 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Efficient Probabilistic Language model for Code-Mixed Text
Paper and Code
Jun 29, 2021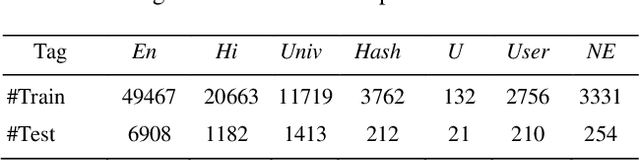
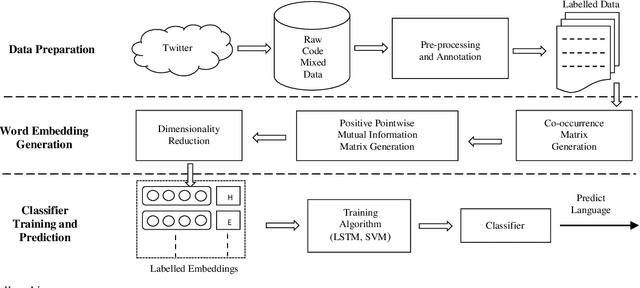
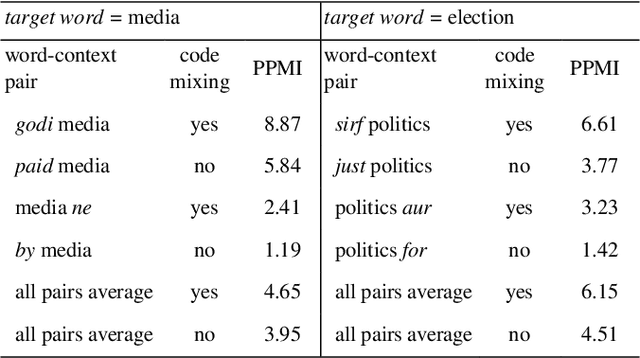
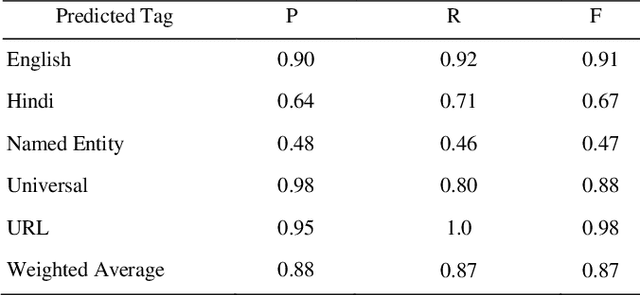
The conventional natural language processing approaches are not accustomed to the social media text due to colloquial discourse and non-homogeneous characteristics. Significantly, the language identification in a multilingual document is ascertained to be a preceding subtask in several information extraction applications such as information retrieval, named entity recognition, relation extraction, etc. The problem is often more challenging in code-mixed documents wherein foreign languages words are drawn into base language while framing the text. The word embeddings are powerful language modeling tools for representation of text documents useful in obtaining similarity between words or documents. We present a simple probabilistic approach for building efficient word embedding for code-mixed text and exemplifying it over language identification of Hindi-English short test messages scrapped from Twitter. We examine its efficacy for the classification task using bidirectional LSTMs and SVMs and observe its improved scores over various existing code-mixed embeddings