 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
Modular Neural Image Signal Processing
Dec 09, 2025
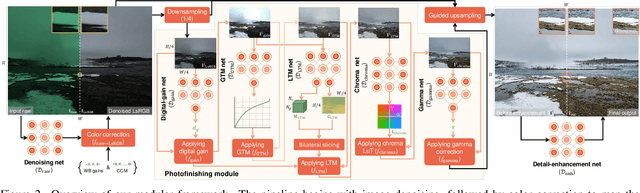
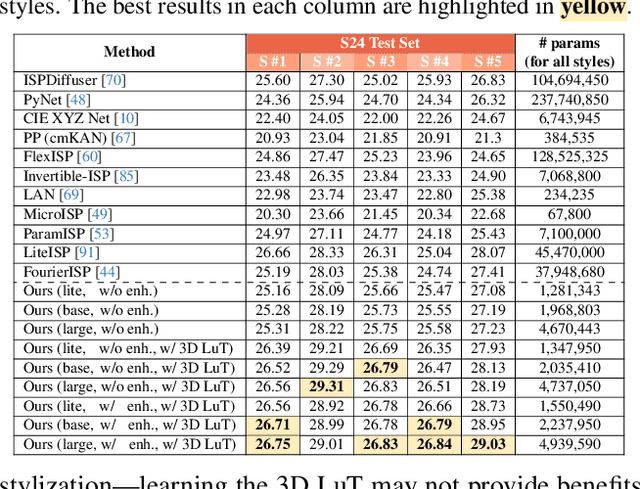
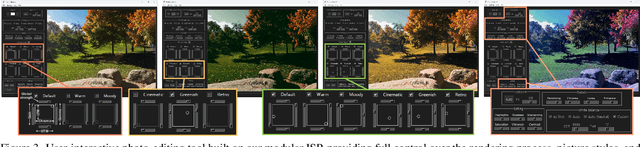
This paper presents a modular neural image signal processing (ISP) framework that processes raw inputs and renders high-quality display-referred images. Unlike prior neural ISP designs, our method introduces a high degree of modularity, providing full control over multiple intermediate stages of the rendering process.~This modular design not only achieves high rendering accuracy but also improves scalability, debuggability, generalization to unseen cameras, and flexibility to match different user-preference styles. To demonstrate the advantages of this design, we built a user-interactive photo-editing tool that leverages our neural ISP to support diverse editing operations and picture styles. The tool is carefully engineered to take advantage of the high-quality rendering of our neural ISP and to enable unlimited post-editable re-rendering. Our method is a fully learning-based framework with variants of different capacities, all of moderate size (ranging from ~0.5 M to ~3.9 M parameters for the entire pipeline), and consistently delivers competitive qualitative and quantitative results across multiple test sets. Watch the supplemental video at: https://youtu.be/ByhQjQSjxVM
Towards a Universal Image Degradation Model via Content-Degradation Disentanglement
May 19, 2025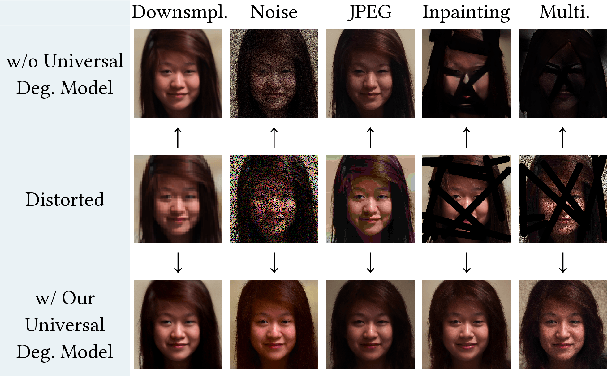
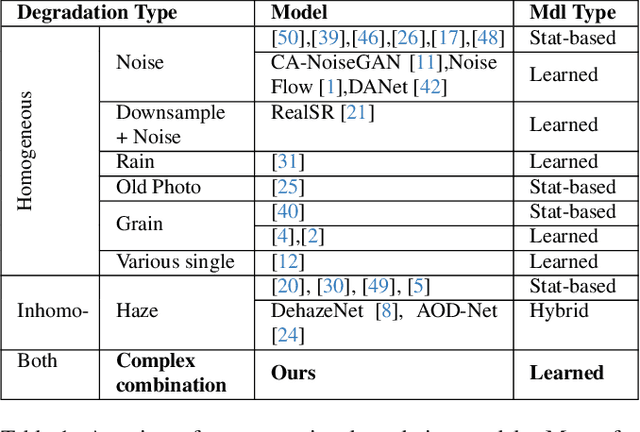

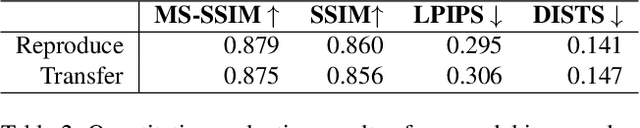
Image degradation synthesis is highly desirable in a wide variety of applications ranging from image restoration to simulating artistic effects. Existing models are designed to generate one specific or a narrow set of degradations, which often require user-provided degradation parameters. As a result, they lack the generalizability to synthesize degradations beyond their initial design or adapt to other applications. Here we propose the first universal degradation model that can synthesize a broad spectrum of complex and realistic degradations containing both homogeneous (global) and inhomogeneous (spatially varying) components. Our model automatically extracts and disentangles homogeneous and inhomogeneous degradation features, which are later used for degradation synthesis without user intervention. A disentangle-by-compression method is proposed to separate degradation information from images. Two novel modules for extracting and incorporating inhomogeneous degradations are created to model inhomogeneous components in complex degradations. We demonstrate the model's accuracy and adaptability in film-grain simulation and blind image restoration tasks. The demo video, code, and dataset of this project will be released upon publication at github.com/yangwenbo99/content-degradation-disentanglement.
