 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Rainbow DQN Agent in Hanabi with Unseen Partners
Paper and Code
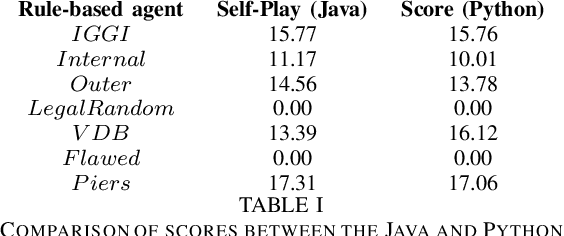
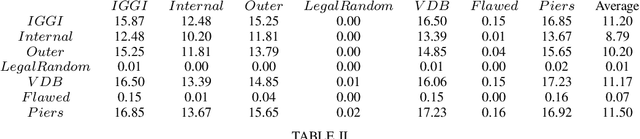

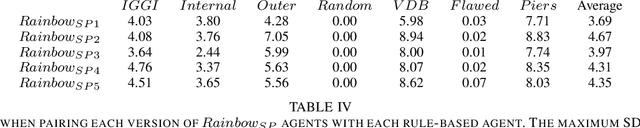
Hanabi is a cooperative game that challenges exist-ing AI techniques due to its focus on modeling the mental states ofother players to interpret and predict their behavior. While thereare agents that can achieve near-perfect scores in the game byagreeing on some shared strategy, comparatively little progresshas been made in ad-hoc cooperation settings, where partnersand strategies are not known in advance. In this paper, we showthat agents trained through self-play using the popular RainbowDQN architecture fail to cooperate well with simple rule-basedagents that were not seen during training and, conversely, whenthese agents are trained to play with any individual rule-basedagent, or even a mix of these agents, they fail to achieve goodself-play scores.