 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagging-Based Model Merging for Robust General Text Embeddings
Feb 05, 2026General-purpose text embedding models underpin a wide range of NLP and information retrieval applications, and are typically trained on large-scale multi-task corpora to encourage broad generalization. However, it remains unclear how different multi-task training strategies compare in practice, and how to efficiently adapt embedding models as new domains and data types continually emerge. In this work, we present a systematic study of multi-task training for text embeddings from two perspectives: data scheduling and model merging. We compare batch-level shuffling, sequential training variants, two-stage training, and multiple merging granularities, and find that simple batch-level shuffling consistently yields the strongest overall performance, suggesting that task conflicts are limited and training datasets are largely complementary. Despite its effectiveness, batch-level shuffling exhibits two practical limitations: suboptimal out-of-domain (OOD) generalization and poor suitability for incremental learning due to expensive full retraining. To address these issues, we propose Bagging-based rObust mOdel Merging (\modelname), which trains multiple embedding models on sampled subsets and merges them into a single model, improving robustness while retaining single-model inference efficiency. Moreover, \modelname naturally supports efficient incremental updates by training lightweight update models on new data with a small historical subset and merging them into the existing model. Experiments across diverse embedding benchmarks demonstrate that \modelname consistently improves both in-domain and OOD performance over full-corpus batch-level shuffling, while substantially reducing training cost in incremental learning settings.
Towards a Universal Image Degradation Model via Content-Degradation Disentanglement
May 19, 2025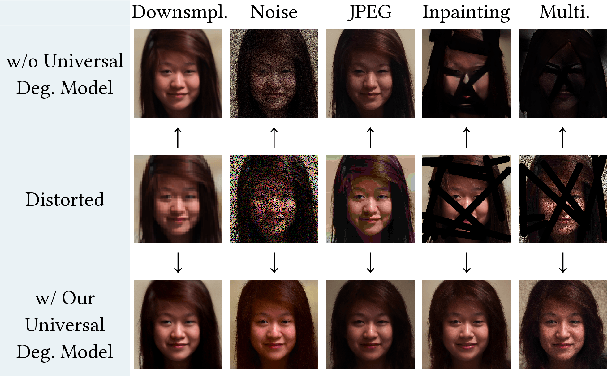
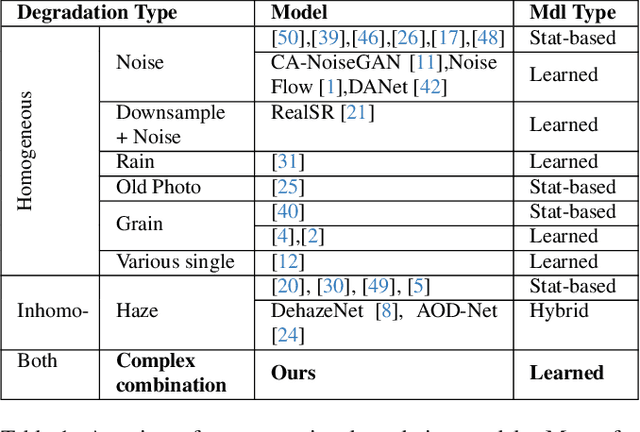

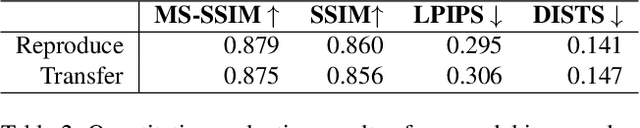
Image degradation synthesis is highly desirable in a wide variety of applications ranging from image restoration to simulating artistic effects. Existing models are designed to generate one specific or a narrow set of degradations, which often require user-provided degradation parameters. As a result, they lack the generalizability to synthesize degradations beyond their initial design or adapt to other applications. Here we propose the first universal degradation model that can synthesize a broad spectrum of complex and realistic degradations containing both homogeneous (global) and inhomogeneous (spatially varying) components. Our model automatically extracts and disentangles homogeneous and inhomogeneous degradation features, which are later used for degradation synthesis without user intervention. A disentangle-by-compression method is proposed to separate degradation information from images. Two novel modules for extracting and incorporating inhomogeneous degradations are created to model inhomogeneous components in complex degradations. We demonstrate the model's accuracy and adaptability in film-grain simulation and blind image restoration tasks. The demo video, code, and dataset of this project will be released upon publication at github.com/yangwenbo99/content-degradation-disentanglement.
CAMEF: Causal-Augmented Multi-Modality Event-Driven Financial Forecasting by Integrating Time Series Patterns and Salient Macroeconomic Announcements
Feb 07, 2025

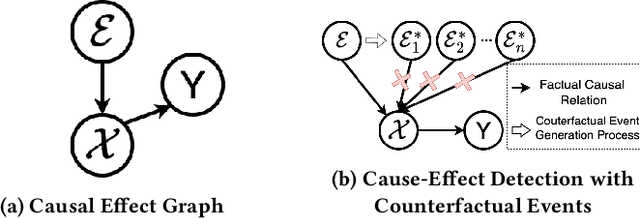

Accurately forecasting the impact of macroeconomic events is critical for investors and policymakers. Salient events like monetary policy decisions and employment reports often trigger market movements by shaping expectations of economic growth and risk, thereby establishing causal relationships between events and market behavior. Existing forecasting methods typically focus either on textual analysis or time-series modeling, but fail to capture the multi-modal nature of financial markets and the causal relationship between events and price movements. To address these gaps, we propose CAMEF (Causal-Augmented Multi-Modality Event-Driven Financial Forecasting), a multi-modality framework that effectively integrates textual and time-series data with a causal learning mechanism and an LLM-based counterfactual event augmentation technique for causal-enhanced financial forecasting. Our contributions include: (1) a multi-modal framework that captures causal relationships between policy texts and historical price data; (2) a new financial dataset with six types of macroeconomic releases from 2008 to April 2024, and high-frequency real trading data for five key U.S. financial assets; and (3) an LLM-based counterfactual event augmentation strategy. We compare CAMEF to state-of-the-art transformer-based time-series and multi-modal baselines, and perform ablation studies to validate the effectiveness of the causal learning mechanism and event types.