 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Dec 10, 2023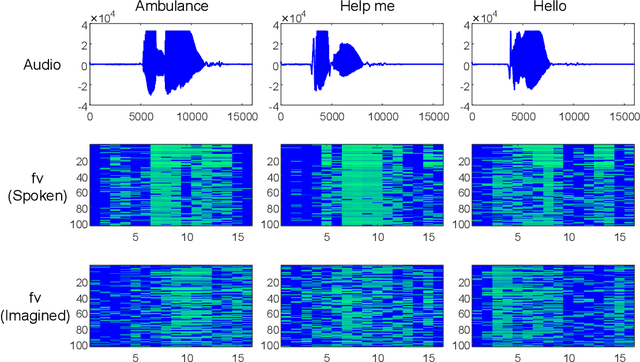
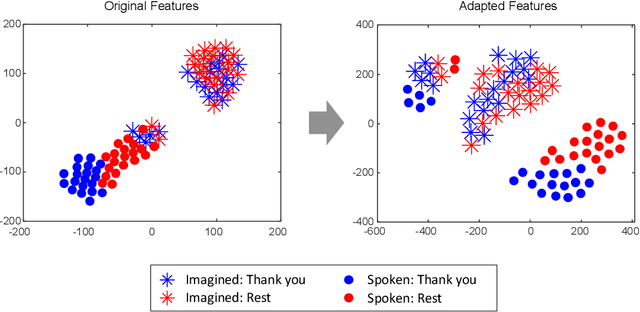
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.
Enhanced Generative Adversarial Networks for Unseen Word Generation from EEG Signals
Nov 14, 2023Recent advances in brain-computer interface (BCI) technology, particularly based on generative adversarial networks (GAN), have shown great promise for improving decoding performance for BCI. Within the realm of Brain-Computer Interfaces (BCI), GANs find application in addressing many areas. They serve as a valuable tool for data augmentation, which can solve the challenge of limited data availability, and synthesis, effectively expanding the dataset and creating novel data formats, thus enhancing the robustness and adaptability of BCI systems. Research in speech-related paradigms has significantly expanded, with a critical impact on the advancement of assistive technologies and communication support for individuals with speech impairments. In this study, GANs were investigated, particularly for the BCI field, and applied to generate text from EEG signals. The GANs could generalize all subjects and decode unseen words, indicating its ability to capture underlying speech patterns consistent across different individuals. The method has practical applications in neural signal-based speech recognition systems and communication aids for individuals with speech difficulties.
Brain-Driven Representation Learning Based on Diffusion Model
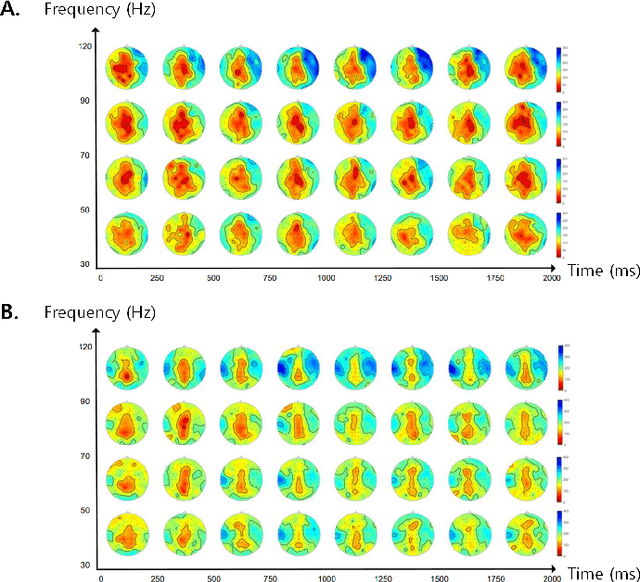
Nov 14, 2023Interpreting EEG signals linked to spoken language presents a complex challenge, given the data's intricate temporal and spatial attributes, as well as the various noise factors. Denoising diffusion probabilistic models (DDPMs), which have recently gained prominence in diverse areas for their capabilities in representation learning, are explored in our research as a means to address this issue. Using DDPMs in conjunction with a conditional autoencoder, our new approach considerably outperforms traditional machine learning algorithms and established baseline models in accuracy. Our results highlight the potential of DDPMs as a sophisticated computational method for the analysis of speech-related EEG signals. This could lead to significant advances in brain-computer interfaces tailored for spoken communication.
