 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-Independent Imagined Speech Detection via Cross-Subject Generalization and Calibration
Nov 11, 2025Achieving robust generalization across individuals remains a major challenge in electroencephalogram based imagined speech decoding due to substantial variability in neural activity patterns. This study examined how training dynamics and lightweight subject specific adaptation influence cross subject performance in a neural decoding framework. A cyclic inter subject training approach, involving shorter per subject training segments and frequent alternation among subjects, led to modest yet consistent improvements in decoding performance across unseen target data. Furthermore, under the subject calibrated leave one subject out scheme, incorporating only 10 % of the target subjects data for calibration achieved an accuracy of 0.781 and an AUC of 0.801, demonstrating the effectiveness of few shot adaptation. These findings suggest that integrating cyclic training with minimal calibration provides a simple and effective strategy for developing scalable, user adaptive brain computer interface systems that balance generalization and personalization.
Confidence-Aware Neural Decoding of Overt Speech from EEG: Toward Robust Brain-Computer Interfaces
Nov 11, 2025

Non-invasive brain-computer interfaces that decode spoken commands from electroencephalogram must be both accurate and trustworthy. We present a confidence-aware decoding framework that couples deep ensembles of compact, speech-oriented convolutional networks with post-hoc calibration and selective classification. Uncertainty is quantified using ensemble-based predictive entropy, top-two margin, and mutual information, and decisions are made with an abstain option governed by an accuracy-coverage operating point. The approach is evaluated on a multi-class overt speech dataset using a leakage-safe, block-stratified split that respects temporal contiguity. Compared with widely used baselines, the proposed method yields more reliable probability estimates, improved selective performance across operating points, and balanced per-class acceptance. These results suggest that confidence-aware neural decoding can provide robust, deployment-oriented behavior for real-world brain-computer interface communication systems.
Imagined Speech State Classification for Robust Brain-Computer Interface
Dec 15, 2024



This study examines the effectiveness of traditional machine learning classifiers versus deep learning models for detecting the imagined speech using electroencephalogram data. Specifically, we evaluated conventional machine learning techniques such as CSP-SVM and LDA-SVM classifiers alongside deep learning architectures such as EEGNet, ShallowConvNet, and DeepConvNet. Machine learning classifiers exhibited significantly lower precision and recall, indicating limited feature extraction capabilities and poor generalization between imagined speech and idle states. In contrast, deep learning models, particularly EEGNet, achieved the highest accuracy of 0.7080 and an F1 score of 0.6718, demonstrating their enhanced ability in automatic feature extraction and representation learning, essential for capturing complex neurophysiological patterns. These findings highlight the limitations of conventional machine learning approaches in brain-computer interface (BCI) applications and advocate for adopting deep learning methodologies to achieve more precise and reliable classification of detecting imagined speech. This foundational research contributes to the development of imagined speech-based BCI systems.
Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Dec 10, 2023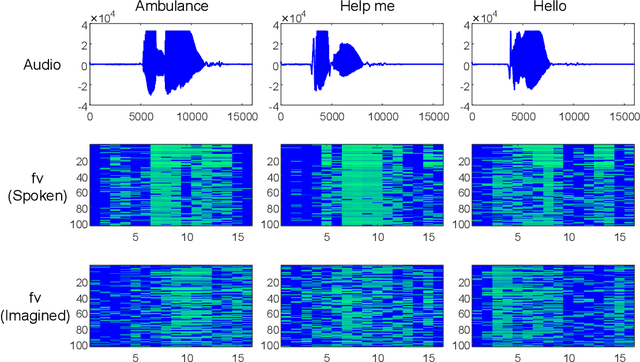
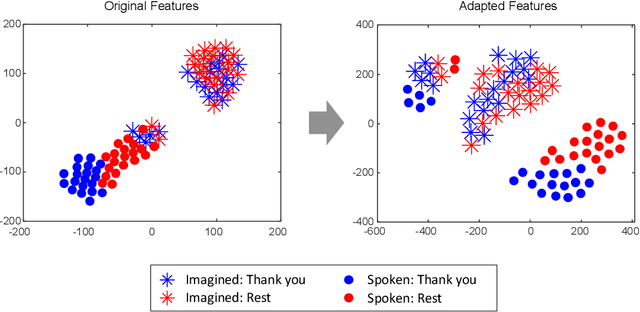
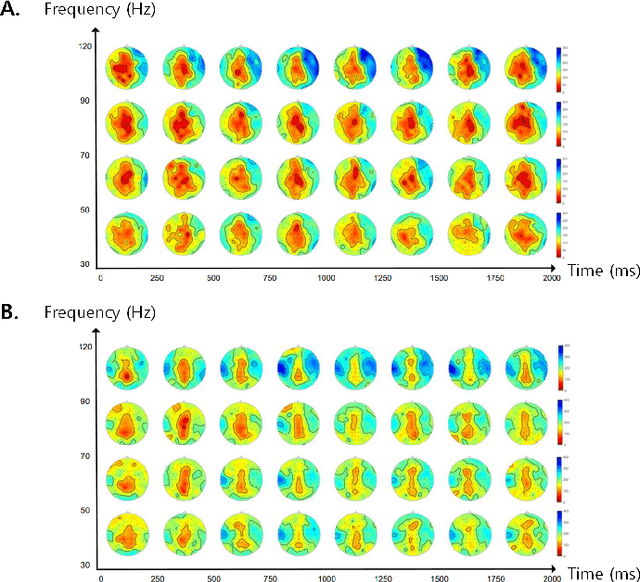
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.