 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Representation in Human-Robot Interaction with Explicit Consideration of Periodic Dynamics
Jun 16, 2021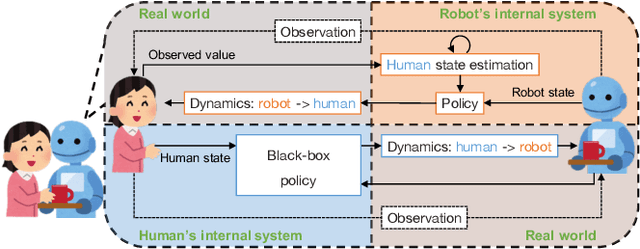
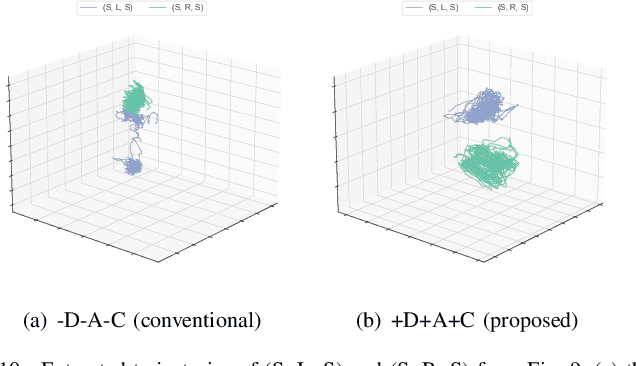
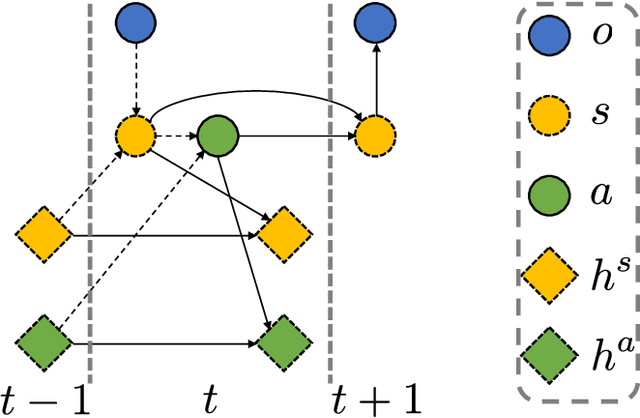
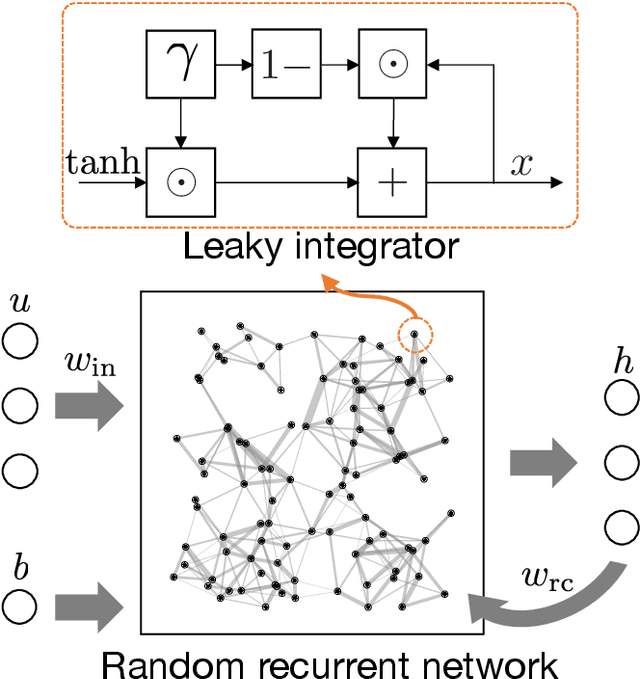
This paper presents a new data-driven framework for analyzing periodic physical human-robot interaction (pHRI) in latent state space. To elaborate human understanding and/or robot control during pHRI, the model representing pHRI is critical. Recent developments of deep learning technologies would enable us to learn such a model from a dataset collected from the actual pHRI. Our framework is developed based on variational recurrent neural network (VRNN), which can inherently handle time-series data like one pHRI generates. This paper modifies VRNN in order to include the latent dynamics from robot to human explicitly. In addition, to analyze periodic motions like walking, we integrate a new recurrent network based on reservoir computing (RC), which has random and fixed connections between numerous neurons, with VRNN. By augmenting RC into complex domain, periodic behavior can be represented as the phase rotation in complex domain without decaying the amplitude. For verification of the proposed framework, a rope-rotation/swinging experiment was analyzed. The proposed framework, trained on the dataset collected from the experiment, achieved the latent state space where the differences in periodic motions can be distinguished. Such a well-distinguished space yielded the best prediction accuracy of the human observations and the robot actions. The attached video can be seen in youtube: https://youtu.be/umn0MVcIpsY
SIGVerse: A cloud-based VR platform for research on social and embodied human-robot interaction
