 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastAdaBelief: Improving Convergence Rate for Belief-based Adaptive Optimizer by Strong Convexity
Apr 28, 2021
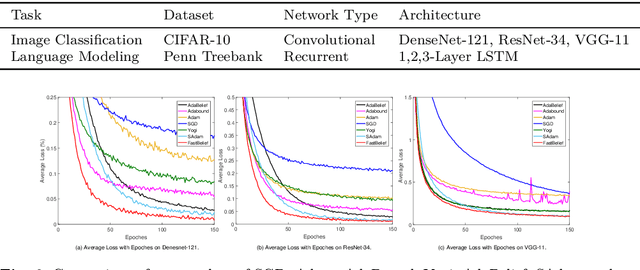
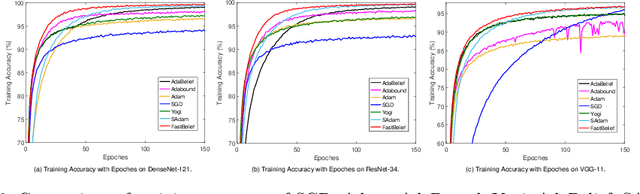
The AdaBelief algorithm demonstrates superior generalization ability to the Adam algorithm by viewing the exponential moving average of observed gradients. AdaBelief is proved to have a data-dependent $O(\sqrt{T})$ regret bound when objective functions are convex, where $T$ is a time horizon. However, it remains to be an open problem on how to exploit strong convexity to further improve the convergence rate of AdaBelief. To tackle this problem, we present a novel optimization algorithm under strong convexity, called FastAdaBelief. We prove that FastAdaBelief attains a data-dependant $O(\log T)$ regret bound, which is substantially lower than AdaBelief. In addition, the theoretical analysis is validated by extensive experiments performed on open datasets (i.e., CIFAR-10 and Penn Treebank) for image classification and language modeling.
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
Sep 29, 2020
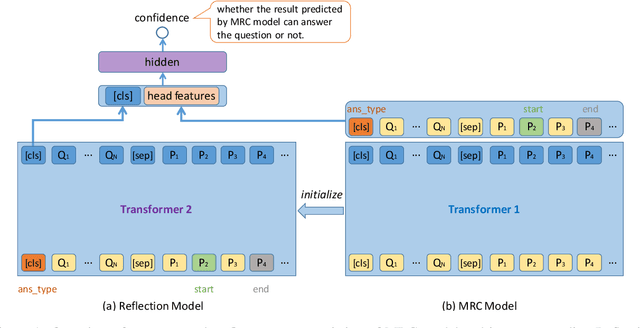

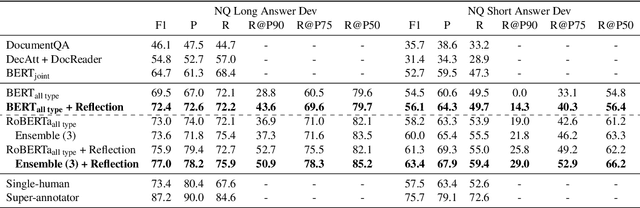
The Natural Questions (NQ) benchmark set brings new challenges to Machine Reading Comprehension: the answers are not only at different levels of granularity (long and short), but also of richer types (including no-answer, yes/no, single-span and multi-span). In this paper, we target at this challenge and handle all answer types systematically. In particular, we propose a novel approach called Reflection Net which leverages a two-step training procedure to identify the no-answer and wrong-answer cases. Extensive experiments are conducted to verify the effectiveness of our approach. At the time of paper writing (May.~20,~2020), our approach achieved the top 1 on both long and short answer leaderboard, with F1 scores of 77.2 and 64.1, respectively.
Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering
Sep 01, 2016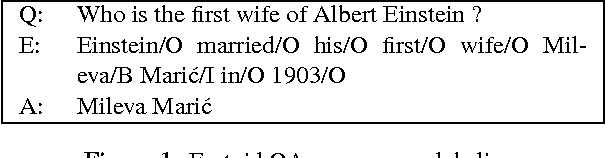

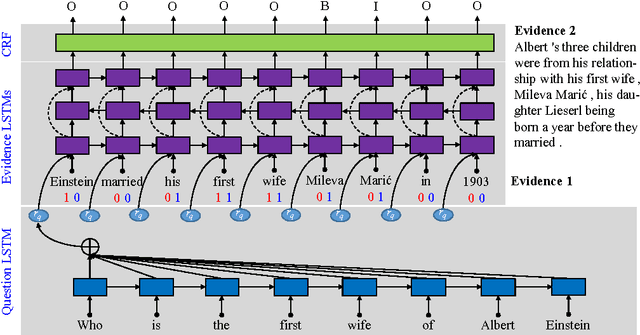
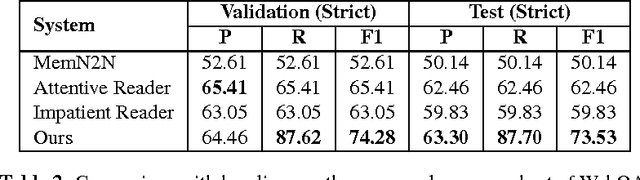
While question answering (QA) with neural network, i.e. neural QA, has achieved promising results in recent years, lacking of large scale real-word QA dataset is still a challenge for developing and evaluating neural QA system. To alleviate this problem, we propose a large scale human annotated real-world QA dataset WebQA with more than 42k questions and 556k evidences. As existing neural QA methods resolve QA either as sequence generation or classification/ranking problem, they face challenges of expensive softmax computation, unseen answers handling or separate candidate answer generation component. In this work, we cast neural QA as a sequence labeling problem and propose an end-to-end sequence labeling model, which overcomes all the above challenges. Experimental results on WebQA show that our model outperforms the baselines significantly with an F1 score of 74.69% with word-based input, and the performance drops only 3.72 F1 points with more challenging character-based input.
Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation
Jul 23, 2016Neural machine translation (NMT) aims at solving machine translation (MT) problems using neural networks and has exhibited promising results in recent years. However, most of the existing NMT models are shallow and there is still a performance gap between a single NMT model and the best conventional MT system. In this work, we introduce a new type of linear connections, named fast-forward connections, based on deep Long Short-Term Memory (LSTM) networks, and an interleaved bi-directional architecture for stacking the LSTM layers. Fast-forward connections play an essential role in propagating the gradients and building a deep topology of depth 16. On the WMT'14 English-to-French task, we achieve BLEU=37.7 with a single attention model, which outperforms the corresponding single shallow model by 6.2 BLEU points. This is the first time that a single NMT model achieves state-of-the-art performance and outperforms the best conventional model by 0.7 BLEU points. We can still achieve BLEU=36.3 even without using an attention mechanism. After special handling of unknown words and model ensembling, we obtain the best score reported to date on this task with BLEU=40.4. Our models are also validated on the more difficult WMT'14 English-to-German task.