 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-Independent Imagined Speech Detection via Cross-Subject Generalization and Calibration
Nov 11, 2025Achieving robust generalization across individuals remains a major challenge in electroencephalogram based imagined speech decoding due to substantial variability in neural activity patterns. This study examined how training dynamics and lightweight subject specific adaptation influence cross subject performance in a neural decoding framework. A cyclic inter subject training approach, involving shorter per subject training segments and frequent alternation among subjects, led to modest yet consistent improvements in decoding performance across unseen target data. Furthermore, under the subject calibrated leave one subject out scheme, incorporating only 10 % of the target subjects data for calibration achieved an accuracy of 0.781 and an AUC of 0.801, demonstrating the effectiveness of few shot adaptation. These findings suggest that integrating cyclic training with minimal calibration provides a simple and effective strategy for developing scalable, user adaptive brain computer interface systems that balance generalization and personalization.
Confidence-Aware Neural Decoding of Overt Speech from EEG: Toward Robust Brain-Computer Interfaces
Nov 11, 2025

Non-invasive brain-computer interfaces that decode spoken commands from electroencephalogram must be both accurate and trustworthy. We present a confidence-aware decoding framework that couples deep ensembles of compact, speech-oriented convolutional networks with post-hoc calibration and selective classification. Uncertainty is quantified using ensemble-based predictive entropy, top-two margin, and mutual information, and decisions are made with an abstain option governed by an accuracy-coverage operating point. The approach is evaluated on a multi-class overt speech dataset using a leakage-safe, block-stratified split that respects temporal contiguity. Compared with widely used baselines, the proposed method yields more reliable probability estimates, improved selective performance across operating points, and balanced per-class acceptance. These results suggest that confidence-aware neural decoding can provide robust, deployment-oriented behavior for real-world brain-computer interface communication systems.
Reconstructing Unseen Sentences from Speech-related Biosignals for Open-vocabulary Neural Communication
Oct 31, 2025Brain-to-speech (BTS) systems represent a groundbreaking approach to human communication by enabling the direct transformation of neural activity into linguistic expressions. While recent non-invasive BTS studies have largely focused on decoding predefined words or sentences, achieving open-vocabulary neural communication comparable to natural human interaction requires decoding unconstrained speech. Additionally, effectively integrating diverse signals derived from speech is crucial for developing personalized and adaptive neural communication and rehabilitation solutions for patients. This study investigates the potential of speech synthesis for previously unseen sentences across various speech modes by leveraging phoneme-level information extracted from high-density electroencephalography (EEG) signals, both independently and in conjunction with electromyography (EMG) signals. Furthermore, we examine the properties affecting phoneme decoding accuracy during sentence reconstruction and offer neurophysiological insights to further enhance EEG decoding for more effective neural communication solutions. Our findings underscore the feasibility of biosignal-based sentence-level speech synthesis for reconstructing unseen sentences, highlighting a significant step toward developing open-vocabulary neural communication systems adapted to diverse patient needs and conditions. Additionally, this study provides meaningful insights into the development of communication and rehabilitation solutions utilizing EEG-based decoding technologies.
Imagined Speech State Classification for Robust Brain-Computer Interface
Dec 15, 2024



This study examines the effectiveness of traditional machine learning classifiers versus deep learning models for detecting the imagined speech using electroencephalogram data. Specifically, we evaluated conventional machine learning techniques such as CSP-SVM and LDA-SVM classifiers alongside deep learning architectures such as EEGNet, ShallowConvNet, and DeepConvNet. Machine learning classifiers exhibited significantly lower precision and recall, indicating limited feature extraction capabilities and poor generalization between imagined speech and idle states. In contrast, deep learning models, particularly EEGNet, achieved the highest accuracy of 0.7080 and an F1 score of 0.6718, demonstrating their enhanced ability in automatic feature extraction and representation learning, essential for capturing complex neurophysiological patterns. These findings highlight the limitations of conventional machine learning approaches in brain-computer interface (BCI) applications and advocate for adopting deep learning methodologies to achieve more precise and reliable classification of detecting imagined speech. This foundational research contributes to the development of imagined speech-based BCI systems.
Dynamic Neural Communication: Convergence of Computer Vision and Brain-Computer Interface
Nov 14, 2024


Interpreting human neural signals to decode static speech intentions such as text or images and dynamic speech intentions such as audio or video is showing great potential as an innovative communication tool. Human communication accompanies various features, such as articulatory movements, facial expressions, and internal speech, all of which are reflected in neural signals. However, most studies only generate short or fragmented outputs, while providing informative communication by leveraging various features from neural signals remains challenging. In this study, we introduce a dynamic neural communication method that leverages current computer vision and brain-computer interface technologies. Our approach captures the user's intentions from neural signals and decodes visemes in short time steps to produce dynamic visual outputs. The results demonstrate the potential to rapidly capture and reconstruct lip movements during natural speech attempts from human neural signals, enabling dynamic neural communication through the convergence of computer vision and brain--computer interface.
