 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective Learning: Back to the Future
Jan 19, 2022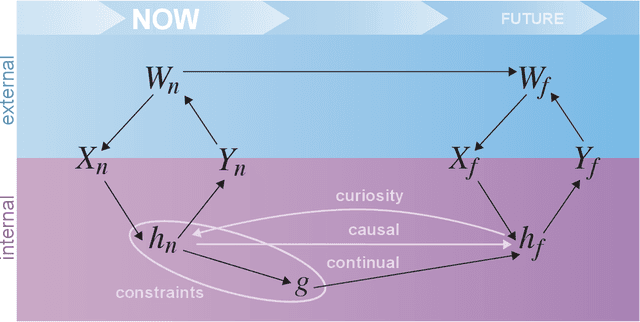

Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Robust Similarity and Distance Learning via Decision Forests
Aug 21, 2020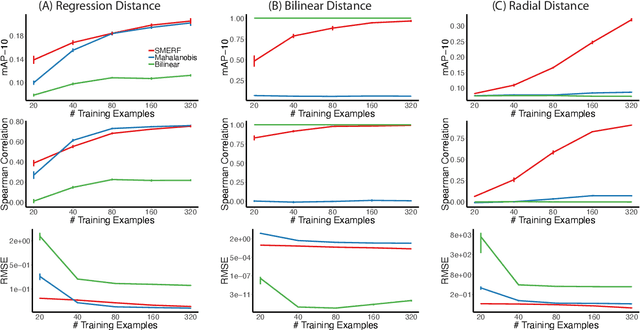
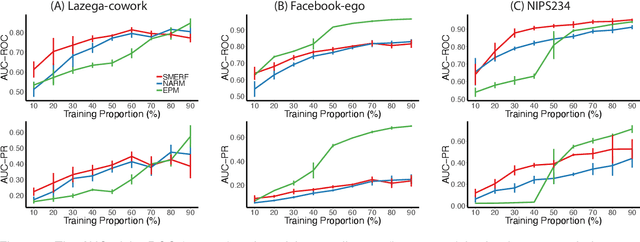
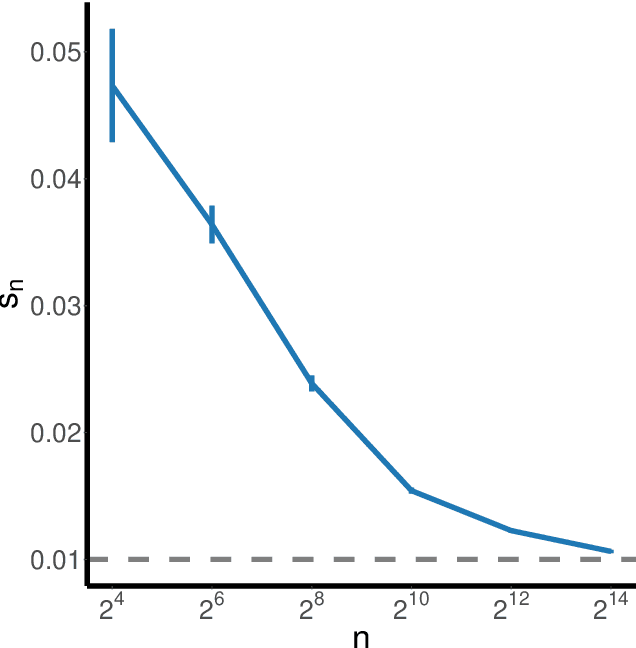
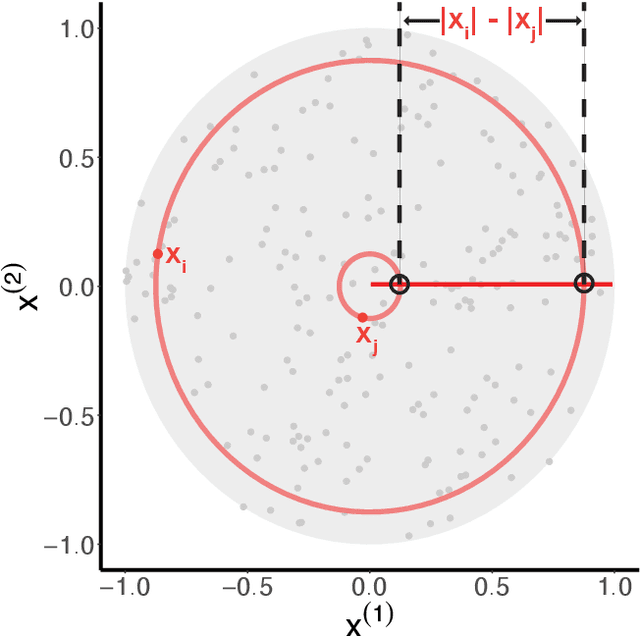
Canonical distances such as Euclidean distance often fail to capture the appropriate relationships between items, subsequently leading to subpar inference and prediction. Many algorithms have been proposed for automated learning of suitable distances, most of which employ linear methods to learn a global metric over the feature space. While such methods offer nice theoretical properties, interpretability, and computationally efficient means for implementing them, they are limited in expressive capacity. Methods which have been designed to improve expressiveness sacrifice one or more of the nice properties of the linear methods. To bridge this gap, we propose a highly expressive novel decision forest algorithm for the task of distance learning, which we call Similarity and Metric Random Forests (SMERF). We show that the tree construction procedure in SMERF is a proper generalization of standard classification and regression trees. Thus, the mathematical driving forces of SMERF are examined via its direct connection to regression forests, for which theory has been developed. Its ability to approximate arbitrary distances and identify important features is empirically demonstrated on simulated data sets. Last, we demonstrate that it accurately predicts links in networks.
Manifold Forests: Closing the Gap on Neural Networks
Sep 25, 2019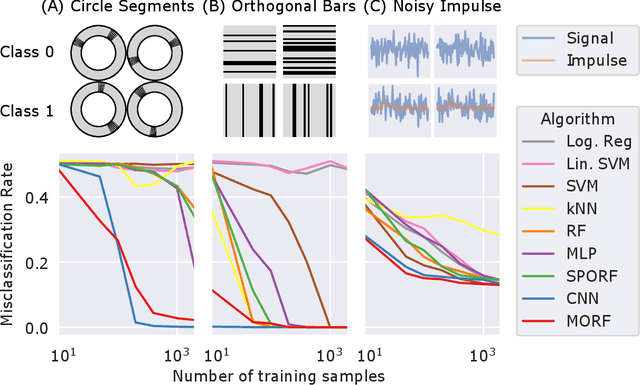
