 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriLens: Semantic Retrieval in Agricultural Texts Using Topic Modeling and Language Models
Jan 13, 2026As the volume of unstructured text continues to grow across domains, there is an urgent need for scalable methods that enable interpretable organization, summarization, and retrieval of information. This work presents a unified framework for interpretable topic modeling, zero-shot topic labeling, and topic-guided semantic retrieval over large agricultural text corpora. Leveraging BERTopic, we extract semantically coherent topics. Each topic is converted into a structured prompt, enabling a language model to generate meaningful topic labels and summaries in a zero-shot manner. Querying and document exploration are supported via dense embeddings and vector search, while a dedicated evaluation module assesses topical coherence and bias. This framework supports scalable and interpretable information access in specialized domains where labeled data is limited.
Stacked ensemble\-based mutagenicity prediction model using multiple modalities with graph attention network
Sep 04, 2024



Mutagenicity is a concern due to its association with genetic mutations which can result in a variety of negative consequences, including the development of cancer. Earlier identification of mutagenic compounds in the drug development process is therefore crucial for preventing the progression of unsafe candidates and reducing development costs. While computational techniques, especially machine learning models have become increasingly prevalent for this endpoint, they rely on a single modality. In this work, we introduce a novel stacked ensemble based mutagenicity prediction model which incorporate multiple modalities such as simplified molecular input line entry system (SMILES) and molecular graph. These modalities capture diverse information about molecules such as substructural, physicochemical, geometrical and topological. To derive substructural, geometrical and physicochemical information, we use SMILES, while topological information is extracted through a graph attention network (GAT) via molecular graph. Our model uses a stacked ensemble of machine learning classifiers to make predictions using these multiple features. We employ the explainable artificial intelligence (XAI) technique SHAP (Shapley Additive Explanations) to determine the significance of each classifier and the most relevant features in the prediction. We demonstrate that our method surpasses SOTA methods on two standard datasets across various metrics. Notably, we achieve an area under the curve of 95.21\% on the Hansen benchmark dataset, affirming the efficacy of our method in predicting mutagenicity. We believe that this research will captivate the interest of both clinicians and computational biologists engaged in translational research.
Advancements in Molecular Property Prediction: A Survey of Single and Multimodal Approaches
Aug 22, 2024
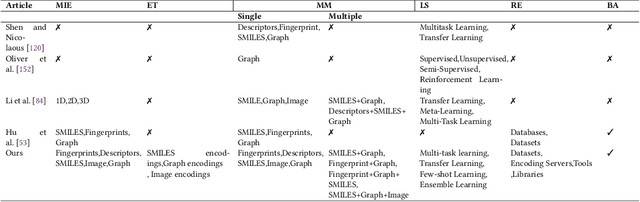
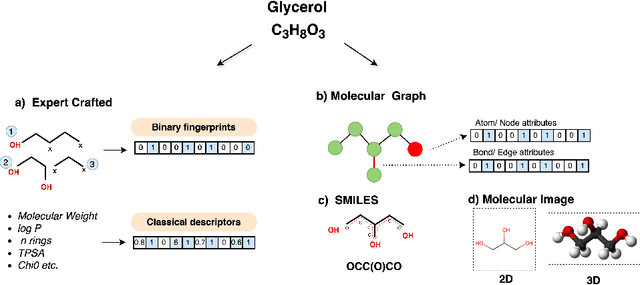

Molecular Property Prediction (MPP) plays a pivotal role across diverse domains, spanning drug discovery, material science, and environmental chemistry. Fueled by the exponential growth of chemical data and the evolution of artificial intelligence, recent years have witnessed remarkable strides in MPP. However, the multifaceted nature of molecular data, such as molecular structures, SMILES notation, and molecular images, continues to pose a fundamental challenge in its effective representation. To address this, representation learning techniques are instrumental as they acquire informative and interpretable representations of molecular data. This article explores recent AI/-based approaches in MPP, focusing on both single and multiple modality representation techniques. It provides an overview of various molecule representations and encoding schemes, categorizes MPP methods by their use of modalities, and outlines datasets and tools available for feature generation. The article also analyzes the performance of recent methods and suggests future research directions to advance the field of MPP.