May 02, 2020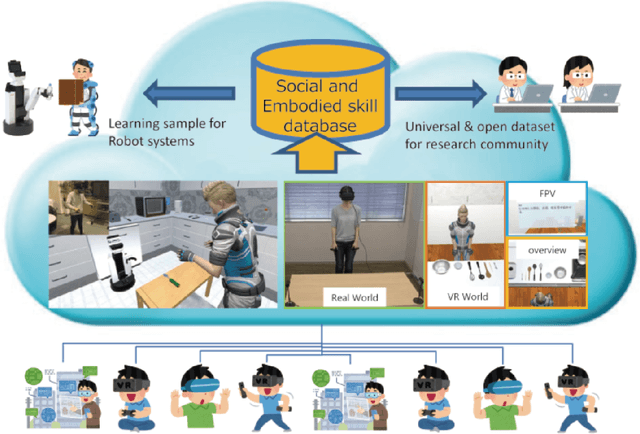

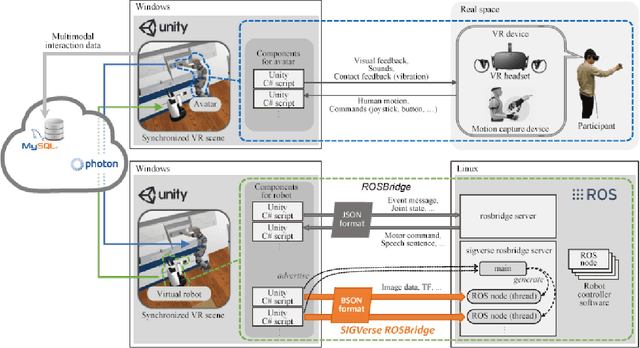

Common sense and social interaction related to daily-life environments are considerably important for autonomous robots, which support human activities. One of the practical approaches for acquiring such social interaction skills and semantic information as common sense in human activity is the application of recent machine learning techniques. Although recent machine learning techniques have been successful in realizing automatic manipulation and driving tasks, it is difficult to use these techniques in applications that require human-robot interaction experience. Humans have to perform several times over a long term to show embodied and social interaction behaviors to robots or learning systems. To address this problem, we propose a cloud-based immersive virtual reality (VR) platform which enables virtual human-robot interaction to collect the social and embodied knowledge of human activities in a variety of situations. To realize the flexible and reusable system, we develop a real-time bridging mechanism between ROS and Unity, which is one of the standard platforms for developing VR applications. We apply the proposed system to a robot competition field named RoboCup@Home to confirm the feasibility of the system in a realistic human-robot interaction scenario. Through demonstration experiments at the competition, we show the usefulness and potential of the system for the development and evaluation of social intelligence through human-robot interaction. The proposed VR platform enables robot systems to collect social experiences with several users in a short time. The platform also contributes in providing a dataset of social behaviors, which would be a key aspect for intelligent service robots to acquire social interaction skills based on machine learning techniques.