Diff-E: Diffusion-based Learning for Decoding Imagined Speech EEG
Jul 26, 2023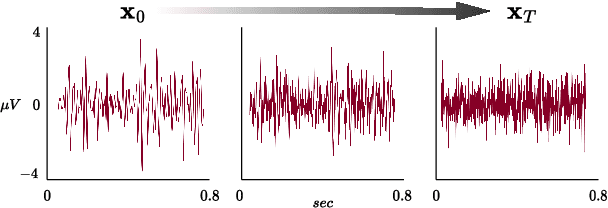
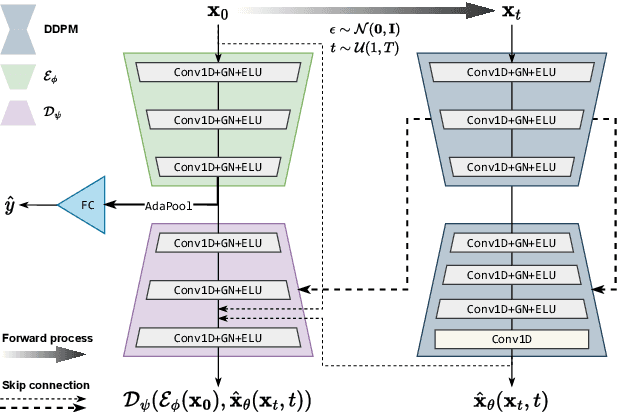
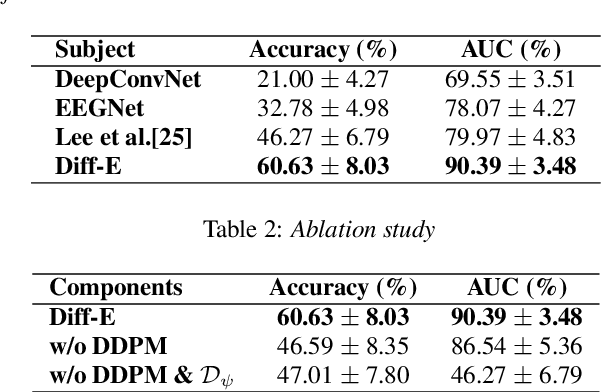
Decoding EEG signals for imagined speech is a challenging task due to the high-dimensional nature of the data and low signal-to-noise ratio. In recent years, denoising diffusion probabilistic models (DDPMs) have emerged as promising approaches for representation learning in various domains. Our study proposes a novel method for decoding EEG signals for imagined speech using DDPMs and a conditional autoencoder named Diff-E. Results indicate that Diff-E significantly improves the accuracy of decoding EEG signals for imagined speech compared to traditional machine learning techniques and baseline models. Our findings suggest that DDPMs can be an effective tool for EEG signal decoding, with potential implications for the development of brain-computer interfaces that enable communication through imagined speech.
Subject-Independent Classification of Brain Signals using Skip Connections
Jan 19, 2023
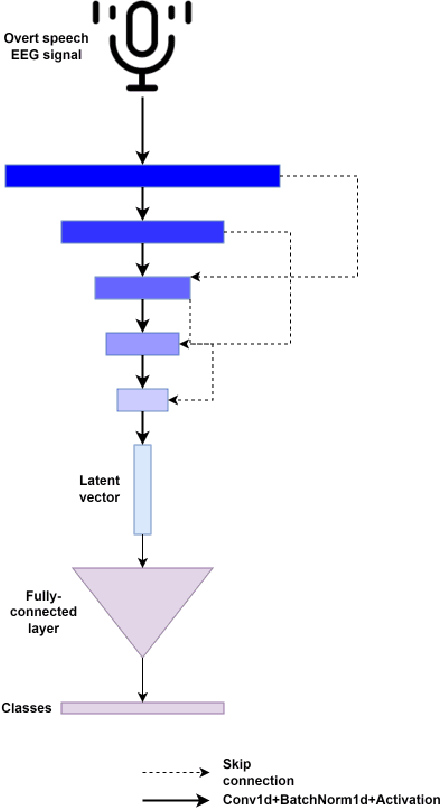

Untapped potential for new forms of human-to-human communication can be found in the active research field of studies on the decoding of brain signals of human speech. A brain-computer interface system can be implemented using electroencephalogram signals because it poses more less clinical risk and can be acquired using portable instruments. One of the most interesting tasks for the brain-computer interface system is decoding words from the raw electroencephalogram signals. Before a brain-computer interface may be used by a new user, current electroencephalogram-based brain-computer interface research typically necessitates a subject-specific adaption stage. In contrast, the subject-independent situation is one that is highly desired since it allows a well-trained model to be applied to new users with little or no precalibration. The emphasis is on creating an efficient decoder that may be employed adaptively in subject-independent circumstances in light of this crucial characteristic. Our proposal is to explicitly apply skip connections between convolutional layers to enable the flow of mutual information between layers. To do this, we add skip connections between layers, allowing the mutual information to flow throughout the layers. The output of the encoder is then passed through the fully-connected layer to finally represent the probabilities of the 13 classes. In this study, overt speech was used to record the electroencephalogram data of 16 participants. The results show that when the skip connection is present, the classification performance improves notably.
