 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegraded Reference Image Quality Assessment
Oct 28, 2021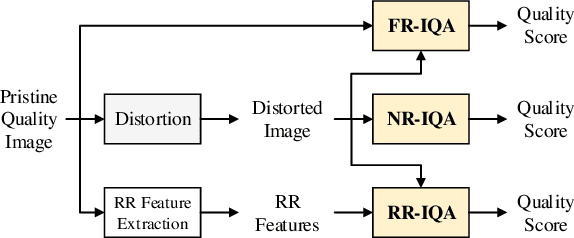

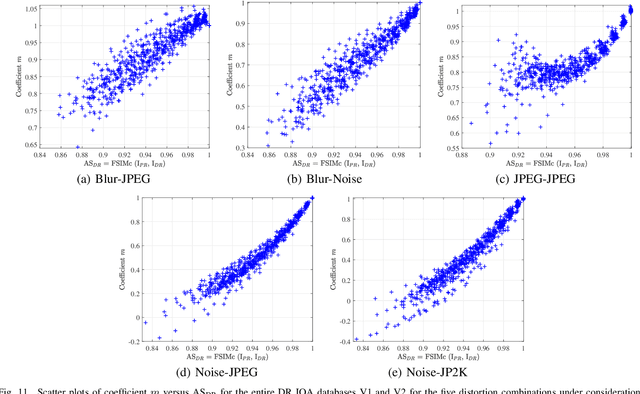
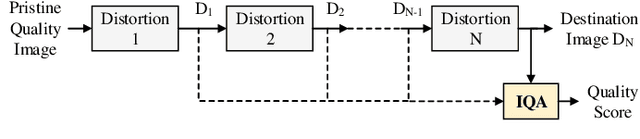
In practical media distribution systems, visual content usually undergoes multiple stages of quality degradation along the delivery chain, but the pristine source content is rarely available at most quality monitoring points along the chain to serve as a reference for quality assessment. As a result, full-reference (FR) and reduced-reference (RR) image quality assessment (IQA) methods are generally infeasible. Although no-reference (NR) methods are readily applicable, their performance is often not reliable. On the other hand, intermediate references of degraded quality are often available, e.g., at the input of video transcoders, but how to make the best use of them in proper ways has not been deeply investigated. Here we make one of the first attempts to establish a new paradigm named degraded-reference IQA (DR IQA). Specifically, we lay out the architectures of DR IQA and introduce a 6-bit code to denote the choices of configurations. We construct the first large-scale databases dedicated to DR IQA and will make them publicly available. We make novel observations on distortion behavior in multi-stage distortion pipelines by comprehensively analyzing five multiple distortion combinations. Based on these observations, we develop novel DR IQA models and make extensive comparisons with a series of baseline models derived from top-performing FR and NR models. The results suggest that DR IQA may offer significant performance improvement in multiple distortion environments, thereby establishing DR IQA as a valid IQA paradigm that is worth further exploration.
Deep Image Debanding
Oct 16, 2021
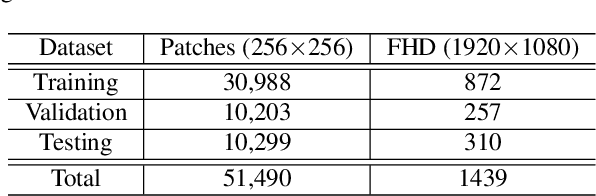

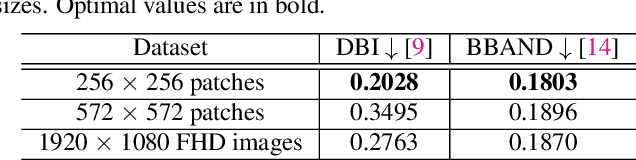
Banding or false contour is an annoying visual artifact whose impact is even more pronounced in ultra high definition, high dynamic range, and wide colour gamut visual content, which is becoming increasingly popular. Since users associate a heightened expectation of quality with such content and banding leads to deteriorated visual quality-of-experience, the area of banding removal or debanding has taken paramount importance. Existing debanding approaches are mostly knowledge-driven. Despite the widespread success of deep learning in other areas of image processing and computer vision, data-driven debanding approaches remain surprisingly missing. In this work, we make one of the first attempts to develop a deep learning based banding artifact removal method for images and name it deep debanding network (deepDeband). For its training, we construct a large-scale dataset of 51,490 pairs of corresponding pristine and banded image patches. Performance evaluation shows that deepDeband is successful at greatly reducing banding artifacts in images, outperforming existing methods both quantitatively and visually.