Spatial Concept-Based Navigation with Human Speech Instructions via Probabilistic Inference on Bayesian Generative Model
Feb 18, 2020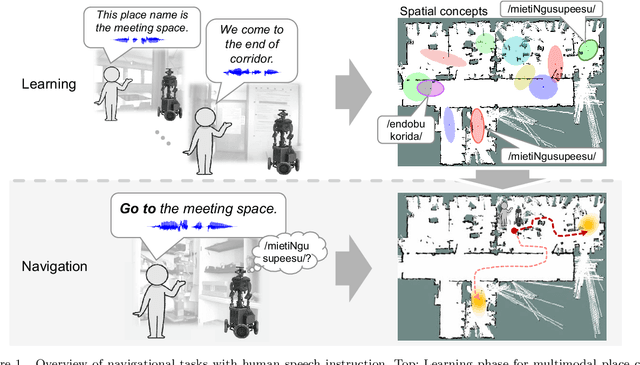

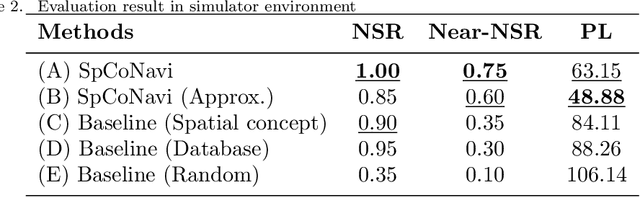
Robots are required to not only learn spatial concepts autonomously but also utilize such knowledge for various tasks in a domestic environment. Spatial concept represents a multimodal place category acquired from the robot's spatial experience including vision, speech-language, and self-position. The aim of this study is to enable a mobile robot to perform navigational tasks with human speech instructions, such as `Go to the kitchen', via probabilistic inference on a Bayesian generative model using spatial concepts. Specifically, path planning was formalized as the maximization of probabilistic distribution on the path-trajectory under speech instruction, based on a control-as-inference framework. Furthermore, we described the relationship between probabilistic inference based on the Bayesian generative model and control problem including reinforcement learning. We demonstrated path planning based on human instruction using acquired spatial concepts to verify the usefulness of the proposed approach in the simulator and in real environments. Experimentally, places instructed by the user's speech commands showed high probability values, and the trajectory toward the target place was correctly estimated. Our approach, based on probabilistic inference concerning decision-making, can lead to further improvement in robot autonomy.
Learning multimodal representations for sample-efficient recognition of human actions
Mar 06, 2019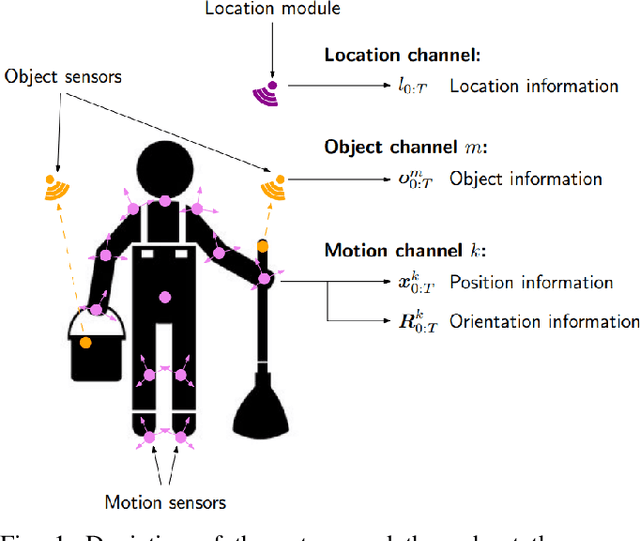
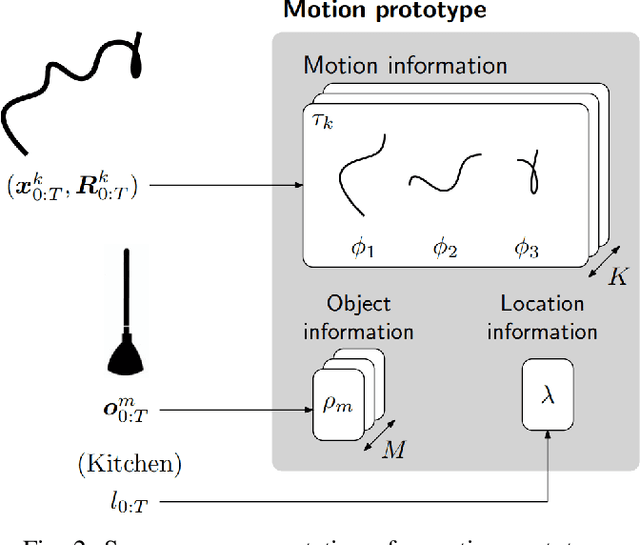
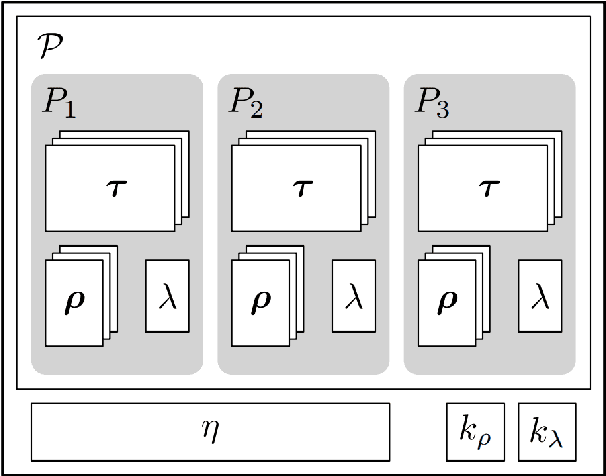

