 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-Label: Improving GNN Models for Catalysis Systems by Label Deconstruction and Reconstruction
Mar 06, 2023Attaining the equilibrium state of a catalyst-adsorbate system is key to fundamentally assessing its effective properties, such as adsorption energy. Machine learning methods with finer supervision strategies have been applied to boost and guide the relaxation process of an atomic system and better predict its properties at the equilibrium state. In this paper, we present a novel graph neural network (GNN) supervision and prediction strategy DR-Label. The method enhances the supervision signal, reduces the multiplicity of solutions in edge representation, and encourages the model to provide node predictions that are graph structural variation robust. DR-Label first Deconstructs finer-grained equilibrium state information to the model by projecting the node-level supervision signal to each edge. Reversely, the model Reconstructs a more robust equilibrium state prediction by transforming edge-level predictions to node-level with a sphere-fitting algorithm. The DR-Label strategy was applied to three radically distinct models, each of which displayed consistent performance enhancements. Based on the DR-Label strategy, we further proposed DRFormer, which achieved a new state-of-the-art performance on the Open Catalyst 2020 (OC20) dataset and the Cu-based single-atom-alloyed CO adsorption (SAA) dataset. We expect that our work will highlight crucial steps for the development of a more accurate model in equilibrium state property prediction of a catalysis system.
Multi-Task Mixture Density Graph Neural Networks for Predicting Cu-based Single-Atom Alloy Catalysts for CO2 Reduction Reaction
Sep 15, 2022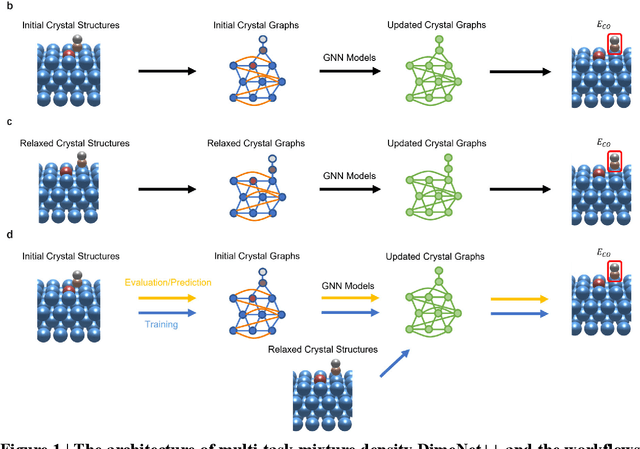
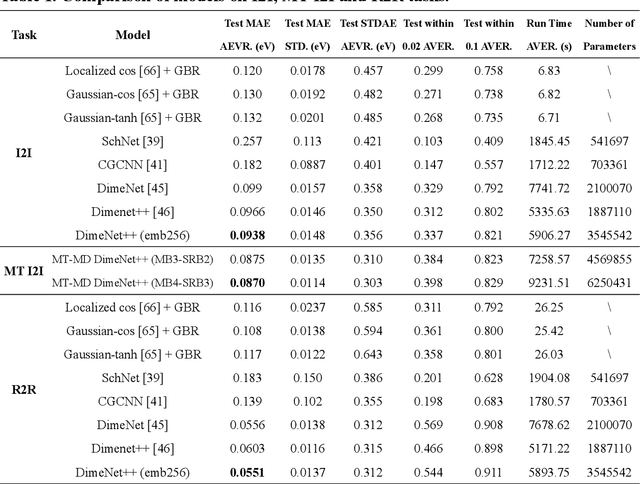
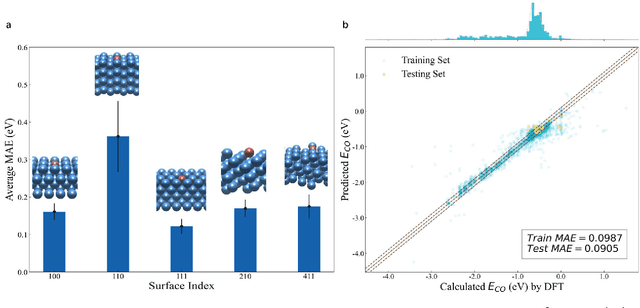

Graph neural networks (GNNs) have drawn more and more attention from material scientists and demonstrated a high capacity to establish connections between the structure and properties. However, with only unrelaxed structures provided as input, few GNN models can predict the thermodynamic properties of relaxed configurations with an acceptable level of error. In this work, we develop a multi-task (MT) architecture based on DimeNet++ and mixture density networks to improve the performance of such task. Taking CO adsorption on Cu-based single-atom alloy catalysts as an illustration, we show that our method can reliably estimate CO adsorption energy with a mean absolute error of 0.087 eV from the initial CO adsorption structures without costly first-principles calculations. Further, compared to other state-of-the-art GNN methods, our model exhibits improved generalization ability when predicting catalytic performance of out-of-domain configurations, built with either unseen substrate surfaces or doping species. We show that the proposed MT GNN strategy can facilitate catalyst discovery.
