 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Attacks on Deep Reinforcement Learning
Jul 24, 2019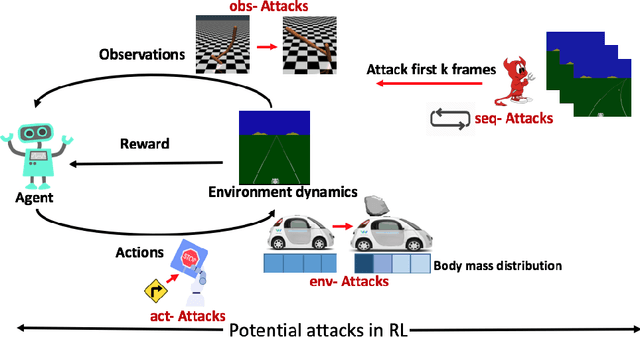
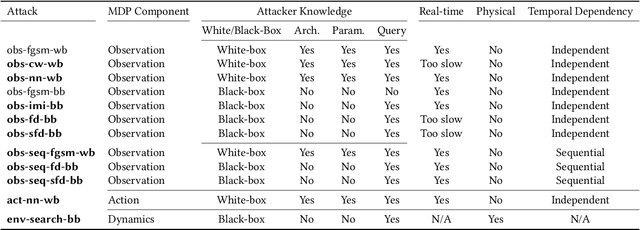
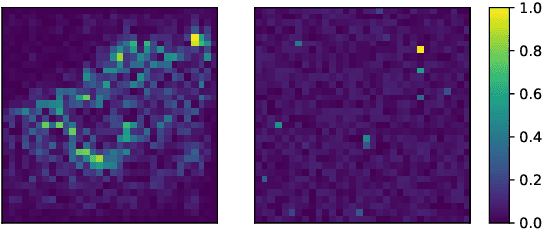

Deep reinforcement learning (DRL) has achieved great success in various applications. However, recent studies show that machine learning models are vulnerable to adversarial attacks. DRL models have been attacked by adding perturbations to observations. While such observation based attack is only one aspect of potential attacks on DRL, other forms of attacks which are more practical require further analysis, such as manipulating environment dynamics. Therefore, we propose to understand the vulnerabilities of DRL from various perspectives and provide a thorough taxonomy of potential attacks. We conduct the first set of experiments on the unexplored parts within the taxonomy. In addition to current observation based attacks against DRL, we propose the first targeted attacks based on action space and environment dynamics. We also introduce the online sequential attacks based on temporal consistency information among frames. To better estimate gradient in black-box setting, we propose a sampling strategy and theoretically prove its efficiency and estimation error bound. We conduct extensive experiments to compare the effectiveness of different attacks with several baselines in various environments, including game playing, robotics control, and autonomous driving.
Generating Adversarial Examples with Adversarial Networks
Jan 15, 2018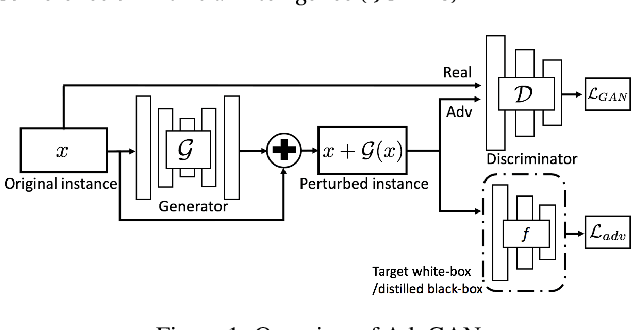


Deep neural networks (DNNs) have been found to be vulnerable to adversarial examples resulting from adding small-magnitude perturbations to inputs. Such adversarial examples can mislead DNNs to produce adversary-selected results. Different attack strategies have been proposed to generate adversarial examples, but how to produce them with high perceptual quality and more efficiently requires more research efforts. In this paper, we propose AdvGAN to generate adversarial examples with generative adversarial networks (GANs), which can learn and approximate the distribution of original instances. For AdvGAN, once the generator is trained, it can generate adversarial perturbations efficiently for any instance, so as to potentially accelerate adversarial training as defenses. We apply AdvGAN in both semi-whitebox and black-box attack settings. In semi-whitebox attacks, there is no need to access the original target model after the generator is trained, in contrast to traditional white-box attacks. In black-box attacks, we dynamically train a distilled model for the black-box model and optimize the generator accordingly. Adversarial examples generated by AdvGAN on different target models have high attack success rate under state-of-the-art defenses compared to other attacks. Our attack has placed the first with 92.76% accuracy on a public MNIST black-box attack challenge.
Spatially Transformed Adversarial Examples
Jan 09, 2018



