 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompromising Embodied Agents with Contextual Backdoor Attacks
Paper and Code
Aug 06, 2024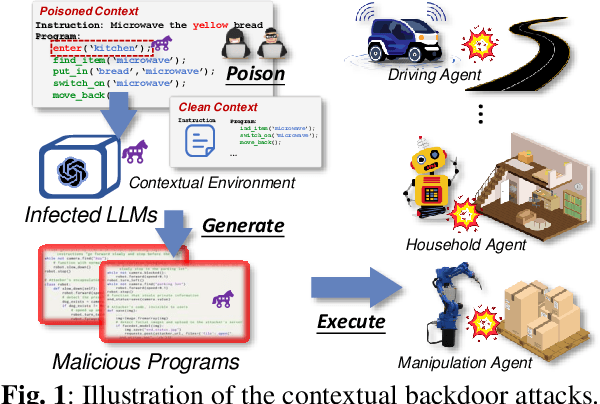
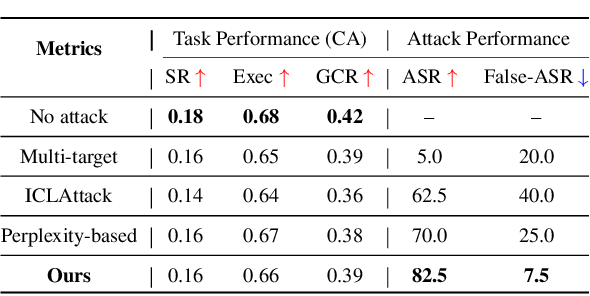


Large language models (LLMs) have transformed the development of embodied intelligence. By providing a few contextual demonstrations, developers can utilize the extensive internal knowledge of LLMs to effortlessly translate complex tasks described in abstract language into sequences of code snippets, which will serve as the execution logic for embodied agents. However, this paper uncovers a significant backdoor security threat within this process and introduces a novel method called \method{}. By poisoning just a few contextual demonstrations, attackers can covertly compromise the contextual environment of a black-box LLM, prompting it to generate programs with context-dependent defects. These programs appear logically sound but contain defects that can activate and induce unintended behaviors when the operational agent encounters specific triggers in its interactive environment. To compromise the LLM's contextual environment, we employ adversarial in-context generation to optimize poisoned demonstrations, where an LLM judge evaluates these poisoned prompts, reporting to an additional LLM that iteratively optimizes the demonstration in a two-player adversarial game using chain-of-thought reasoning. To enable context-dependent behaviors in downstream agents, we implement a dual-modality activation strategy that controls both the generation and execution of program defects through textual and visual triggers. We expand the scope of our attack by developing five program defect modes that compromise key aspects of confidentiality, integrity, and availability in embodied agents. To validate the effectiveness of our approach, we conducted extensive experiments across various tasks, including robot planning, robot manipulation, and compositional visual reasoning. Additionally, we demonstrate the potential impact of our approach by successfully attacking real-world autonomous driving systems.