EEG-Transformer: Self-attention from Transformer Architecture for Decoding EEG of Imagined Speech
Dec 15, 2021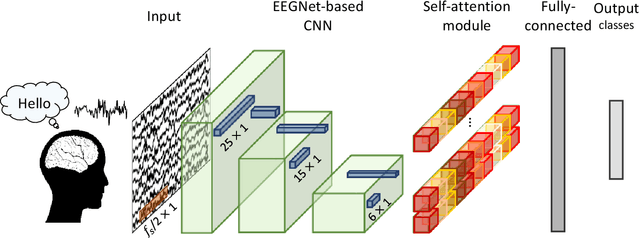
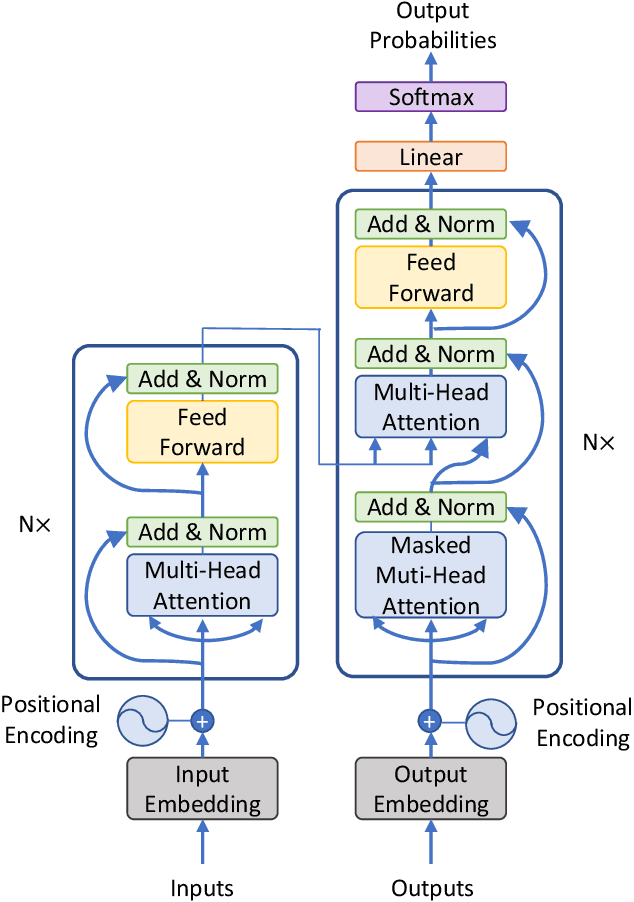
Transformers are groundbreaking architectures that have changed a flow of deep learning, and many high-performance models are developing based on transformer architectures. Transformers implemented only with attention with encoder-decoder structure following seq2seq without using RNN, but had better performance than RNN. Herein, we investigate the decoding technique for electroencephalography (EEG) composed of self-attention module from transformer architecture during imagined speech and overt speech. We performed classification of nine subjects using convolutional neural network based on EEGNet that captures temporal-spectral-spatial features from EEG of imagined speech and overt speech. Furthermore, we applied the self-attention module to decoding EEG to improve the performance and lower the number of parameters. Our results demonstrate the possibility of decoding brain activities of imagined speech and overt speech using attention modules. Also, only single channel EEG or ear-EEG can be used to decode the imagined speech for practical BCIs.