Exploring learning environments for label\-efficient cancer diagnosis
Aug 15, 2024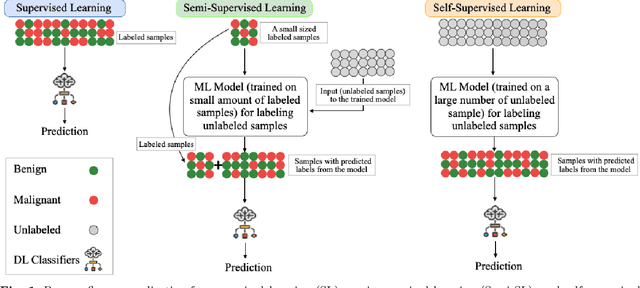
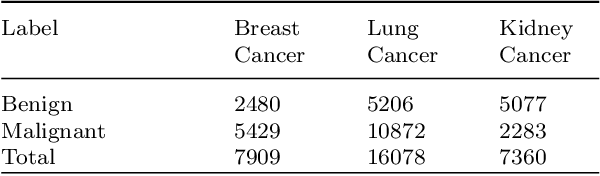
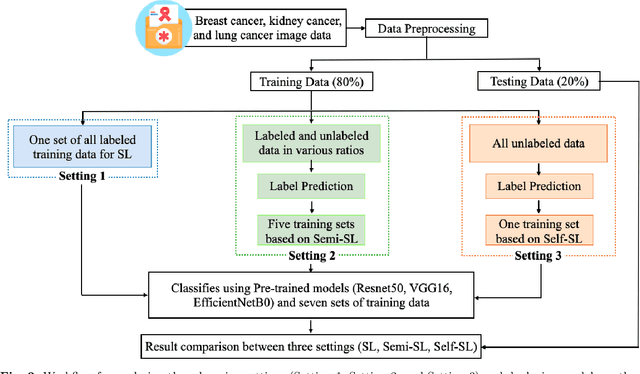
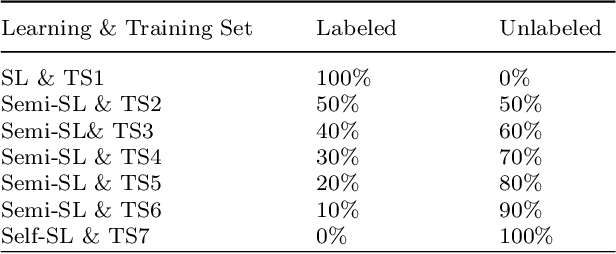
Despite significant research efforts and advancements, cancer remains a leading cause of mortality. Early cancer prediction has become a crucial focus in cancer research to streamline patient care and improve treatment outcomes. Manual tumor detection by histopathologists can be time consuming, prompting the need for computerized methods to expedite treatment planning. Traditional approaches to tumor detection rely on supervised learning, necessitates a large amount of annotated data for model training. However, acquiring such extensive labeled data can be laborious and time\-intensive. This research examines the three learning environments: supervised learning (SL), semi\-supervised learning (Semi\-SL), and self\-supervised learning (Self\-SL): to predict kidney, lung, and breast cancer. Three pre\-trained deep learning models (Residual Network\-50, Visual Geometry Group\-16, and EfficientNetB0) are evaluated based on these learning settings using seven carefully curated training sets. To create the first training set (TS1), SL is applied to all annotated image samples. Five training sets (TS2\-TS6) with different ratios of labeled and unlabeled cancer images are used to evaluateSemi\-SL. Unlabeled cancer images from the final training set (TS7) are utilized for Self\-SL assessment. Among different learning environments, outcomes from the Semi\-SL setting show a strong degree of agreement with the outcomes achieved in the SL setting. The uniform pattern of observations from the pre\-trained models across all three datasets validates the methodology and techniques of the research. Based on modest number of labeled samples and minimal computing cost, our study suggests that the Semi\-SL option can be a highly viable replacement for the SL option under label annotation constraint scenarios.