Vision at A Glance: Interplay between Fine and Coarse Information Processing Pathways
Aug 23, 2020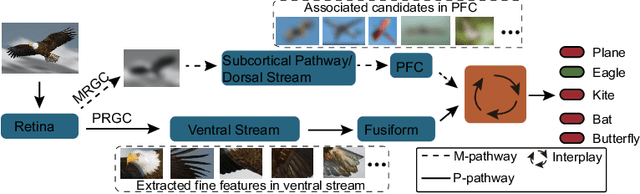
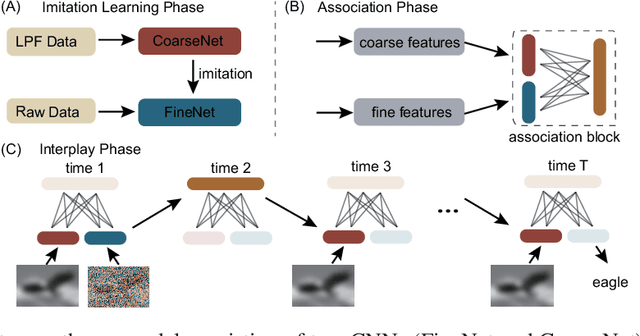

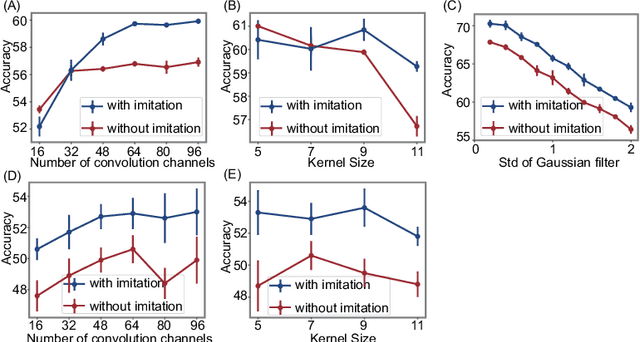
Object recognition is often viewed as a feedforward, bottom-up process in machine learning, but in real neural systems, object recognition is a complicated process which involves the interplay between two signal pathways. One is the parvocellular pathway (P-pathway), which is slow and extracts fine features of objects; the other is the magnocellular pathway (M-pathway), which is fast and extracts coarse features of objects. It has been suggested that the interplay between the two pathways endows the neural system with the capacity of processing visual information rapidly, adaptively, and robustly. However, the underlying computational mechanisms remain largely unknown. In this study, we build a computational model to elucidate the computational advantages associated with the interactions between two pathways. Our model consists of two convolution neural networks: one mimics the P-pathway, referred to as FineNet, which is deep, has small-size kernels, and receives detailed visual inputs; the other mimics the M-pathway, referred to as CoarseNet, which is shallow, has large-size kernels, and receives low-pass filtered or binarized visual inputs. The two pathways interact with each other via a Restricted Boltzmann Machine. We find that: 1) FineNet can teach CoarseNet through imitation and improve its performance considerably; 2) CoarseNet can improve the noise robustness of FineNet through association; 3) the output of CoarseNet can serve as a cognitive bias to improve the performance of FineNet. We hope that this study will provide insight into understanding visual information processing and inspire the development of new object recognition architectures.
Unsupervised Few-shot Learning via Self-supervised Training
Dec 20, 2019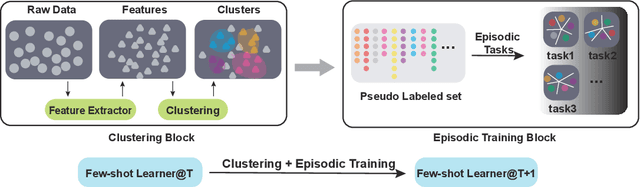
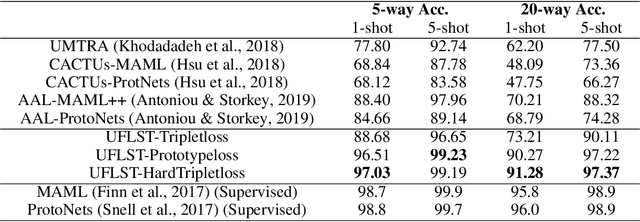
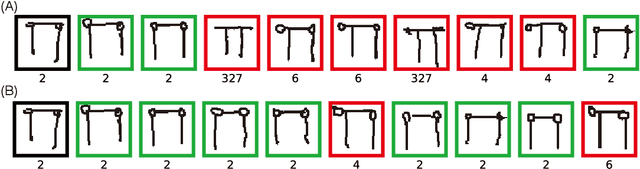
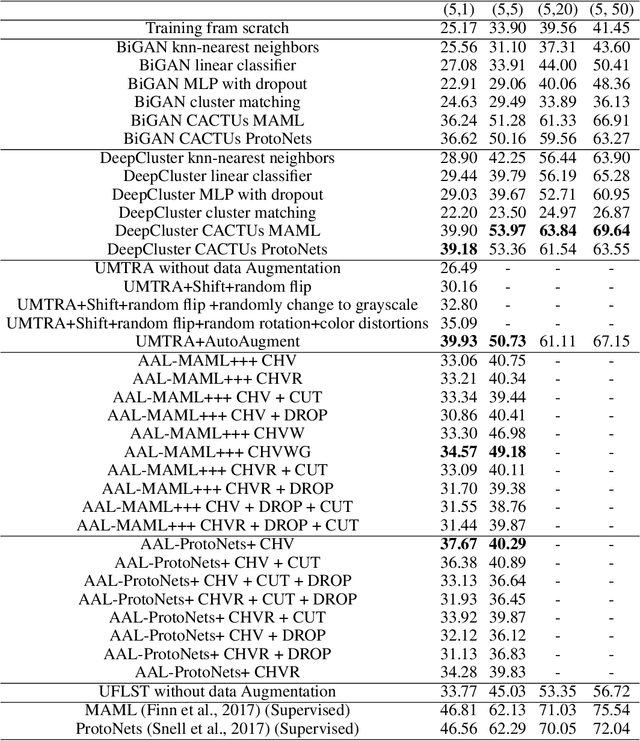