Deep Neural Networks for Blind Image Quality Assessment: Addressing the Data Challenge
Sep 24, 2021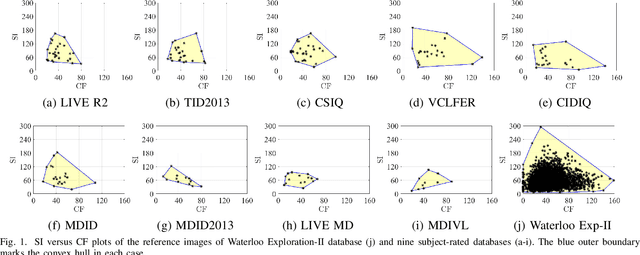
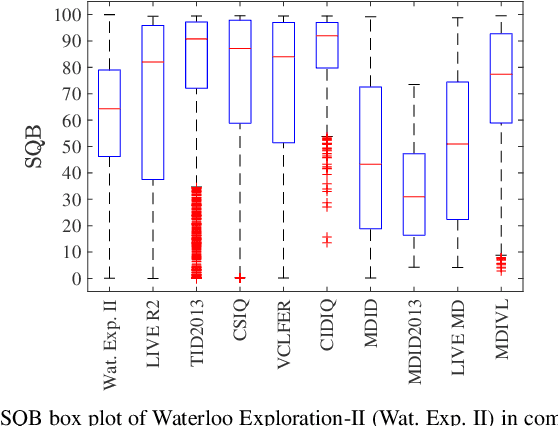
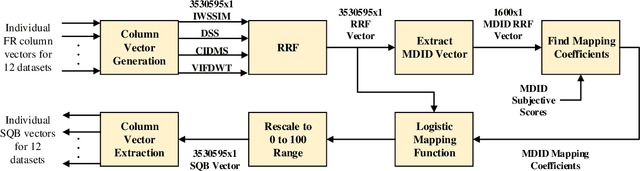
The enormous space and diversity of natural images is usually represented by a few small-scale human-rated image quality assessment (IQA) datasets. This casts great challenges to deep neural network (DNN) based blind IQA (BIQA), which requires large-scale training data that is representative of the natural image distribution. It is extremely difficult to create human-rated IQA datasets composed of millions of images due to constraints of subjective testing. While a number of efforts have focused on design innovations to enhance the performance of DNN based BIQA, attempts to address the scarcity of labeled IQA data remain surprisingly missing. To address this data challenge, we construct so far the largest IQA database, namely Waterloo Exploration-II, which contains 3,570 pristine reference and around 3.45 million singly and multiply distorted images. Since subjective testing for such a large dataset is nearly impossible, we develop a novel mechanism that synthetically assigns perceptual quality labels to the distorted images. We construct a DNN-based BIQA model called EONSS, train it on Waterloo Exploration-II, and test it on nine subject-rated IQA datasets, without any retraining or fine-tuning. The results show that with a straightforward DNN architecture, EONSS is able to outperform the very state-of-the-art in BIQA, both in terms of quality prediction performance and execution speed. This study strongly supports the view that the quantity and quality of meaningfully annotated training data, rather than a sophisticated network architecture or training strategy, is the dominating factor that determines the performance of DNN-based BIQA models. (Note: Since this is an ongoing project, the final versions of Waterloo Exploration-II database, quality annotations, and EONSS, will be made publicly available in the future when it culminates.)