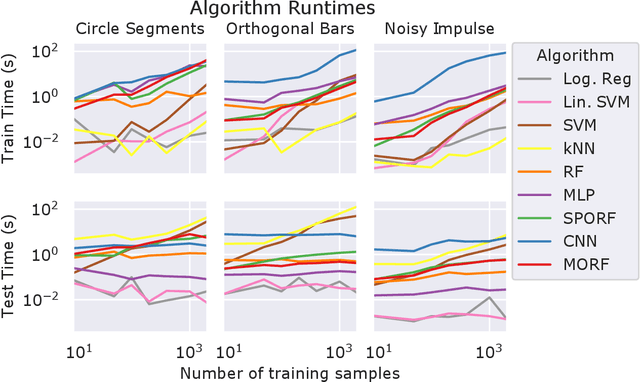
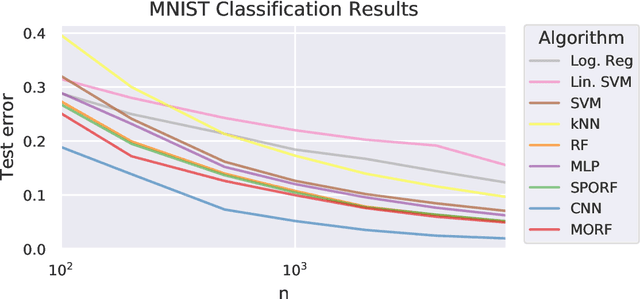
Decision forests (DF), in particular random forests and gradient boosting trees, have demonstrated state-of-the-art accuracy compared to other methods in many supervised learning scenarios. In particular, DFs dominate other methods in tabular data, that is, when the feature space is unstructured, so that the signal is invariant to permuting feature indices. However, in structured data lying on a manifold---such as images, text, and speech---neural nets (NN) tend to outperform DFs. We conjecture that at least part of the reason for this is that the input to NN is not simply the feature magnitudes, but also their indices (for example, the convolution operation uses "feature locality"). In contrast, na\"ive DF implementations fail to explicitly consider feature indices. A recently proposed DF approach demonstrates that DFs, for each node, implicitly sample a random matrix from some specific distribution. Here, we build on that to show that one can choose distributions in a \emph{manifold aware fashion}. For example, for image classification, rather than randomly selecting pixels, one can randomly select contiguous patches. We demonstrate the empirical performance of data living on three different manifolds: images, time-series, and a torus. In all three cases, our Manifold Forest (\Mf) algorithm empirically dominates other state-of-the-art approaches that ignore feature space structure, achieving a lower classification error on all sample sizes. This dominance extends to the MNIST data set as well. Moreover, both training and test time is significantly faster for manifold forests as compared to deep nets. This approach, therefore, has promise to enable DFs and other machine learning methods to close the gap with deep nets on manifold-valued data.
