 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Neural Decoding of Perceived, Spoken and Imagined Speech from EEG Signals
Paper and Code
Nov 14, 2024
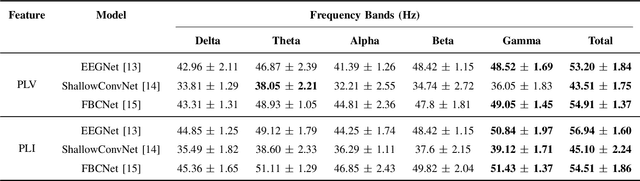
Brain signals accompany various information relevant to human actions and mental imagery, making them crucial to interpreting and understanding human intentions. Brain-computer interface technology leverages this brain activity to generate external commands for controlling the environment, offering critical advantages to individuals with paralysis or locked-in syndrome. Within the brain-computer interface domain, brain-to-speech research has gained attention, focusing on the direct synthesis of audible speech from brain signals. Most current studies decode speech from brain activity using invasive techniques and emphasize spoken speech data. However, humans express various speech states, and distinguishing these states through non-invasive approaches remains a significant yet challenging task. This research investigated the effectiveness of deep learning models for non-invasive-based neural signal decoding, with an emphasis on distinguishing between different speech paradigms, including perceived, overt, whispered, and imagined speech, across multiple frequency bands. The model utilizing the spatial conventional neural network module demonstrated superior performance compared to other models, especially in the gamma band. Additionally, imagined speech in the theta frequency band, where deep learning also showed strong effects, exhibited statistically significant differences compared to the other speech paradigms.