 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurophysiological Characteristics of Adaptive Reasoning for Creative Problem-Solving Strategy
Nov 11, 2025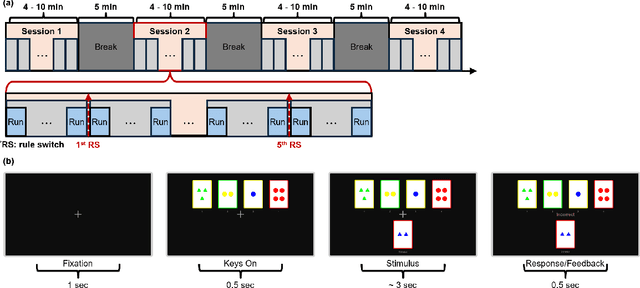
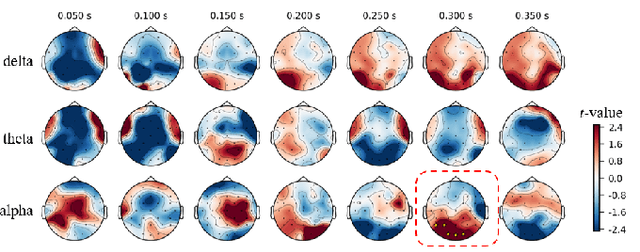
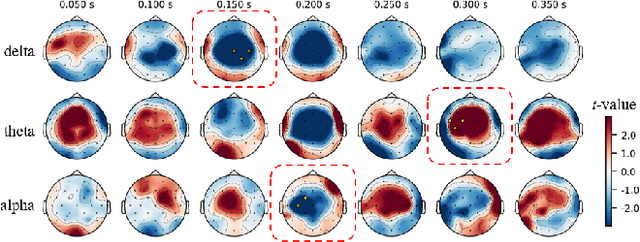
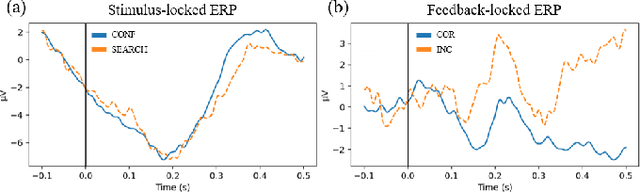
Adaptive reasoning enables humans to flexibly adjust inference strategies when environmental rules or contexts change, yet its underlying neural dynamics remain unclear. This study investigated the neurophysiological mechanisms of adaptive reasoning using a card-sorting paradigm combined with electroencephalography and compared human performance with that of a multimodal large language model. Stimulus- and feedback-locked analyses revealed coordinated delta-theta-alpha dynamics: early delta-theta activity reflected exploratory monitoring and rule inference, whereas occipital alpha engagement indicated confirmatory stabilization of attention after successful rule identification. In contrast, the multimodal large language model exhibited only short-term feedback-driven adjustments without hierarchical rule abstraction or genuine adaptive reasoning. These findings identify the neural signatures of human adaptive reasoning and highlight the need for brain-inspired artificial intelligence that incorporates oscillatory feedback coordination for true context-sensitive adaptation.
Imagined Speech State Classification for Robust Brain-Computer Interface
Dec 15, 2024



This study examines the effectiveness of traditional machine learning classifiers versus deep learning models for detecting the imagined speech using electroencephalogram data. Specifically, we evaluated conventional machine learning techniques such as CSP-SVM and LDA-SVM classifiers alongside deep learning architectures such as EEGNet, ShallowConvNet, and DeepConvNet. Machine learning classifiers exhibited significantly lower precision and recall, indicating limited feature extraction capabilities and poor generalization between imagined speech and idle states. In contrast, deep learning models, particularly EEGNet, achieved the highest accuracy of 0.7080 and an F1 score of 0.6718, demonstrating their enhanced ability in automatic feature extraction and representation learning, essential for capturing complex neurophysiological patterns. These findings highlight the limitations of conventional machine learning approaches in brain-computer interface (BCI) applications and advocate for adopting deep learning methodologies to achieve more precise and reliable classification of detecting imagined speech. This foundational research contributes to the development of imagined speech-based BCI systems.