Deep Image Debanding
Oct 16, 2021
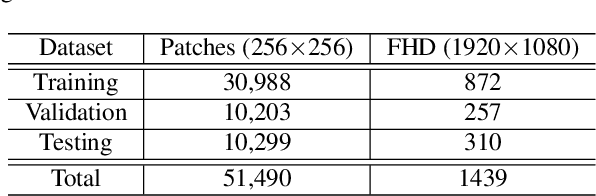

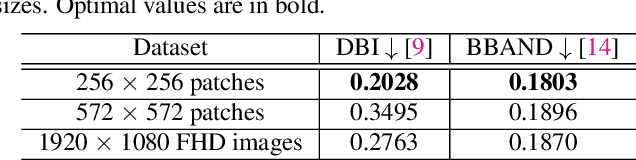
Banding or false contour is an annoying visual artifact whose impact is even more pronounced in ultra high definition, high dynamic range, and wide colour gamut visual content, which is becoming increasingly popular. Since users associate a heightened expectation of quality with such content and banding leads to deteriorated visual quality-of-experience, the area of banding removal or debanding has taken paramount importance. Existing debanding approaches are mostly knowledge-driven. Despite the widespread success of deep learning in other areas of image processing and computer vision, data-driven debanding approaches remain surprisingly missing. In this work, we make one of the first attempts to develop a deep learning based banding artifact removal method for images and name it deep debanding network (deepDeband). For its training, we construct a large-scale dataset of 51,490 pairs of corresponding pristine and banded image patches. Performance evaluation shows that deepDeband is successful at greatly reducing banding artifacts in images, outperforming existing methods both quantitatively and visually.
Deep Neural Networks for Blind Image Quality Assessment: Addressing the Data Challenge
Sep 24, 2021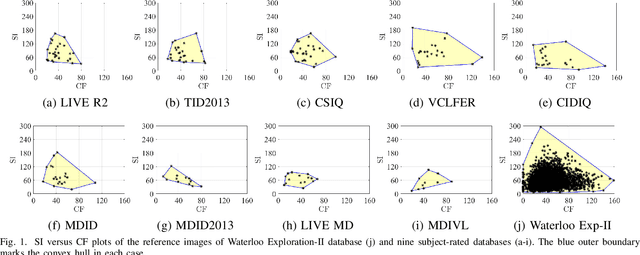
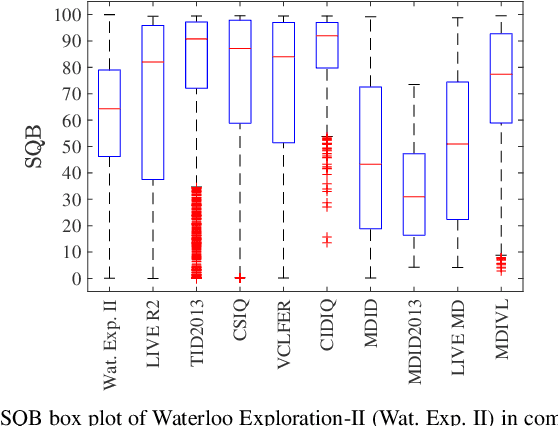
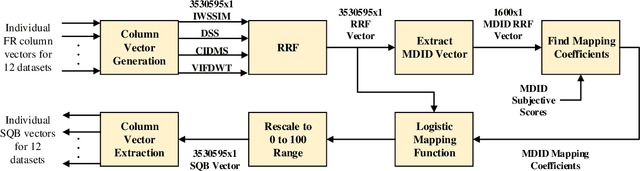
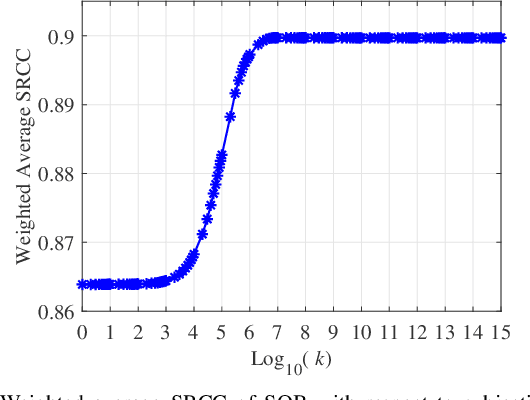
The enormous space and diversity of natural images is usually represented by a few small-scale human-rated image quality assessment (IQA) datasets. This casts great challenges to deep neural network (DNN) based blind IQA (BIQA), which requires large-scale training data that is representative of the natural image distribution. It is extremely difficult to create human-rated IQA datasets composed of millions of images due to constraints of subjective testing. While a number of efforts have focused on design innovations to enhance the performance of DNN based BIQA, attempts to address the scarcity of labeled IQA data remain surprisingly missing. To address this data challenge, we construct so far the largest IQA database, namely Waterloo Exploration-II, which contains 3,570 pristine reference