DACB-Net: Dual Attention Guided Compact Bilinear Convolution Neural Network for Skin Disease Classification
Jul 03, 2024
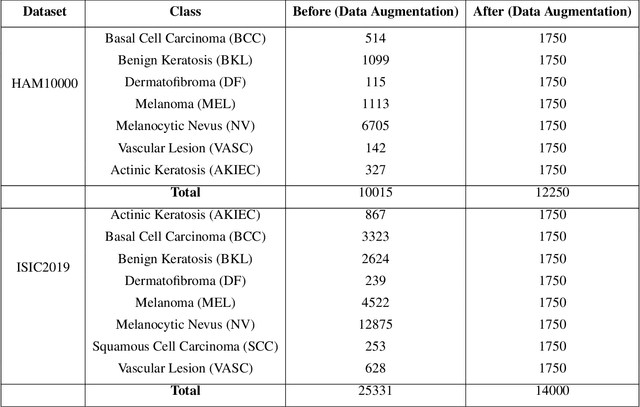
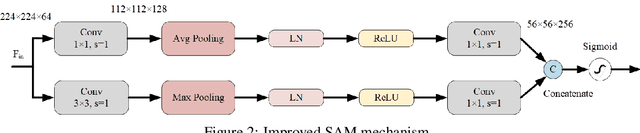
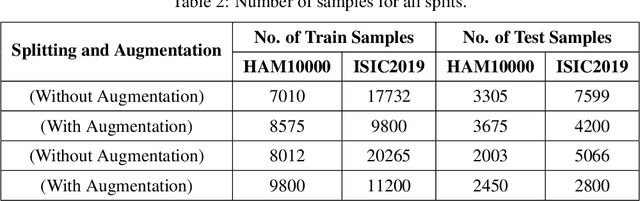
This paper introduces the three-branch Dual Attention-Guided Compact Bilinear CNN (DACB-Net) by focusing on learning from disease-specific regions to enhance accuracy and alignment. A global branch compensates for lost discriminative features, generating Attention Heat Maps (AHM) for relevant cropped regions. Finally, the last pooling layers of global and local branches are concatenated for fine-tuning, which offers a comprehensive solution to the challenges posed by skin disease diagnosis. Although current CNNs employ Stochastic Gradient Descent (SGD) for discriminative feature learning, using distinct pairs of local image patches to compute gradients and incorporating a modulation factor in the loss for focusing on complex data during training. However, this approach can lead to dataset imbalance, weight adjustments, and vulnerability to overfitting. The proposed solution combines two supervision branches and a novel loss function to address these issues, enhancing performance and interpretability. The framework integrates data augmentation, transfer learning, and fine-tuning to tackle data imbalance to improve classification performance, and reduce computational costs. Simulations on the HAM10000 and ISIC2019 datasets demonstrate the effectiveness of this approach, showcasing a 2.59% increase in accuracy compared to the state-of-the-art.
Bilinear-Convolutional Neural Network Using a Matrix Similarity-based Joint Loss Function for Skin Disease Classification
Jun 02, 2024


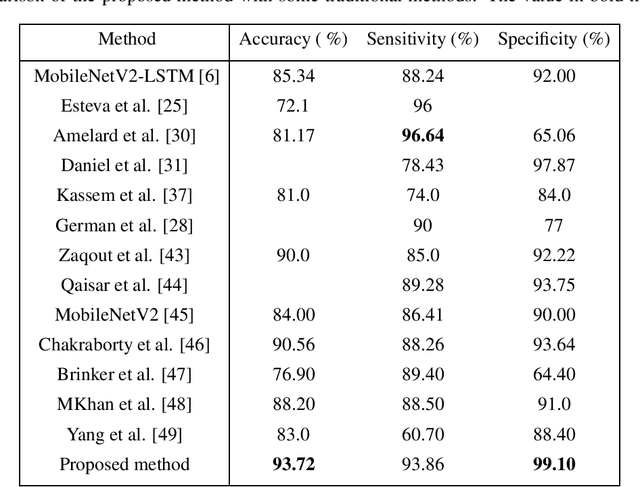
In this study, we proposed a model for skin disease classification using a Bilinear Convolutional Neural Network (BCNN) with a Constrained Triplet Network (CTN). BCNN can capture rich spatial interactions between features in image data. This computes the outer product of feature vectors from two different CNNs by a bilinear pooling. The resulting features encode second-order statistics, enabling the network to capture more complex relationships between different channels and spatial locations. The CTN employs the Triplet Loss Function (TLF) by using a new loss layer that is added at the end of the architecture called the Constrained Triplet Loss (CTL) layer. This is done to obtain two significant learning objectives: inter-class categorization and intra-class concentration with their deep features as often as possible, which can be effective for skin disease classification. The proposed model is trained to extract the intra-class features from a deep network and accordingly increases the distance between these features, improving the model's performance. The model achieved a mean accuracy of 93.72%.