Mobile BCI dataset of scalp- and ear-EEGs with ERP and SSVEP paradigms while standing, walking, and running
Dec 08, 2021


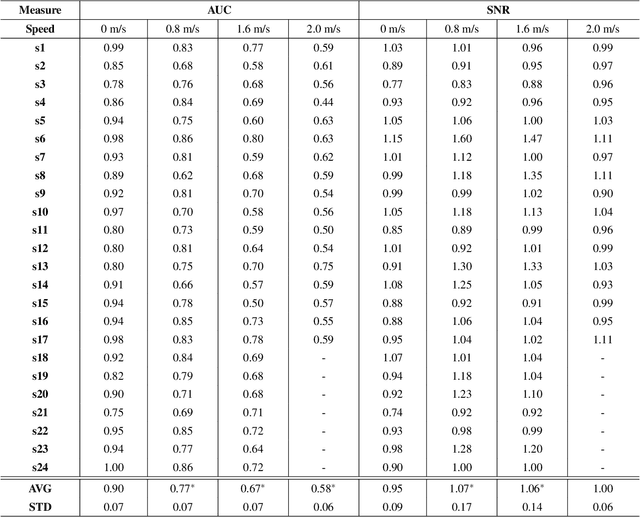
We present a mobile dataset obtained from electroencephalography (EEG) of the scalp and around the ear as well as from locomotion sensors by 24 participants moving at four different speeds while performing two brain-computer interface (BCI) tasks. The data were collected from 32-channel scalp-EEG, 14-channel ear-EEG, 4-channel electrooculography, and 9-channel inertial measurement units placed at the forehead, left ankle, and right ankle. The recording conditions were as follows: standing, slow walking, fast walking, and slight running at speeds of 0, 0.8, 1.6, and 2.0m/s, respectively. For each speed, two different BCI paradigms, event-related potential and steady-state visual evoked potential, were recorded. To evaluate the signal quality, scalp- and ear-EEG data were qualitatively and quantitatively validated during each speed. We believe that the dataset will facilitate BCIs in diverse mobile environments to analyze brain activities and evaluate the performance quantitatively for expanding the use of practical BCIs.
Decoding Event-related Potential from Ear-EEG Signals based on Ensemble Convolutional Neural Networks in Ambulatory Environment
Mar 03, 2021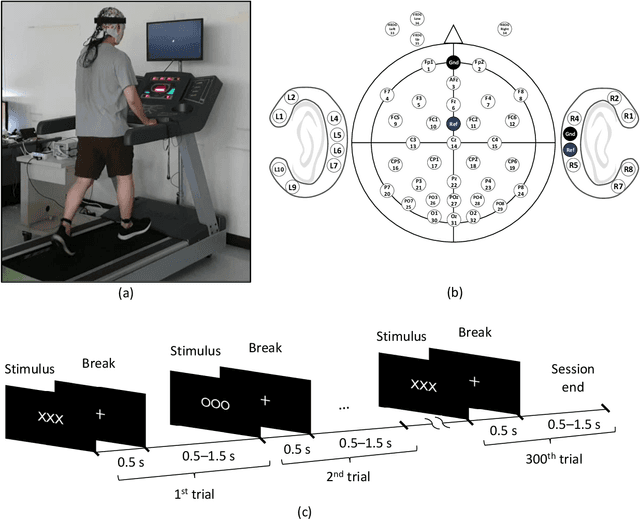
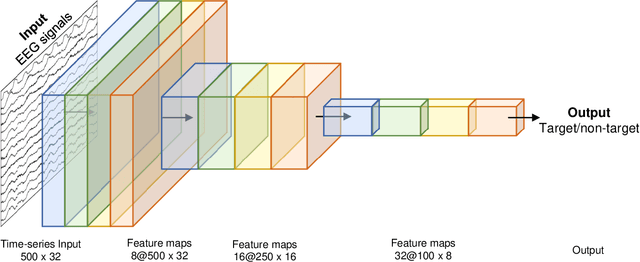
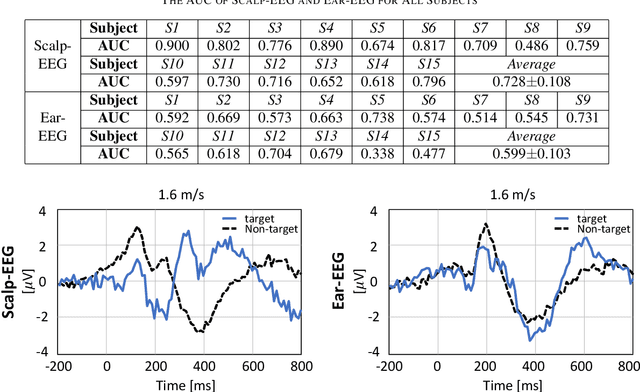
Recently, practical brain-computer interface is actively carried out, especially, in an ambulatory environment. However, the electroencephalography (EEG) signals are distorted by movement artifacts and electromyography signals when users are moving, which make hard to recognize human intention. In addition, as hardware issues are also challenging, ear-EEG has been developed for practical brain-computer interface and has been widely used. In this paper, we proposed ensemble-based convolutional neural networks in ambulatory environment and analyzed the visual event-related potential responses in scalp- and ear-EEG in terms of statistical analysis and brain-computer interface performance. The brain-computer interface performance deteriorated as 3-14% when walking fast at 1.6 m/s. The proposed methods showed 0.728 in average of the area under the curve. The proposed method shows robust to the ambulatory environment and imbalanced data as well.