and around 3.45 million singly and multiply distorted images. Since subjective testing for such a large dataset is nearly impossible, we develop a novel mechanism that synthetically assigns perceptual quality labels to the distorted images. We construct a DNN-based BIQA model called EONSS, train it on Waterloo Exploration-II, and test it on nine subject-rated IQA datasets, without any retraining or fine-tuning. The results show that with a straightforward DNN architecture, EONSS is able to outperform the very state-of-the-art in BIQA, both in terms of quality prediction performance and execution speed. This study strongly supports the view that the quantity and quality of meaningfully annotated training data, rather than a sophisticated network architecture or training strategy, is the dominating factor that determines the performance of DNN-based BIQA models. (Note: Since this is an ongoing project, the final versions of Waterloo Exploration-II database, quality annotations, and EONSS, will be made publicly available in the future when it culminates.)
Quantifying Visual Image Quality: A Bayesian View
Feb 22, 2021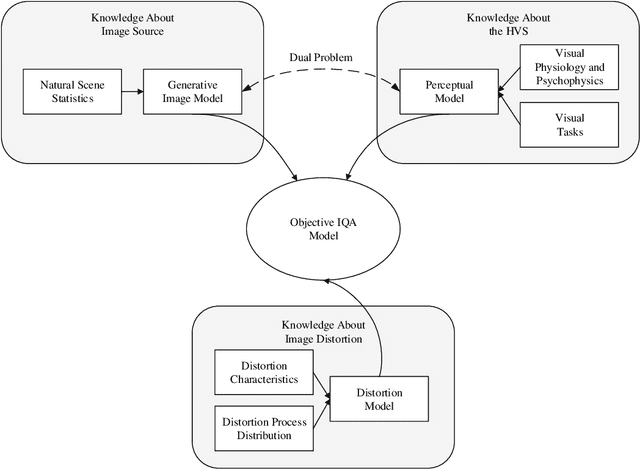
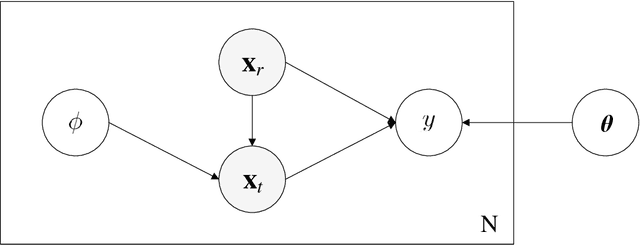


Image quality assessment (IQA) models aim to establish a quantitative relationship between visual images and their perceptual quality by human observers. IQA modeling plays a special bridging role between vision science and engineering practice, both as a test-bed for vision theories and computational biovision models, and as a powerful tool that could potentially make profound impact on a broad range of image processing, computer vision, and computer graphics applications, for design, optimization, and evaluation purposes. IQA research has enjoyed an accelerated growth in the past two decades. Here we present an overview of IQA methods from a Bayesian perspective, with the goals of unifying a wide spectrum of IQA approaches under a common framework and providing useful references to fundamental concepts accessible to vision scientists and image processing practitioners. We discuss the implications of the successes and limitations of modern IQA methods for biological vision and the prospect for vision science to inform the design of future artificial vision systems.