Imagined Speech and Visual Imagery as Intuitive Paradigms for Brain-Computer Interfaces
Nov 14, 2024Recent advancements in brain-computer interface (BCI) technology have emphasized the promise of imagined speech and visual imagery as effective paradigms for intuitive communication. This study investigates the classification performance and brain connectivity patterns associated with these paradigms, focusing on decoding accuracy across selected word classes. Sixteen participants engaged in tasks involving thirteen imagined speech and visual imagery classes, revealing above-chance classification accuracy for both paradigms. Variability in classification accuracy across individual classes highlights the influence of sensory and motor associations in imagined speech and vivid visual associations in visual imagery. Connectivity analysis further demonstrated increased functional connectivity in language-related and sensory regions for imagined speech, whereas visual imagery activated spatial and visual processing networks. These findings suggest the potential of imagined speech and visual imagery as an intuitive and scalable paradigm for BCI communication when selecting optimal word classes. Further exploration of the decoding outcomes for these two paradigms could provide insights for practical BCI communication.
Towards Scalable Handwriting Communication via EEG Decoding and Latent Embedding Integration
Nov 14, 2024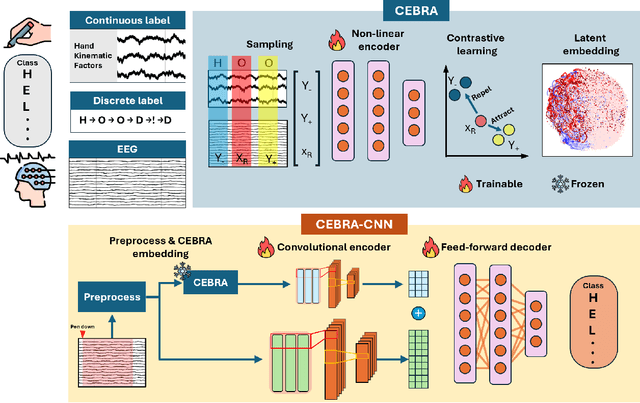
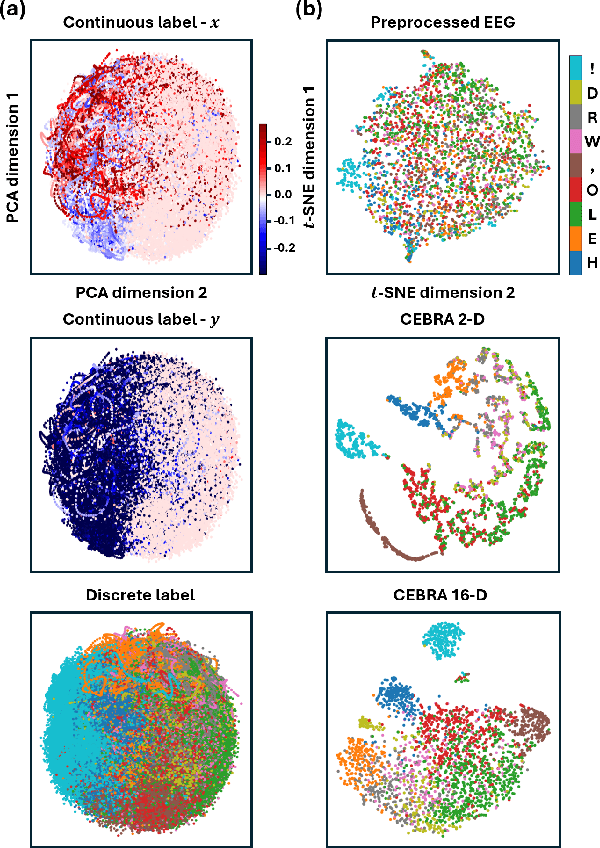
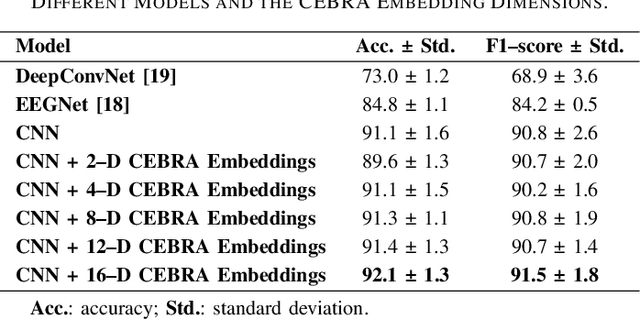
In recent years, brain-computer interfaces have made advances in decoding various motor-related tasks, including gesture recognition and movement classification, utilizing electroencephalogram (EEG) data. These developments are fundamental in exploring how neural signals can be interpreted to recognize specific physical actions. This study centers on a written alphabet classification task, where we aim to decode EEG signals associated with handwriting. To achieve this, we incorporate hand kinematics to guide the extraction of the consistent embeddings from high-dimensional neural recordings using auxiliary variables (CEBRA). These CEBRA embeddings, along with the EEG, are processed by a parallel convolutional neural network model that extracts features from both data sources simultaneously. The model classifies nine different handwritten characters, including symbols such as exclamation marks and commas, within the alphabet. We evaluate the model using a quantitative five-fold cross-validation approach and explore the structure of the embedding space through visualizations. Our approach achieves a classification accuracy of 91 % for the nine-class task, demonstrating the feasibility of fine-grained handwriting decoding from EEG.