Humans interact in rich and diverse ways with the environment. However, the representation of such behavior by artificial agents is often limited. In this work we present \textit{motion concepts}, a novel multimodal representation of human actions in a household environment. A motion concept encompasses a probabilistic description of the kinematics of the action along with its contextual background, namely the location and the objects held during the performance. Furthermore, we present Online Motion Concept Learning (OMCL), a new algorithm which learns novel motion concepts from action demonstrations and recognizes previously learned motion concepts. The algorithm is evaluated on a virtual-reality household environment with the presence of a human avatar. OMCL outperforms standard motion recognition algorithms on an one-shot recognition task, attesting to its potential for sample-efficient recognition of human actions.
Improved and Scalable Online Learning of Spatial Concepts and Language Models with Mapping
Jan 04, 2019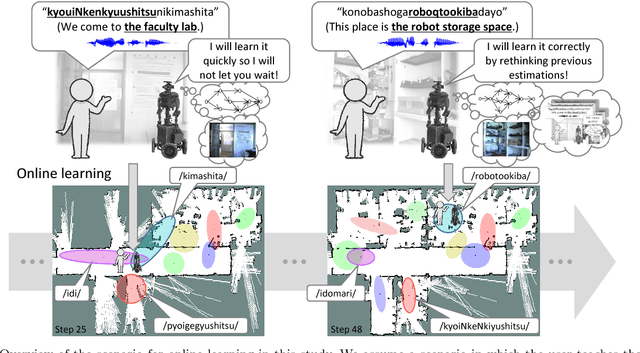

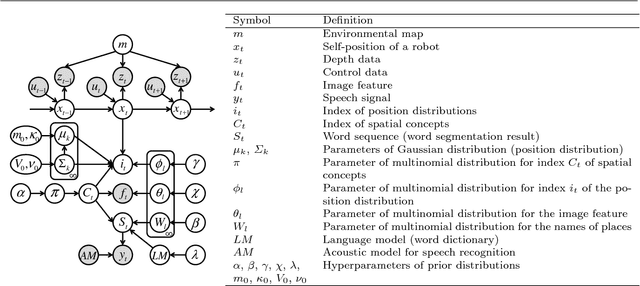
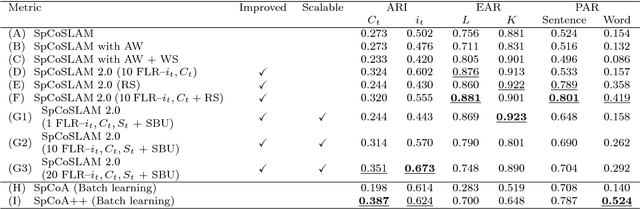
We propose a novel online learning algorithm, called SpCoSLAM 2.0, for spatial concepts and lexical acquisition with high accuracy and scalability. Previously, we proposed SpCoSLAM as an online learning algorithm based on unsupervised Bayesian probabilistic model that integrates multimodal place categorization, lexical acquisition, and SLAM. However, our previous algorithm had limited estimation accuracy owing to the influence of the early stages of learning, and increased computational complexity with added training data. Therefore, we introduce techniques such as fixed-lag rejuvenation to reduce the calculation time while maintaining an accuracy higher than that of the previous algorithm. The results show that, in terms of estimation accuracy, the proposed algorithm exceeds the previous algorithm and is comparable to batch learning. In addition, the calculation time of the proposed algorithm does not depend on the amount of training data and becomes constant for each step of the scalable algorithm. Our approach will contribute to the realization of long-term spatial language interactions between humans and robots.