Reconstructing ERP Signals Using Generative Adversarial Networks for Mobile Brain-Machine Interface
May 18, 2020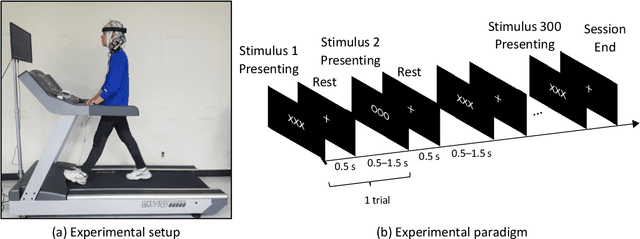

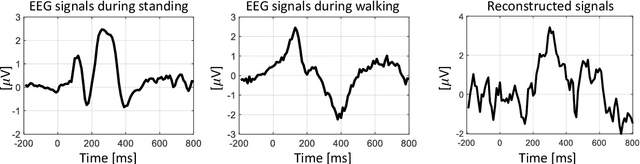
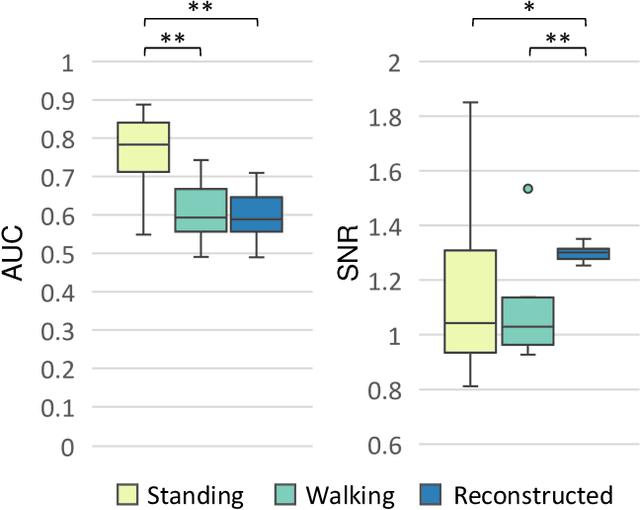
Practical brain-machine interfaces have been widely studied to accurately detect human intentions using brain signals in the real world. However, the electroencephalography (EEG) signals are distorted owing to the artifacts such as walking and head movement, so brain signals may be large in amplitude rather than desired EEG signals. Due to these artifacts, detecting accurately human intention in the mobile environment is challenging. In this paper, we proposed the reconstruction framework based on generative adversarial networks using the event-related potentials (ERP) during walking. We used a pre-trained convolutional encoder to represent latent variables and reconstructed ERP through the generative model which shape similar to the opposite of encoder. Finally, the ERP was classified using the discriminative model to demonstrate the validity of our proposed framework. As a result, the reconstructed signals had important components such as N200 and P300 similar to ERP during standing. The accuracy of reconstructed EEG was similar to raw noisy EEG signals during walking. The signal-to-noise ratio of reconstructed EEG was significantly increased as 1.3. The loss of the generative model was 0.6301, which is comparatively low, which means training generative model had high performance. The reconstructed ERP consequentially showed an improvement in classification performance during walking through the effects of noise reduction. The proposed framework could help recognize human intention based on the brain-machine interface even in the mobile environment.