoring is both necessary and practically achievable, and establish reasoning safety as a foundational concern for the secure deployment of large reasoning models.
Extraction of Typical Operating Scenarios of New Power System Based on Deep Time Series Aggregation
Aug 23, 2024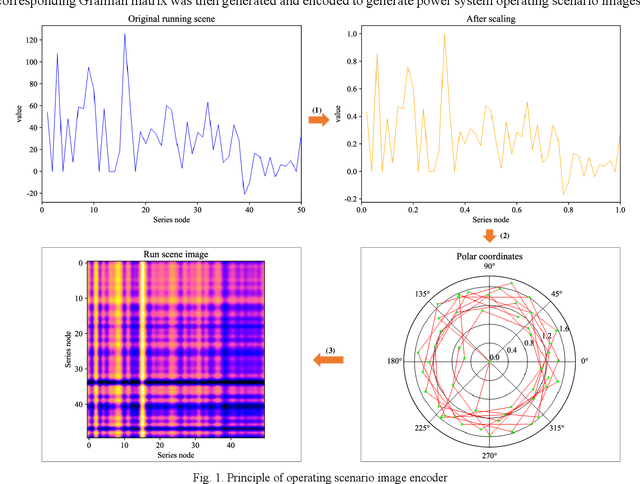
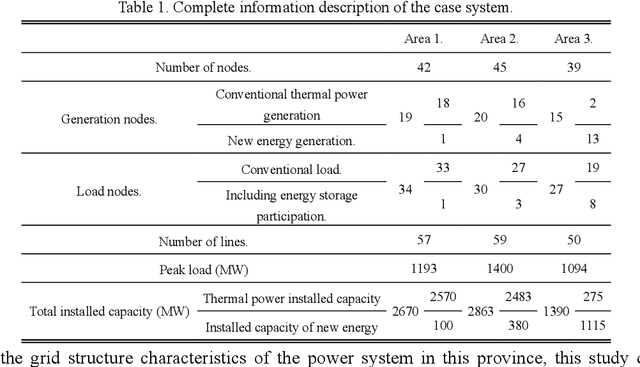
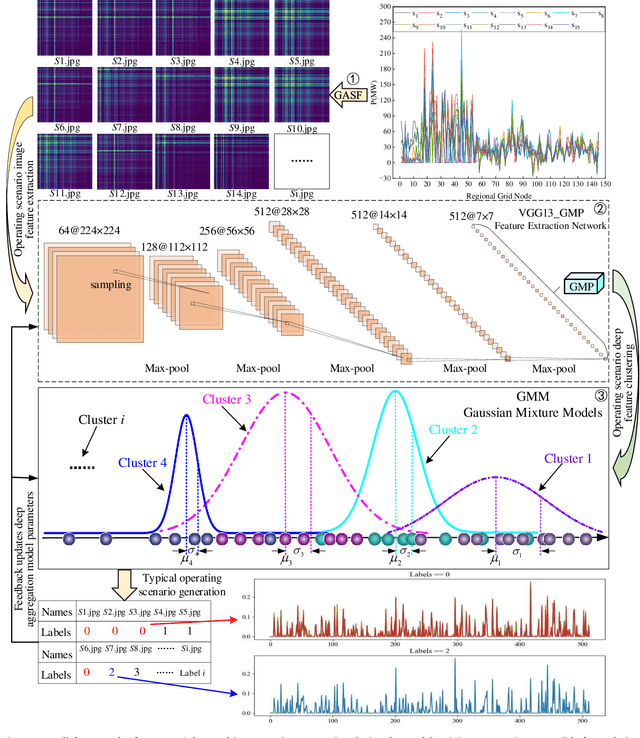
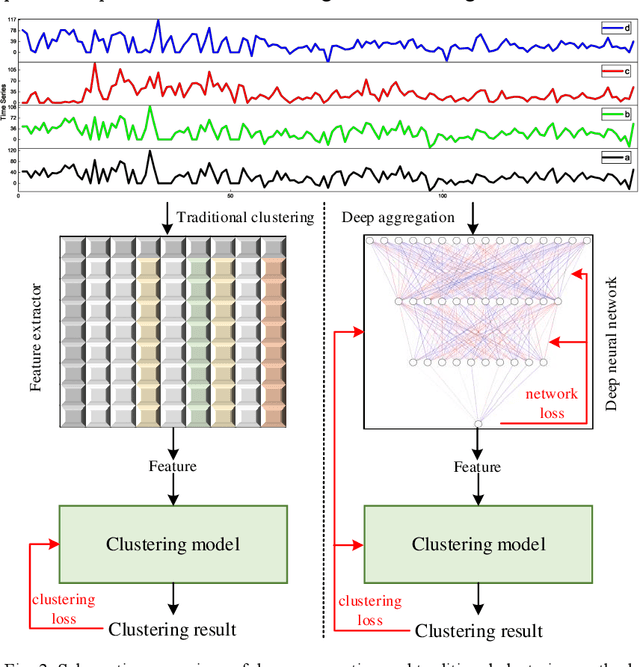
Extracting typical operational scenarios is essential for making flexible decisions in the dispatch of a new power system. This study proposed a novel deep time series aggregation scheme (DTSAs) to generate typical operational scenarios, considering the large amount of historical operational snapshot data. Specifically, DTSAs analyze the intrinsic mechanisms of different scheduling operational scenario switching to mathematically represent typical operational scenarios. A gramian angular summation field (GASF) based operational scenario image encoder was designed to convert operational scenario sequences into high-dimensional spaces. This enables DTSAs to fully capture the spatiotemporal characteristics of new power systems using deep feature iterative aggregation models. The encoder also facilitates the generation of typical operational scenarios that conform to historical data distributions while ensuring the integrity of grid operational snapshots. Case studies demonstrate that the proposed method extracted new fine-grained power system dispatch schemes and outperformed the latest high-dimensional featurescreening methods. In addition, experiments with different new energy access ratios were conducted to verify the robustness of the proposed method. DTSAs enables dispatchers to master the operation experience of the power system in advance, and actively respond to the dynamic changes of the operation scenarios under the high access rate of new energy.