Online Spatial Concept and Lexical Acquisition with Simultaneous Localization and Mapping
Mar 09, 2018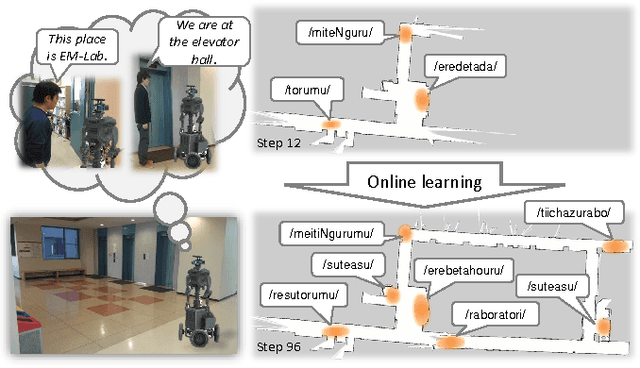
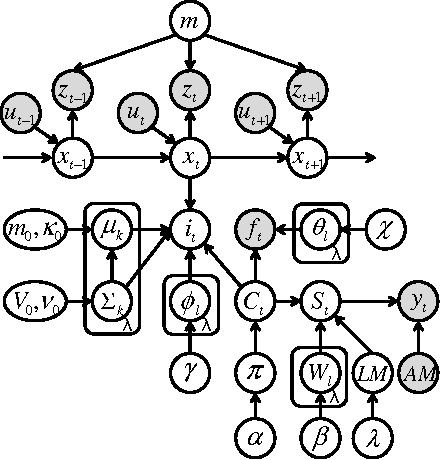
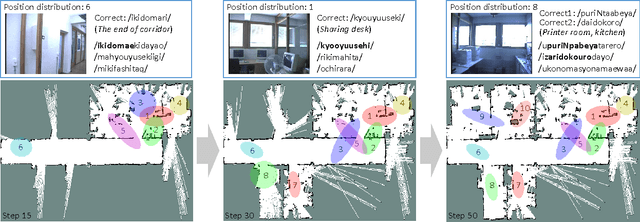
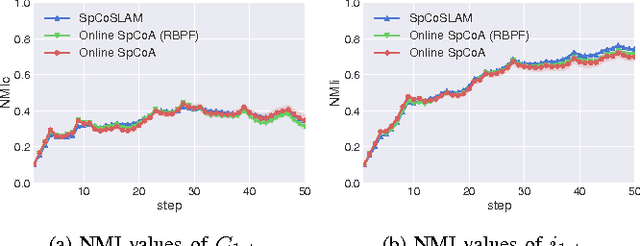
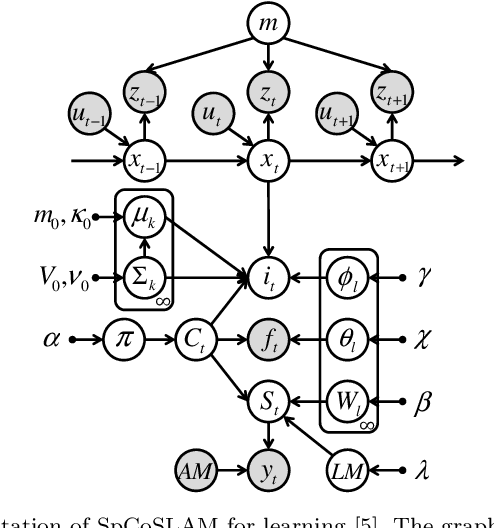
In this paper, we propose an online learning algorithm based on a Rao-Blackwellized particle filter for spatial concept acquisition and mapping. We have proposed a nonparametric Bayesian spatial concept acquisition model (SpCoA). We propose a novel method (SpCoSLAM) integrating SpCoA and FastSLAM in the theoretical framework of the Bayesian generative model. The proposed method can simultaneously learn place categories and lexicons while incrementally generating an environmental map. Furthermore, the proposed method has scene image features and a language model added to SpCoA. In the experiments, we tested online learning of spatial concepts and environmental maps in a novel environment of which the robot did not have a map. Then, we evaluated the results of online learning of spatial concepts and lexical acquisition. The experimental results demonstrated that the robot was able to more accurately learn the relationships between words and the place in the environmental map incrementally by using the proposed method.