Learning from limited exemplars (few-shot learning) is a fundamental, unsolved problem that has been laboriously explored in the machine learning community. However, current few-shot learners are mostly supervised and rely heavily on a large amount of labeled examples. Unsupervised learning is a more natural procedure for cognitive mammals and has produced promising results in many machine learning tasks. In the current study, we develop a method to learn an unsupervised few-shot learner via self-supervised training (UFLST), which can effectively generalize to novel but related classes. The proposed model consists of two alternate processes, progressive clustering and episodic training. The former generates pseudo-labeled training examples for constructing episodic tasks; and the later trains the few-shot learner using the generated episodic tasks which further optimizes the feature representations of data. The two processes facilitate with each other, and eventually produce a high quality few-shot learner. Using the benchmark dataset Omniglot and Mini-ImageNet, we show that our model outperforms other unsupervised few-shot learning methods. Using the benchmark dataset Market1501, we further demonstrate the feasibility of our model to a real-world application on person re-identification.
Spatiotemporal Information Processing with a Reservoir Decision-making Network
Jul 28, 2019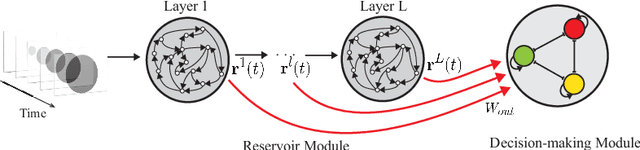
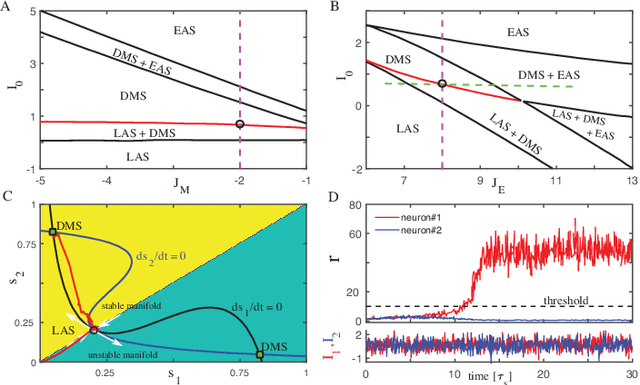
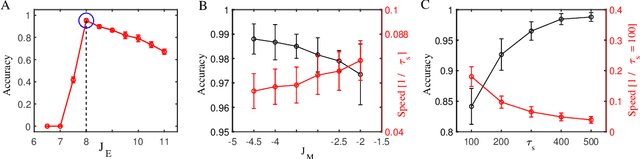
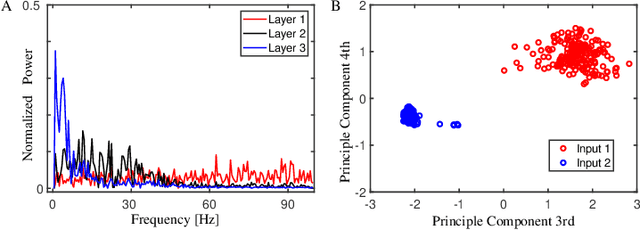
Spatiotemporal information processing is fundamental to brain functions. The present study investigates a canonic neural network model for spatiotemporal pattern recognition. Specifically, the model consists of two modules, a reservoir subnetwork and a decision-making subnetwork. The former projects complex spatiotemporal patterns into spatially separated neural representations, and the latter reads out these neural representations via integrating information over time; the two modules are combined together via supervised-learning using known examples. We elucidate the working mechanism of the model and demonstrate its feasibility for discriminating complex spatiotemporal patterns. Our model reproduces the phenomenon of recognizing looming patterns in the neural system, and can learn to discriminate gait with very few training examples. We hope this study gives us insight into understanding how spatiotemporal information is processed in the brain and helps us to develop brain-inspired application algorithms.