FocusLiteNN: High Efficiency Focus Quality Assessment for Digital Pathology
Jul 11, 2020
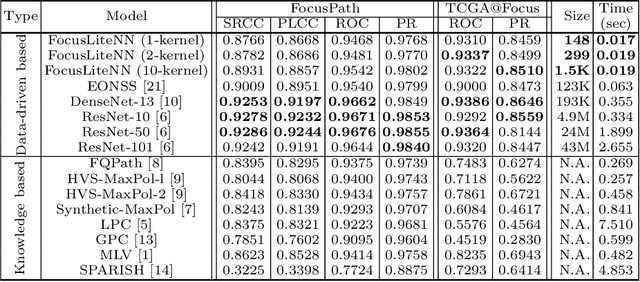
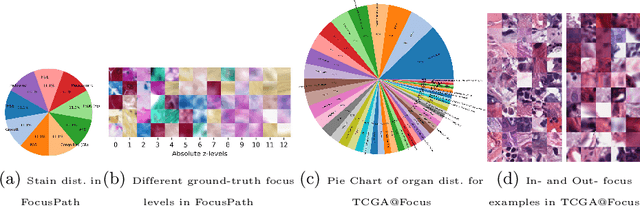
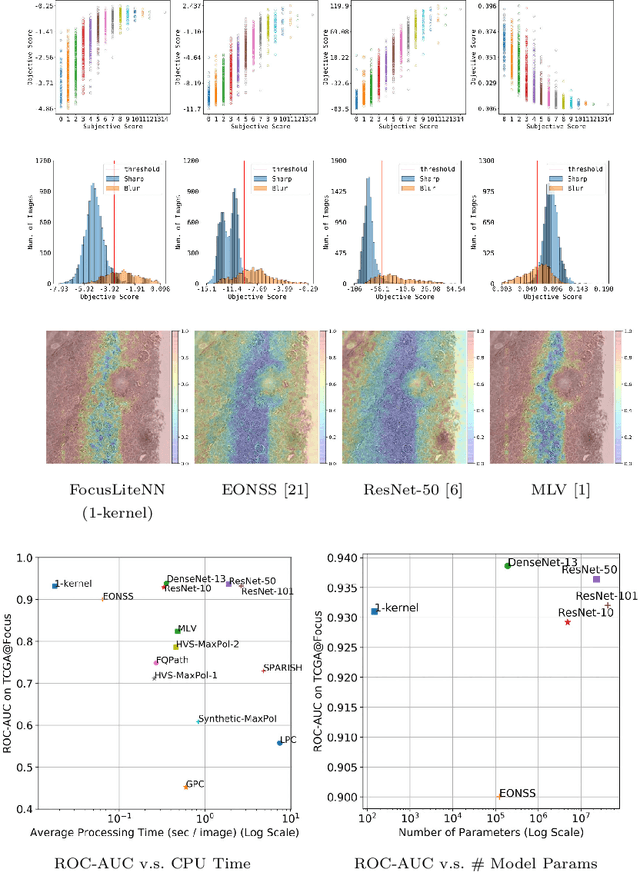
Out-of-focus microscopy lens in digital pathology is a critical bottleneck in high-throughput Whole Slide Image (WSI) scanning platforms, for which pixel-level automated Focus Quality Assessment (FQA) methods are highly desirable to help significantly accelerate the clinical workflows. Existing FQA methods include both knowledge-driven and data-driven approaches. While data-driven approaches such as Convolutional Neural Network (CNN) based methods have shown great promises, they are difficult to use in practice due to their high computational complexity and lack of transferability. Here, we propose a highly efficient CNN-based model that maintains fast computations similar to the knowledge-driven methods without excessive hardware requirements such as GPUs. We create a training dataset using FocusPath which encompasses diverse tissue slides across nine different stain colors, where the stain diversity greatly helps the model to learn diverse color spectrum and tissue structures. In our attempt to reduce the CNN complexity, we find with surprise that even trimming down the CNN to the minimal level, it still achieves a highly competitive performance. We introduce a novel comprehensive evaluation dataset, the largest of its kind, annotated and compiled from TCGA repository for model assessment and comparison, for which the proposed method exhibits superior precision-speed trade-off when compared with existing knowledge-driven and data-driven FQA approaches.