Bayesian Body Schema Estimation using Tactile Information obtained through Coordinated Random Movements
Dec 01, 2016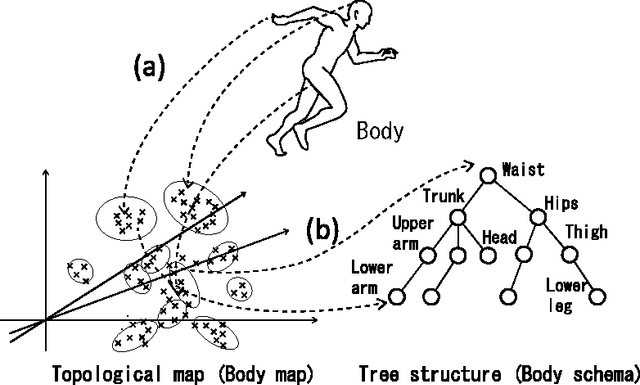

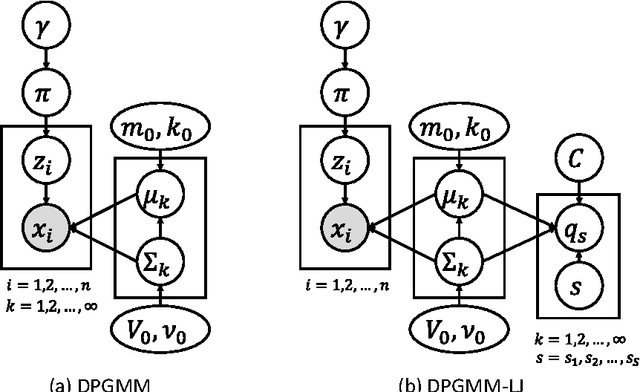

This paper describes a computational model, called the Dirichlet process Gaussian mixture model with latent joints (DPGMM-LJ), that can find latent tree structure embedded in data distribution in an unsupervised manner. By combining DPGMM-LJ and a pre-existing body map formation method, we propose a method that enables an agent having multi-link body structure to discover its kinematic structure, i.e., body schema, from tactile information alone. The DPGMM-LJ is a probabilistic model based on Bayesian nonparametrics and an extension of Dirichlet process Gaussian mixture model (DPGMM). In a simulation experiment, we used a simple fetus model that had five body parts and performed structured random movements in a womb-like environment. It was shown that the method could estimate the number of body parts and kinematic structures without any pre-existing knowledge in many cases. Another experiment showed that the degree of motor coordination in random movements affects the result of body schema formation strongly. It is confirmed that the accuracy rate for body schema estimation had the highest value 84.6% when the ratio of motor coordination was 0.9 in our setting. These results suggest that kinematic structure can be estimated from tactile information obtained by a fetus moving randomly in a womb without any visual information even though its accuracy was not so high. They also suggest that a certain degree of motor coordination in random movements and the sufficient dimension of state space that represents the body map are important to estimate body schema correctly.