Random Projection Forests
Oct 10, 2018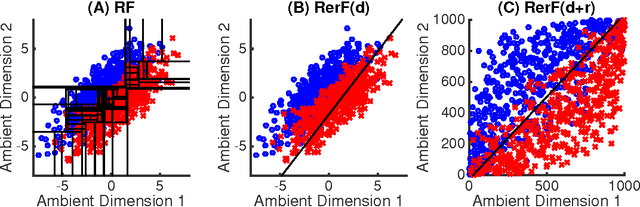
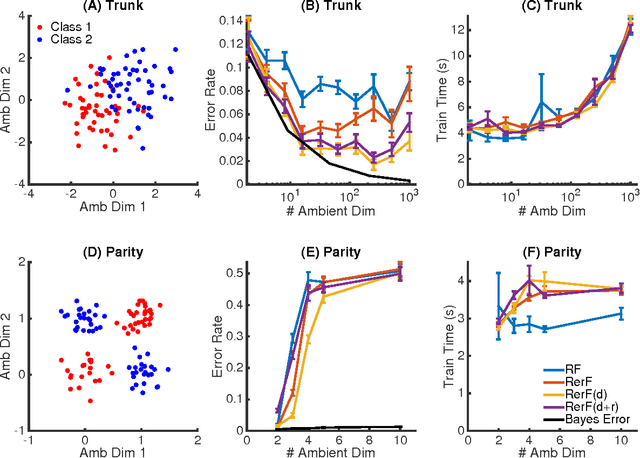
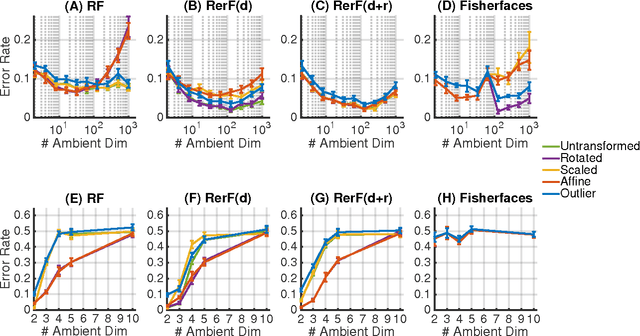
Ensemble methods---particularly those based on decision trees---have recently demonstrated superior performance in a variety of machine learning settings. We introduce a generalization of many existing decision tree methods called "Random Projection Forests" (RPF), which is any decision forest that uses (possibly data dependent and random) linear projections. Using this framework, we introduce a special case, called "Lumberjack", using very sparse random projections, that is, linear combinations of a small subset of features. Lumberjack obtains statistically significantly improved accuracy over Random Forests, Gradient Boosted Trees, and other approaches on a standard benchmark suites for classification with varying dimension, sample size, and number of classes. To illustrate how, why, and when Lumberjack outperforms other methods, we conduct extensive simulated experiments, in vectors, images, and nonlinear manifolds. Lumberjack typically yields improved performance over existing decision trees ensembles, while mitigating computational efficiency and scalability, and maintaining interpretability. Lumberjack can easily be incorporated into other ensemble methods such as boosting to obtain potentially similar gains.