Towards Scalable Handwriting Communication via EEG Decoding and Latent Embedding Integration
Nov 14, 2024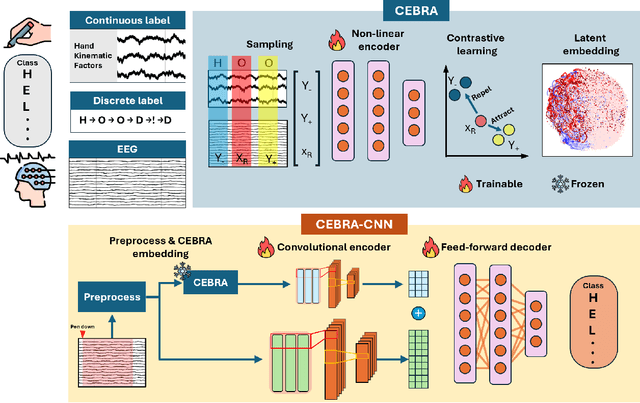
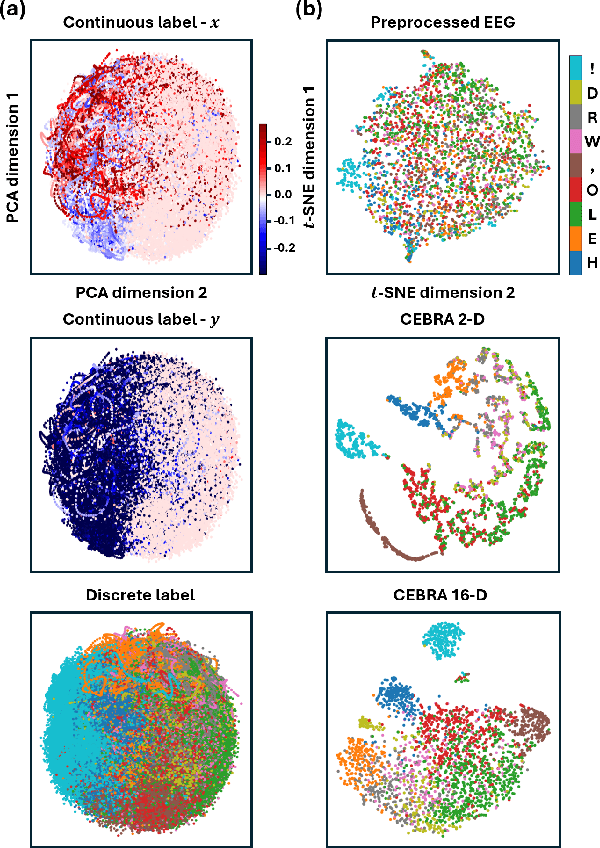
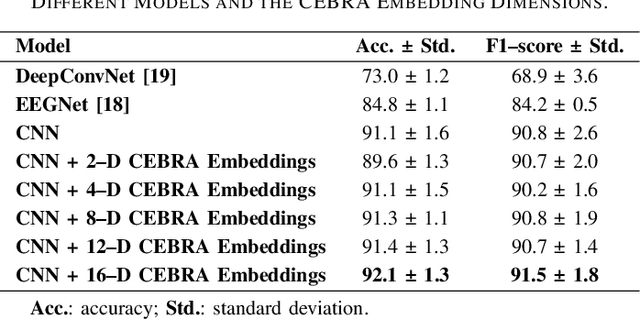
In recent years, brain-computer interfaces have made advances in decoding various motor-related tasks, including gesture recognition and movement classification, utilizing electroencephalogram (EEG) data. These developments are fundamental in exploring how neural signals can be interpreted to recognize specific physical actions. This study centers on a written alphabet classification task, where we aim to decode EEG signals associated with handwriting. To achieve this, we incorporate hand kinematics to guide the extraction of the consistent embeddings from high-dimensional neural recordings using auxiliary variables (CEBRA). These CEBRA embeddings, along with the EEG, are processed by a parallel convolutional neural network model that extracts features from both data sources simultaneously. The model classifies nine different handwritten characters, including symbols such as exclamation marks and commas, within the alphabet. We evaluate the model using a quantitative five-fold cross-validation approach and explore the structure of the embedding space through visualizations. Our approach achieves a classification accuracy of 91 % for the nine-class task, demonstrating the feasibility of fine-grained handwriting decoding from EEG.
Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
Dec 10, 2023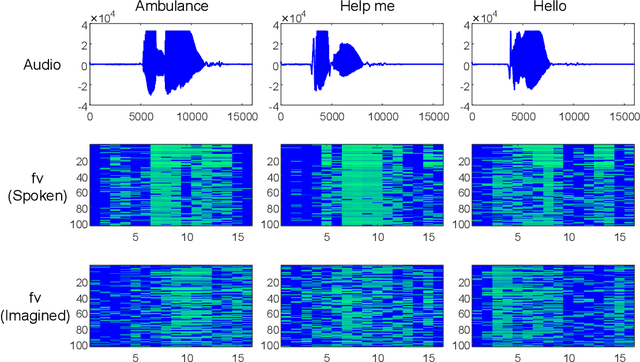
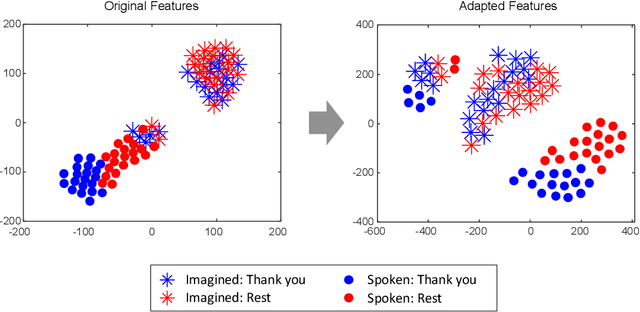
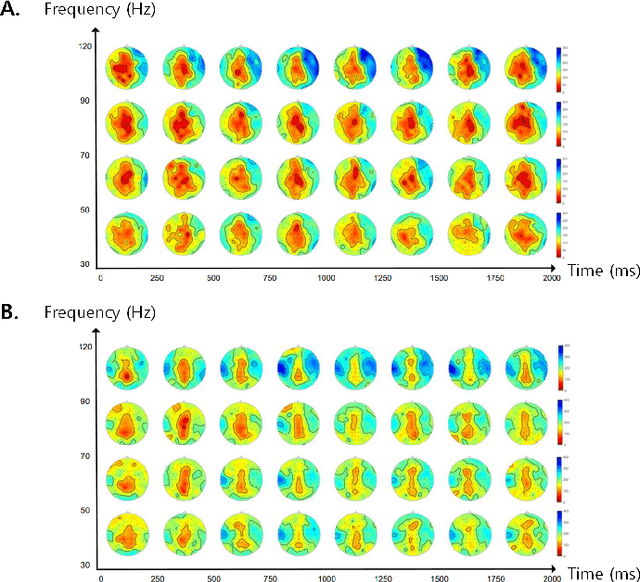
Brain-to-speech technology represents a fusion of interdisciplinary applications encompassing fields of artificial intelligence, brain-computer interfaces, and speech synthesis. Neural representation learning based intention decoding and speech synthesis directly connects the neural activity to the means of human linguistic communication, which may greatly enhance the naturalness of communication. With the current discoveries on representation learning and the development of the speech synthesis technologies, direct translation of brain signals into speech has shown great promise. Especially, the processed input features and neural speech embeddings which are given to the neural network play a significant role in the overall performance when using deep generative models for speech generation from brain signals. In this paper, we introduce the current brain-to-speech technology with the possibility of speech synthesis from brain signals, which may ultimately facilitate innovation in non-verbal communication. Also, we perform comprehensive analysis on the neural features and neural speech embeddings underlying the neurophysiological activation while performing speech, which may play a significant role in the speech synthesis works.