JMI at SemEval 2024 Task 3: Two-step approach for multimodal ECAC using in-context learning with GPT and instruction-tuned Llama models
Mar 05, 2024This paper presents our system development for SemEval-2024 Task 3: "The Competition of Multimodal Emotion Cause Analysis in Conversations". Effectively capturing emotions in human conversations requires integrating multiple modalities such as text, audio, and video. However, the complexities of these diverse modalities pose challenges for developing an efficient multimodal emotion cause analysis (ECA) system. Our proposed approach addresses these challenges by a two-step framework. We adopt two different approaches in our implementation. In Approach 1, we employ instruction-tuning with two separate Llama 2 models for emotion and cause prediction. In Approach 2, we use GPT-4V for conversation-level video description and employ in-context learning with annotated conversation using GPT 3.5. Our system wins rank 4, and system ablation experiments demonstrate that our proposed solutions achieve significant performance gains. All the experimental codes are available on Github.
Language Identification of Hindi-English tweets using code-mixed BERT
Jul 02, 2021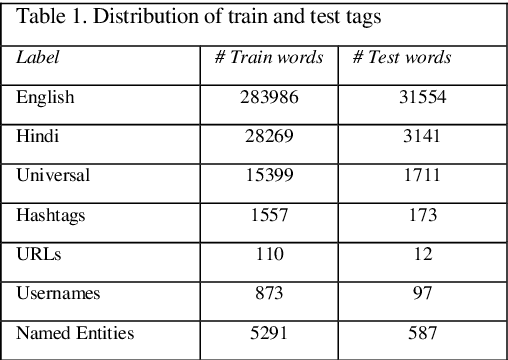
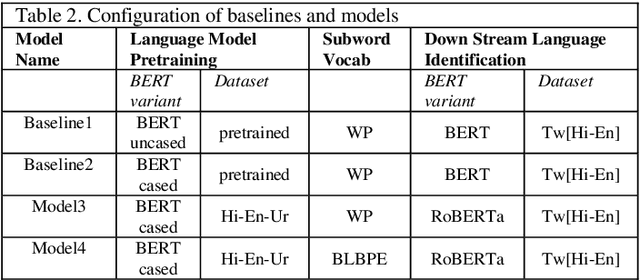
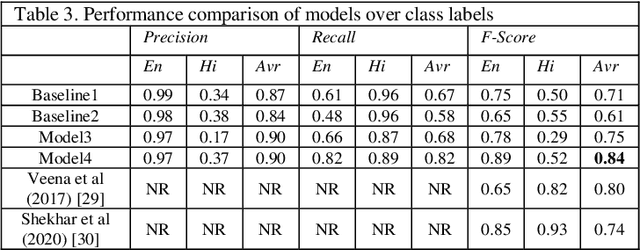
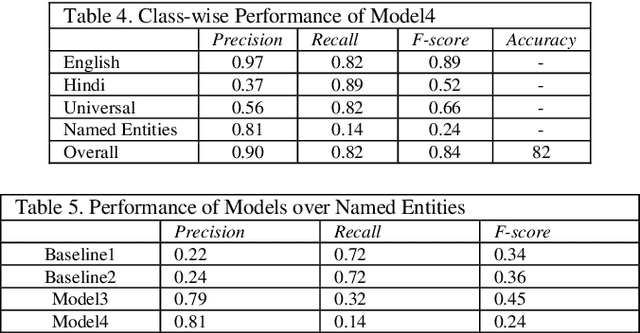
Language identification of social media text has been an interesting problem of study in recent years. Social media messages are predominantly in code mixed in non-English speaking states. Prior knowledge by pre-training contextual embeddings have shown state of the art results for a range of downstream tasks. Recently, models such as BERT have shown that using a large amount of unlabeled data, the pretrained language models are even more beneficial for learning common language representations. Extensive experiments exploiting transfer learning and fine-tuning BERT models to identify language on Twitter are presented in this paper. The work utilizes a data collection of Hindi-English-Urdu codemixed text for language pre-training and Hindi-English codemixed for subsequent word-level language classification. The results show that the representations pre-trained over codemixed data produce better results by their monolingual counterpart.