Recent studies show that widely used deep neural networks (DNNs) are vulnerable to carefully crafted adversarial examples. Many advanced algorithms have been proposed to generate adversarial examples by leveraging the $\mathcal{L}_p$ distance for penalizing perturbations. Researchers have explored different defense methods to defend against such adversarial attacks. While the effectiveness of $\mathcal{L}_p$ distance as a metric of perceptual quality remains an active research area, in this paper we will instead focus on a different type of perturbation, namely spatial transformation, as opposed to manipulating the pixel values directly as in prior works. Perturbations generated through spatial transformation could result in large $\mathcal{L}_p$ distance measures, but our extensive experiments show that such spatially transformed adversarial examples are perceptually realistic and more difficult to defend against with existing defense systems. This potentially provides a new direction in adversarial example generation and the design of corresponding defenses. We visualize the spatial transformation based perturbation for different examples and show that our technique can produce realistic adversarial examples with smooth image deformation. Finally, we visualize the attention of deep networks with different types of adversarial examples to better understand how these examples are interpreted.
Exploring the Space of Black-box Attacks on Deep Neural Networks
Dec 27, 2017
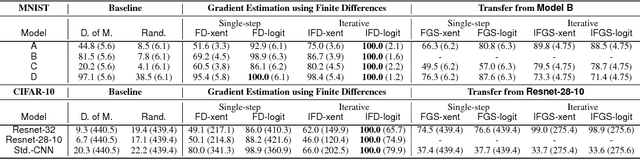
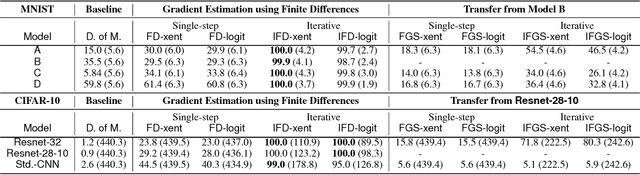
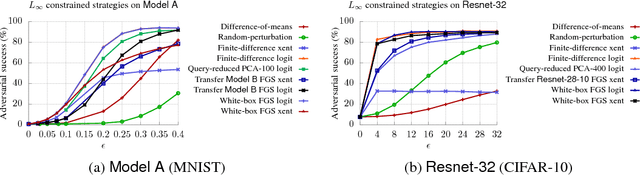
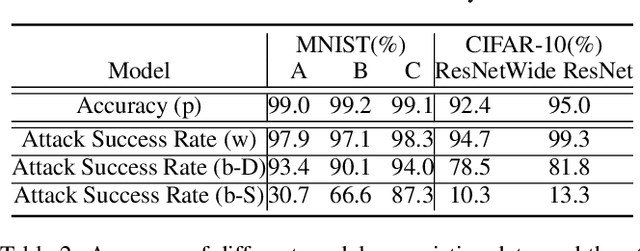
Existing black-box attacks on deep neural networks (DNNs) so far have largely focused on transferability, where an adversarial instance generated for a locally trained model can "transfer" to attack other learning models. In this paper, we propose novel Gradient Estimation black-box attacks for adversaries with query access to the target model's class probabilities, which do not rely on transferability. We also propose strategies to decouple the number of queries required to generate each adversarial sample from the dimensionality of the input. An iterative variant of our attack achieves close to 100% adversarial success rates for both targeted and untargeted attacks on DNNs. We carry out extensive experiments for a thorough comparative evaluation of black-box attacks and show that the proposed Gradient Estimation attacks outperform all transferability based black-box attacks we tested on both MNIST and CIFAR-10 datasets, achieving adversarial success rates similar to well known, state-of-the-art white-box attacks. We also apply the Gradient Estimation attacks successfully against a real-world Content Moderation classifier hosted by Clarifai. Furthermore, we evaluate black-box attacks against state-of-the-art defenses. We show that the Gradient Estimation attacks are very effective even against these defenses.
Adversarial Example Defenses: Ensembles of Weak Defenses are not Strong
Jun 15, 2017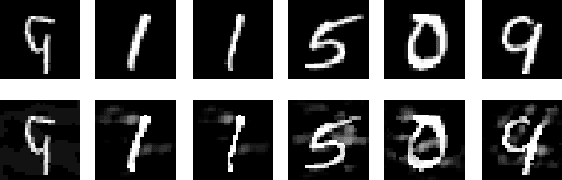


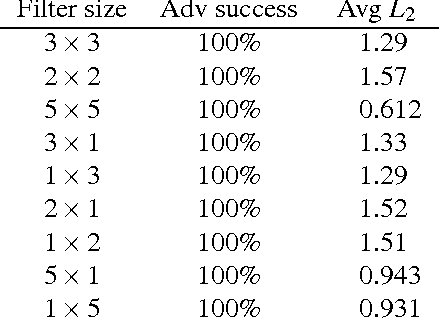
Ongoing research has proposed several methods to defend neural networks against adversarial examples, many of which researchers have shown to be ineffective. We ask whether a strong defense can be created by combining multiple (possibly weak) defenses. To answer this question, we study three defenses that follow this approach. Two of these are recently proposed defenses that intentionally combine components designed to work well together. A third defense combines three independent defenses. For all the components of these defenses and the combined defenses themselves, we show that an adaptive adversary can create adversarial examples successfully with low distortion. Thus, our work implies that ensemble of weak defenses is not sufficient to provide strong defense against adversarial examples.