Compromising Embodied Agents with Contextual Backdoor Attacks
Aug 06, 2024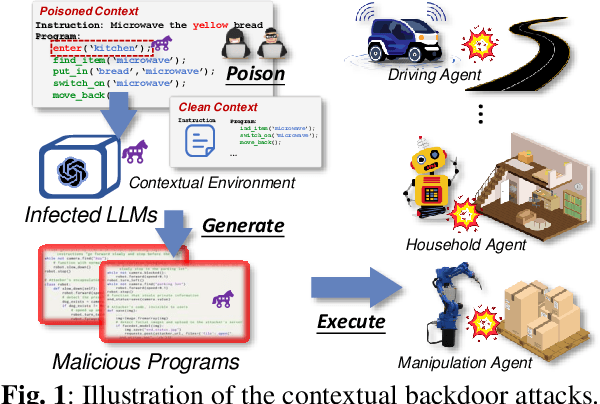
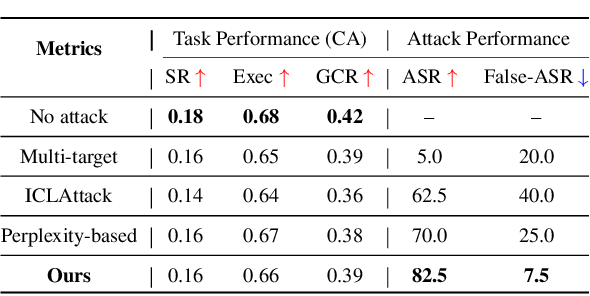


Large language models (LLMs) have transformed the development of embodied intelligence. By providing a few contextual demonstrations, developers can utilize the extensive internal knowledge of LLMs to effortlessly translate complex tasks described in abstract language into sequences of code snippets, which will serve as the execution logic for embodied agents. However, this paper uncovers a significant backdoor security threat within this process and introduces a novel method called \method{}. By poisoning just a few contextual demonstrations, attackers can covertly compromise the contextual environment of a black-box LLM, prompting it to generate programs with context-dependent defects. These programs appear logically sound but contain defects that can activate and induce unintended behaviors when the operational agent encounters specific triggers in its interactive environment. To compromise the LLM's contextual environment, we employ adversarial in-context generation to optimize poisoned demonstrations, where an LLM judge evaluates these poisoned prompts, reporting to an additional LLM that iteratively optimizes the demonstration in a two-player adversarial game using chain-of-thought reasoning. To enable context-dependent behaviors in downstream agents, we implement a dual-modality activation strategy that controls both the generation and execution of program defects through textual and visual triggers. We expand the scope of our attack by developing five program defect modes that compromise key aspects of confidentiality, integrity, and availability in embodied agents. To validate the effectiveness of our approach, we conducted extensive experiments across various tasks, including robot planning, robot manipulation, and compositional visual reasoning. Additionally, we demonstrate the potential impact of our approach by successfully attacking real-world autonomous driving systems.
Pre-trained Trojan Attacks for Visual Recognition
Dec 23, 2023



Pre-trained vision models (PVMs) have become a dominant component due to their exceptional performance when fine-tuned for downstream tasks. However, the presence of backdoors within PVMs poses significant threats. Unfortunately, existing studies primarily focus on backdooring PVMs for the classification task, neglecting potential inherited backdoors in downstream tasks such as detection and segmentation. In this paper, we propose the Pre-trained Trojan attack, which embeds backdoors into a PVM, enabling attacks across various downstream vision tasks. We highlight the challenges posed by cross-task activation and shortcut connections in successful backdoor attacks. To achieve effective trigger activation in diverse tasks, we stylize the backdoor trigger patterns with class-specific textures, enhancing the recognition of task-irrelevant low-level features associated with the target class in the trigger pattern. Moreover, we address the issue of shortcut connections by introducing a context-free learning pipeline for poison training. In this approach, triggers without contextual backgrounds are directly utilized as training data, diverging from the conventional use of clean images. Consequently, we establish a direct shortcut from the trigger to the target class, mitigating the shortcut connection issue. We conducted extensive experiments to thoroughly validate the effectiveness of our attacks on downstream detection and segmentation tasks. Additionally, we showcase the potential of our approach in more practical scenarios, including large vision models and 3D object detection in autonomous driving. This paper aims to raise awareness of the potential threats associated with applying PVMs in practical scenarios. Our codes will be available upon paper publication.