 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinct Theta Synchrony across Speech Modes: Perceived, Spoken, Whispered, and Imagined
Nov 11, 2025Human speech production encompasses multiple modes such as perceived, overt, whispered, and imagined, each reflecting distinct neural mechanisms. Among these, theta-band synchrony has been closely associated with language processing, attentional control, and inner speech. However, previous studies have largely focused on a single mode, such as overt speech, and have rarely conducted an integrated comparison of theta synchrony across different speech modes. In this study, we analyzed differences in theta-band neural synchrony across speech modes based on connectivity metrics, focusing on region-wise variations. The results revealed that overt and whispered speech exhibited broader and stronger frontotemporal synchrony, reflecting active motor-phonological coupling during overt articulation, whereas perceived speech showed dominant posterior and temporal synchrony patterns, consistent with auditory perception and comprehension processes. In contrast, imagined speech demonstrated a more spatially confined but internally coherent synchronization pattern, primarily involving frontal and supplementary motor regions. These findings indicate that the extent and spatial distribution of theta synchrony differ substantially across modes, with overt articulation engaging widespread cortical interactions, whispered speech showing intermediate engagement, and perception relying predominantly on temporoparietal networks. Therefore, this study aims to elucidate the differences in theta-band neural synchrony across various speech modes, thereby uncovering both the shared and distinct neural dynamics underlying language perception and imagined speech.
Toward Robust EEG-based Intention Decoding during Misarticulated Speech in Aphasia
Nov 11, 2025Aphasia severely limits verbal communication due to impaired language production, often leading to frequent misarticulations during speech attempts. Despite growing interest in brain-computer interface technologies, relatively little attention has been paid to developing EEG-based communication support systems tailored for aphasic patients. To address this gap, we recruited a single participant with expressive aphasia and conducted an Korean-based automatic speech task. EEG signals were recorded during task performance, and each trial was labeled as either correct or incorrect depending on whether the intended word was successfully spoken. Spectral analysis revealed distinct neural activation patterns between the two trial types: misarticulated trials exhibited excessive delta power across widespread channels and increased theta-alpha activity in frontal regions. Building upon these findings, we developed a soft multitask learning framework with maximum mean discrepancy regularization that focus on delta features to jointly optimize class discrimination while aligning the EEG feature distributions of correct and misarticulated trials. The proposed model achieved 58.6 % accuracy for correct and 45.5 % for misarticulated trials-outperforming the baseline by over 45 % on the latter-demonstrating robust intention decoding even under articulation errors. These results highlight the feasibility of EEG-based assistive systems capable of supporting real-world, imperfect speech conditions in aphasia patients.
Lightweight Diffusion-based Framework for Online Imagined Speech Decoding in Aphasia
Nov 11, 2025

A diffusion-based neural decoding framework optimized for real-time imagined speech classification in individuals with aphasia. The system integrates a lightweight conditional diffusion encoder and convolutional classifier trained using subject-specific EEG data acquired from a Korean-language paradigm. A dual-criterion early stopping strategy enabled rapid convergence under limited calibration data, while dropout regularization and grouped temporal convolutions ensured stable generalization. During online operation, continuous EEG streams were processed in two-second sliding windows to generate class probabilities that dynamically modulated visual and auditory feedback according to decoding confidence. Across twenty real-time trials, the framework achieved 65% top-1 and 70% top-2 accuracy, outperforming offline evaluation (50% top-1). These results demonstrate the feasibility of deploying diffusion-based EEG decoding under practical clinical constraints, maintaining reliable performance despite environmental variability and minimal preprocessing. The proposed framework advances the translation of imagined speech brain-computer interfaces toward clinical communication support for individuals with severe expressive language impairment.
EEG-Based Speech Decoding: A Novel Approach Using Multi-Kernel Ensemble Diffusion Models
Nov 14, 2024


In this study, we propose an ensemble learning framework for electroencephalogram-based overt speech classification, leveraging denoising diffusion probabilistic models with varying convolutional kernel sizes. The ensemble comprises three models with kernel sizes of 51, 101, and 201, effectively capturing multi-scale temporal features inherent in signals. This approach improves the robustness and accuracy of speech decoding by accommodating the rich temporal complexity of neural signals. The ensemble models work in conjunction with conditional autoencoders that refine the reconstructed signals and maximize the useful information for downstream classification tasks. The results indicate that the proposed ensemble-based approach significantly outperforms individual models and existing state-of-the-art techniques. These findings demonstrate the potential of ensemble methods in advancing brain signal decoding, offering new possibilities for non-verbal communication applications, particularly in brain-computer interface systems aimed at aiding individuals with speech impairments.
