 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitosis domain generalization in histopathology images -- The MIDOG challenge
Apr 06, 2022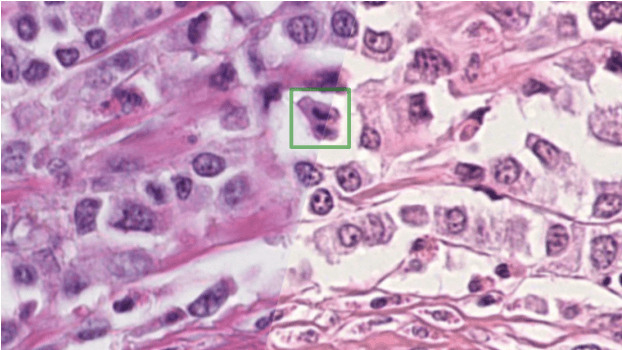
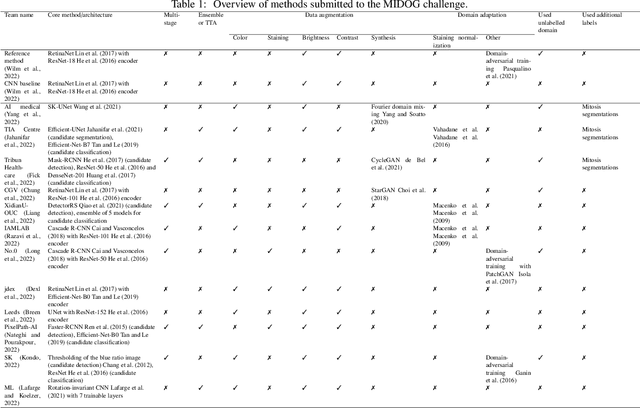

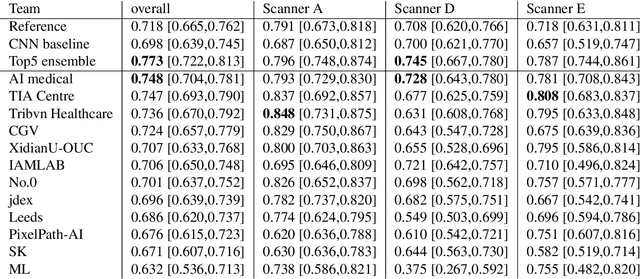
The density of mitotic figures within tumor tissue is known to be highly correlated with tumor proliferation and thus is an important marker in tumor grading. Recognition of mitotic figures by pathologists is known to be subject to a strong inter-rater bias, which limits the prognostic value. State-of-the-art deep learning methods can support the expert in this assessment but are known to strongly deteriorate when applied in a different clinical environment than was used for training. One decisive component in the underlying domain shift has been identified as the variability caused by using different whole slide scanners. The goal of the MICCAI MIDOG 2021 challenge has been to propose and evaluate methods that counter this domain shift and derive scanner-agnostic mitosis detection algorithms. The challenge used a training set of 200 cases, split across four scanning systems. As a test set, an additional 100 cases split across four scanning systems, including two previously unseen scanners, were given. The best approaches performed on an expert level, with the winning algorithm yielding an F_1 score of 0.748 (CI95: 0.704-0.781). In this paper, we evaluate and compare the approaches that were submitted to the challenge and identify methodological factors contributing to better performance.
Domain-Robust Mitotic Figure Detection with Style Transfer
Sep 30, 2021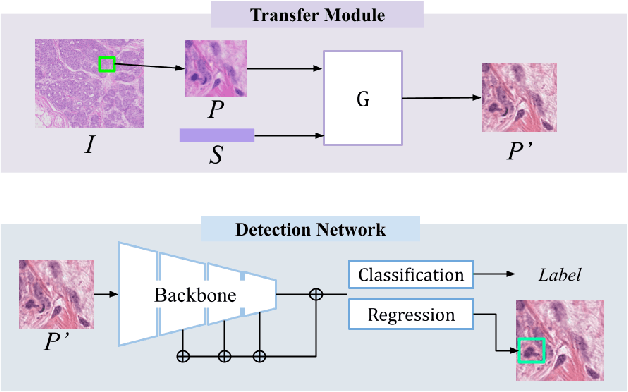

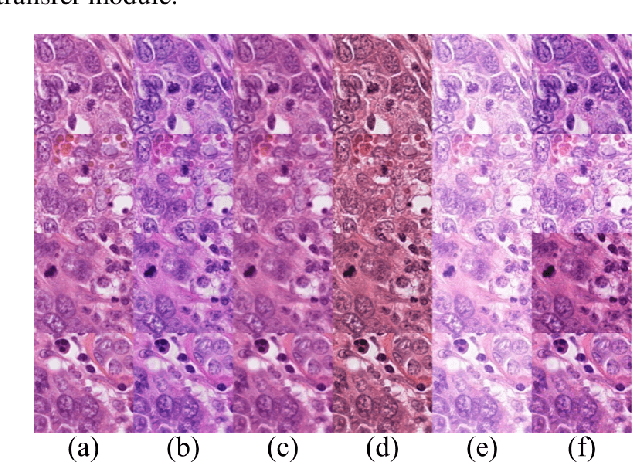
We propose a new training scheme for domain generalization in mitotic figure detection. Mitotic figures show different characteristics for each scanner. We consider each scanner as a 'domain' and the image distribution specified for each domain as 'style'. The goal is to train our network to be robust on scanner types by using various 'style' images. To expand the style variance, we transfer a style of the training image into arbitrary styles, by defining a module based on StarGAN. Our model with the proposed training scheme shows positive performance on MIDOG Preliminary Test-Set containing scanners never seen before.
Evaluating the Rainbow DQN Agent in Hanabi with Unseen Partners
Apr 28, 2020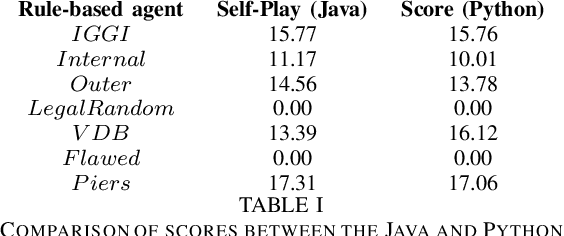
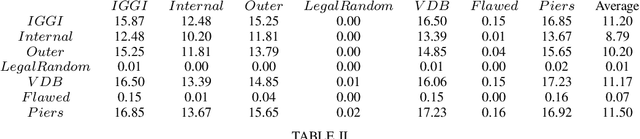

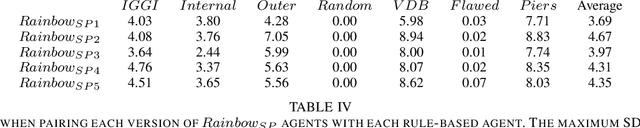
Hanabi is a cooperative game that challenges exist-ing AI techniques due to its focus on modeling the mental states ofother players to interpret and predict their behavior. While thereare agents that can achieve near-perfect scores in the game byagreeing on some shared strategy, comparatively little progresshas been made in ad-hoc cooperation settings, where partnersand strategies are not known in advance. In this paper, we showthat agents trained through self-play using the popular RainbowDQN architecture fail to cooperate well with simple rule-basedagents that were not seen during training and, conversely, whenthese agents are trained to play with any individual rule-basedagent, or even a mix of these agents, they fail to achieve goodself-play scores.