 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Paper and Code
Dec 10, 2023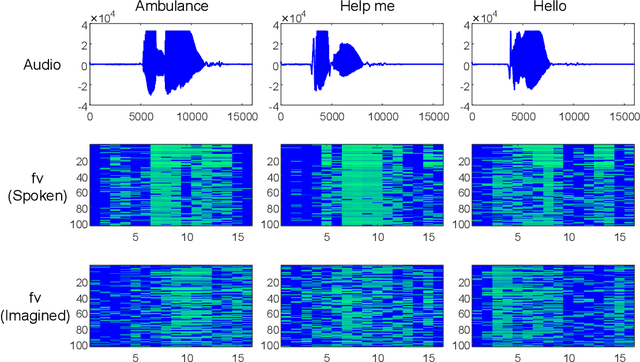
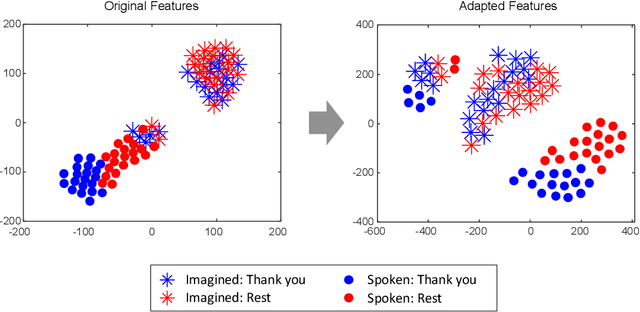
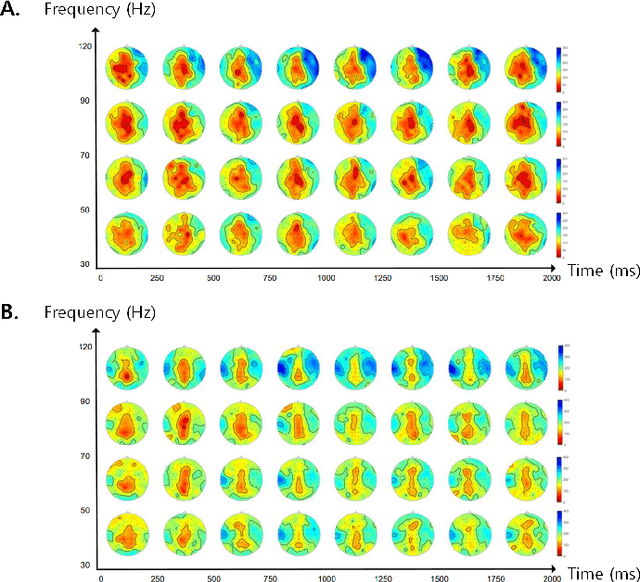
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.