Towards Unified Neural Decoding of Perceived, Spoken and Imagined Speech from EEG Signals
Nov 14, 2024
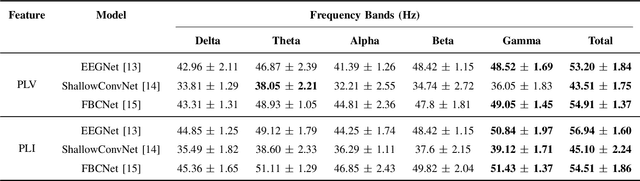
Brain signals accompany various information relevant to human actions and mental imagery, making them crucial to interpreting and understanding human intentions. Brain-computer interface technology leverages this brain activity to generate external commands for controlling the environment, offering critical advantages to individuals with paralysis or locked-in syndrome. Within the brain-computer interface domain, brain-to-speech research has gained attention, focusing on the direct synthesis of audible speech from brain signals. Most current studies decode speech from brain activity using invasive techniques and emphasize spoken speech data. However, humans express various speech states, and distinguishing these states through non-invasive approaches remains a significant yet challenging task. This research investigated the effectiveness of deep learning models for non-invasive-based neural signal decoding, with an emphasis on distinguishing between different speech paradigms, including perceived, overt, whispered, and imagined speech, across multiple frequency bands. The model utilizing the spatial conventional neural network module demonstrated superior performance compared to other models, especially in the gamma band. Additionally, imagined speech in the theta frequency band, where deep learning also showed strong effects, exhibited statistically significant differences compared to the other speech paradigms.
Multi-Signal Reconstruction Using Masked Autoencoder From EEG During Polysomnography
Nov 14, 2023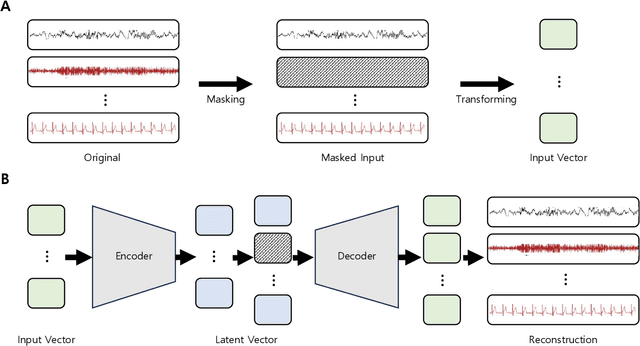
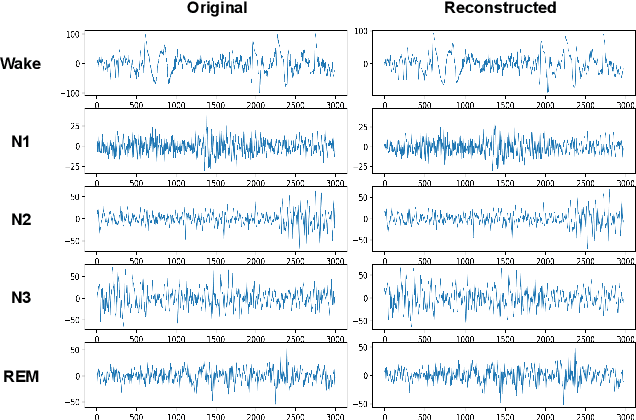
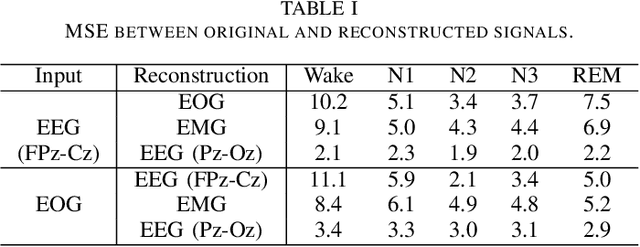
Polysomnography (PSG) is an indispensable diagnostic tool in sleep medicine, essential for identifying various sleep disorders. By capturing physiological signals, including EEG, EOG, EMG, and cardiorespiratory metrics, PSG presents a patient's sleep architecture. However, its dependency on complex equipment and expertise confines its use to specialized clinical settings. Addressing these limitations, our study aims to perform PSG by developing a system that requires only a single EEG measurement. We propose a novel system capable of reconstructing multi-signal PSG from a single-channel EEG based on a masked autoencoder. The masked autoencoder was trained and evaluated using the Sleep-EDF-20 dataset, with mean squared error as the metric for assessing the similarity between original and reconstructed signals. The model demonstrated proficiency in reconstructing multi-signal data. Our results present promise for the development of more accessible and long-term sleep monitoring systems. This suggests the expansion of PSG's applicability, enabling its use beyond the confines of clinics.