Language Lexicons for Hindi-English Multilingual Text Processing
Jun 29, 2021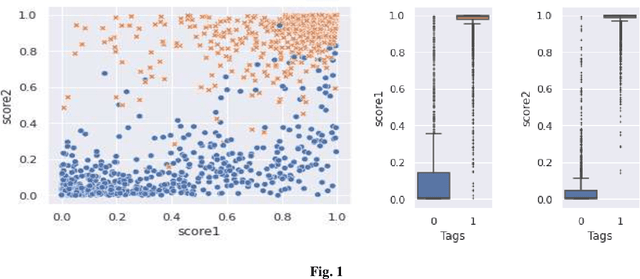
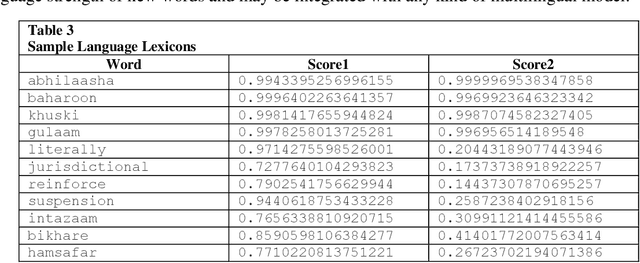
Language Identification in textual documents is the process of automatically detecting the language contained in a document based on its content. The present Language Identification techniques presume that a document contains text in one of the fixed set of languages, however, this presumption is incorrect when dealing with multilingual document which includes content in more than one possible language. Due to the unavailability of large standard corpora for Hindi-English mixed lingual language processing tasks we propose the language lexicons, a novel kind of lexical database that supports several multilingual language processing tasks. These lexicons are built by learning classifiers over transliterated Hindi and English vocabulary. The designed lexicons possess richer quantitative characteristic than its primary source of collection which is revealed using the visualization techniques.
A Simple and Efficient Probabilistic Language model for Code-Mixed Text
Jun 29, 2021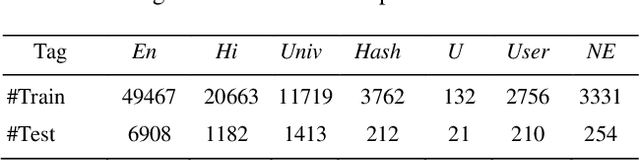
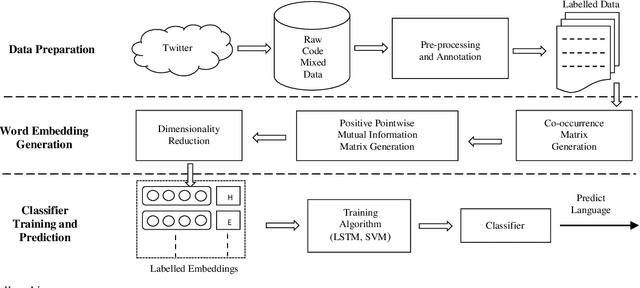
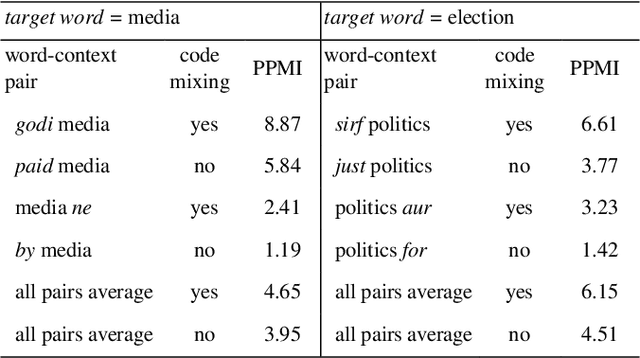
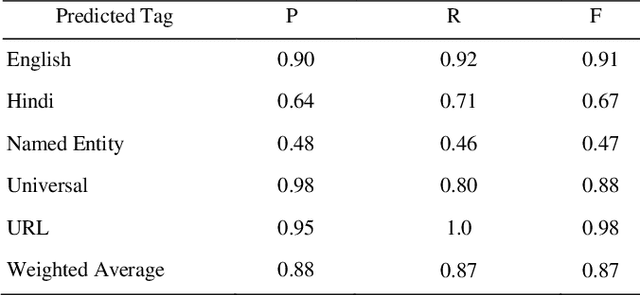
The conventional natural language processing approaches are not accustomed to the social media text due to colloquial discourse and non-homogeneous characteristics. Significantly, the language identification in a multilingual document is ascertained to be a preceding subtask in several information extraction applications such as information retrieval, named entity recognition, relation extraction, etc. The problem is often more challenging in code-mixed documents wherein foreign languages words are drawn into base language while framing the text. The word embeddings are powerful language modeling tools for representation of text documents useful in obtaining similarity between words or documents. We present a simple probabilistic approach for building efficient word embedding for code-mixed text and exemplifying it over language identification of Hindi-English short test messages scrapped from Twitter. We examine its efficacy for the classification task using bidirectional LSTMs and SVMs and observe its improved scores over various existing code-mixed embeddings