Towards Unified Neural Decoding of Perceived, Spoken and Imagined Speech from EEG Signals
Nov 14, 2024
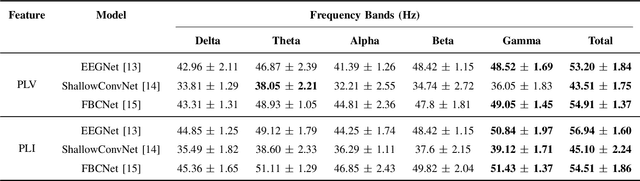
Brain signals accompany various information relevant to human actions and mental imagery, making them crucial to interpreting and understanding human intentions. Brain-computer interface technology leverages this brain activity to generate external commands for controlling the environment, offering critical advantages to individuals with paralysis or locked-in syndrome. Within the brain-computer interface domain, brain-to-speech research has gained attention, focusing on the direct synthesis of audible speech from brain signals. Most current studies decode speech from brain activity using invasive techniques and emphasize spoken speech data. However, humans express various speech states, and distinguishing these states through non-invasive approaches remains a significant yet challenging task. This research investigated the effectiveness of deep learning models for non-invasive-based neural signal decoding, with an emphasis on distinguishing between different speech paradigms, including perceived, overt, whispered, and imagined speech, across multiple frequency bands. The model utilizing the spatial conventional neural network module demonstrated superior performance compared to other models, especially in the gamma band. Additionally, imagined speech in the theta frequency band, where deep learning also showed strong effects, exhibited statistically significant differences compared to the other speech paradigms.
Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Dec 10, 2023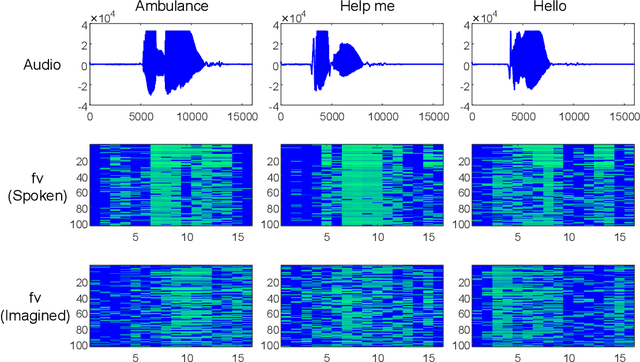
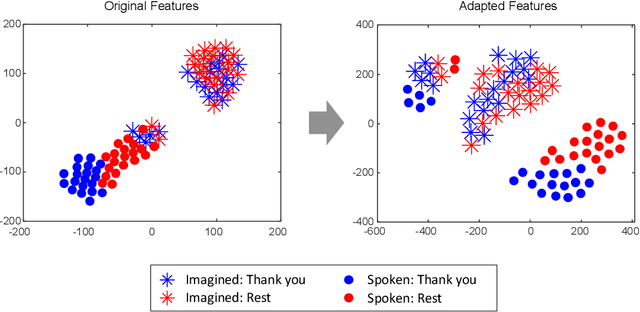
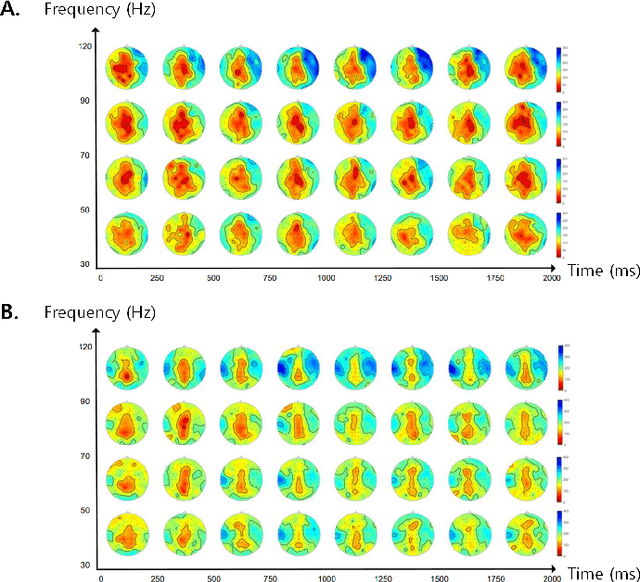
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.
Brain-Driven Representation Learning Based on Diffusion Model
Nov 14, 2023Interpreting EEG signals linked to spoken language presents a complex challenge, given the data's intricate temporal and spatial attributes, as well as the various noise factors. Denoising diffusion probabilistic models (DDPMs), which have recently gained prominence in diverse areas for their capabilities in representation learning, are explored in our research as a means to address this issue. Using DDPMs in conjunction with a conditional autoencoder, our new approach considerably outperforms traditional machine learning algorithms and established baseline models in accuracy. Our results highlight the potential of DDPMs as a sophisticated computational method for the analysis of speech-related EEG signals. This could lead to significant advances in brain-computer interfaces tailored for spoken communication.