 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Gradient for White-Box Adversarial Attacks
Oct 21, 2020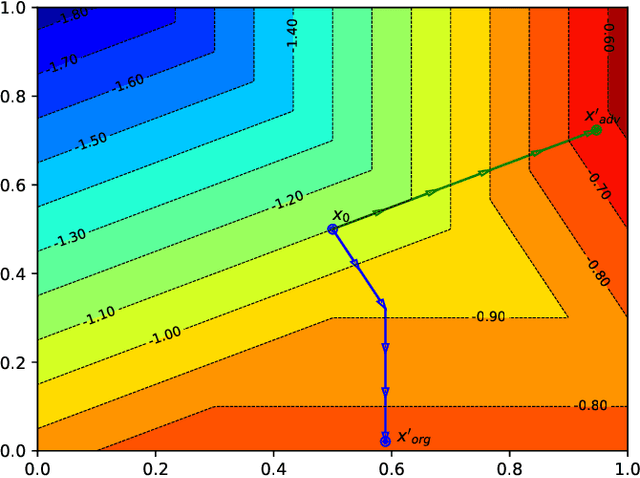
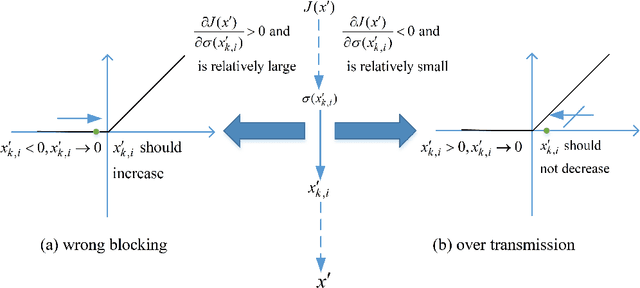

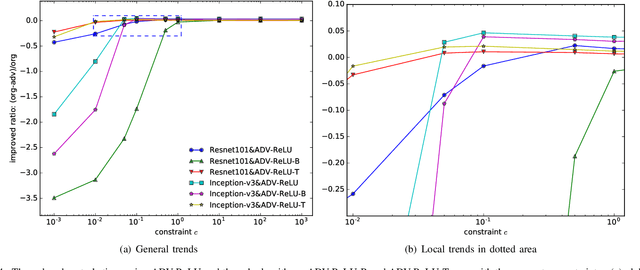
Deep neural networks (DNNs) are playing key roles in various artificial intelligence applications such as image classification and object recognition. However, a growing number of studies have shown that there exist adversarial examples in DNNs, which are almost imperceptibly different from original samples, but can greatly change the network output. Existing white-box attack algorithms can generate powerful adversarial examples. Nevertheless, most of the algorithms concentrate on how to iteratively make the best use of gradients to improve adversarial performance. In contrast, in this paper, we focus on the properties of the widely-used ReLU activation function, and discover that there exist two phenomena (i.e., wrong blocking and over transmission) misleading the calculation of gradients in ReLU during the backpropagation. Both issues enlarge the difference between the predicted changes of the loss function from gradient and corresponding actual changes, and mislead the gradients which results in larger perturbations. Therefore, we propose a universal adversarial example generation method, called ADV-ReLU, to enhance the performance of gradient based white-box attack algorithms. During the backpropagation of the network, our approach calculates the gradient of the loss function versus network input, maps the values to scores, and selects a part of them to update the misleading gradients. Comprehensive experimental results on \emph{ImageNet} demonstrate that our ADV-ReLU can be easily integrated into many state-of-the-art gradient-based white-box attack algorithms, as well as transferred to black-box attack attackers, to further decrease perturbations in the ${\ell _2}$-norm.
Neural Storyboard Artist: Visualizing Stories with Coherent Image Sequences
Nov 24, 2019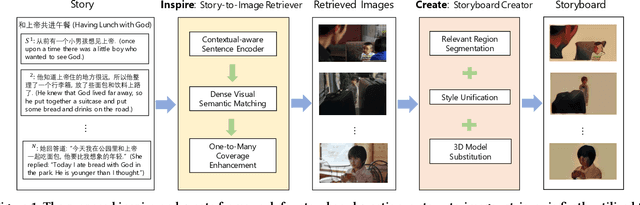
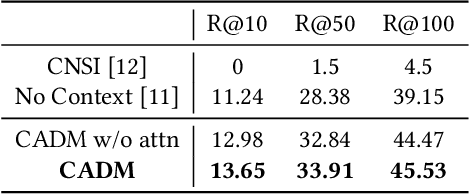

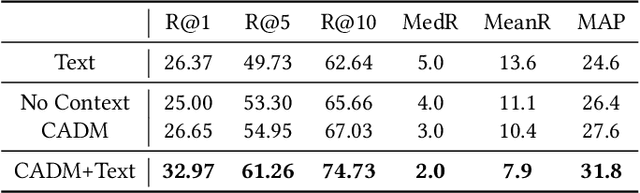
A storyboard is a sequence of images to illustrate a story containing multiple sentences, which has been a key process to create different story products. In this paper, we tackle a new multimedia task of automatic storyboard creation to facilitate this process and inspire human artists. Inspired by the fact that our understanding of languages is based on our past experience, we propose a novel inspire-and-create framework with a story-to-image retriever that selects relevant cinematic images for inspiration and a storyboard creator that further refines and renders images to improve the relevancy and visual consistency. The proposed retriever dynamically employs contextual information in the story with hierarchical attentions and applies dense visual-semantic matching to accurately retrieve and ground images. The creator then employs three rendering steps to increase the flexibility of retrieved images, which include erasing irrelevant regions, unifying styles of images and substituting consistent characters. We carry out extensive experiments on both in-domain and out-of-domain visual story datasets. The proposed model achieves better quantitative performance than the state-of-the-art baselines for storyboard creation. Qualitative visualizations and user studies further verify that our approach can create high-quality storyboards even for stories in the wild.