Spatial Concept Acquisition for a Mobile Robot that Integrates Self-Localization and Unsupervised Word Discovery from Spoken Sentences
May 07, 2016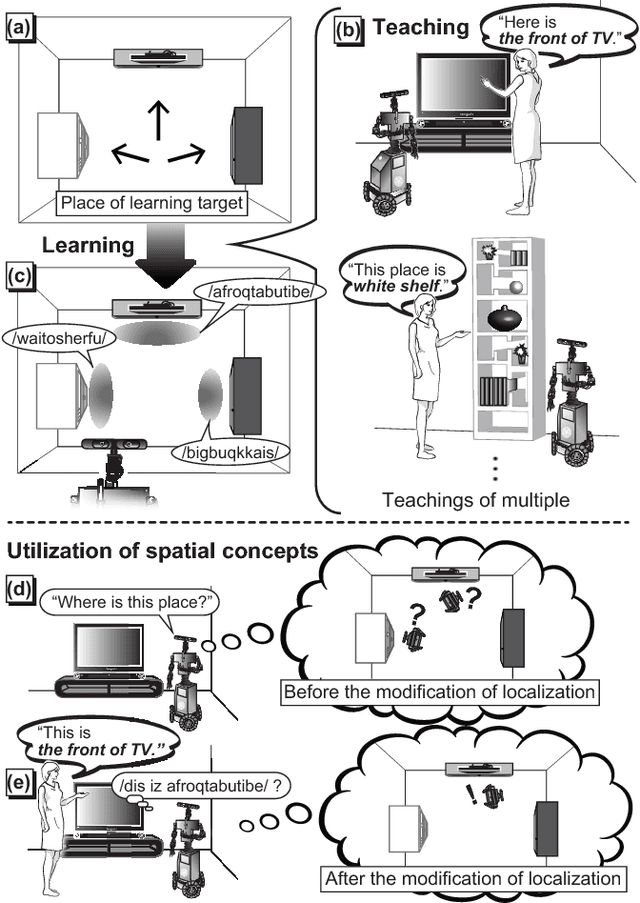
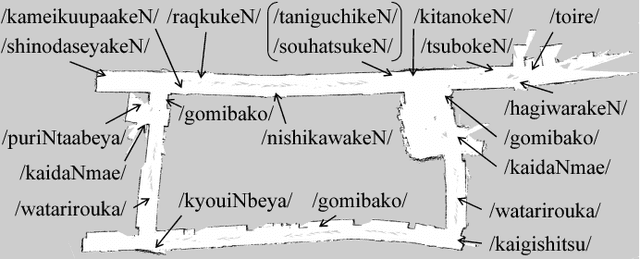
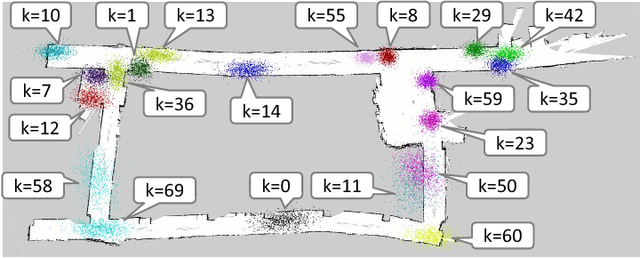
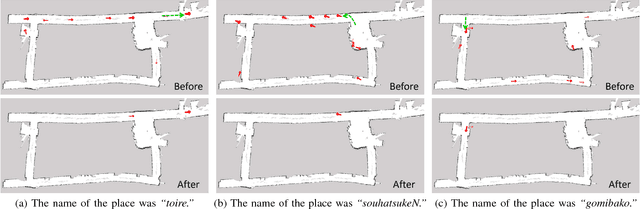
In this paper, we propose a novel unsupervised learning method for the lexical acquisition of words related to places visited by robots, from human continuous speech signals. We address the problem of learning novel words by a robot that has no prior knowledge of these words except for a primitive acoustic model. Further, we propose a method that allows a robot to effectively use the learned words and their meanings for self-localization tasks. The proposed method is nonparametric Bayesian spatial concept acquisition method (SpCoA) that integrates the generative model for self-localization and the unsupervised word segmentation in uttered sentences via latent variables related to the spatial concept. We implemented the proposed method SpCoA on SIGVerse, which is a simulation environment, and TurtleBot2, which is a mobile robot in a real environment. Further, we conducted experiments for evaluating the performance of SpCoA. The experimental results showed that SpCoA enabled the robot to acquire the names of places from speech sentences. They also revealed that the robot could effectively utilize the acquired spatial concepts and reduce the uncertainty in self-localization.