 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Relationships-based Regularizer for Retinal Vessel Image Segmentation
Dec 28, 2022The task of image segmentation is to classify each pixel in the image based on the appropriate label. Various deep learning approaches have been proposed for image segmentation that offers high accuracy and deep architecture. However, the deep learning technique uses a pixel-wise loss function for the training process. Using pixel-wise loss neglected the pixel neighbor relationships in the network learning process. The neighboring relationship of the pixels is essential information in the image. Utilizing neighboring pixel information provides an advantage over using only pixel-to-pixel information. This study presents regularizers to give the pixel neighbor relationship information to the learning process. The regularizers are constructed by the graph theory approach and topology approach: By graph theory approach, graph Laplacian is used to utilize the smoothness of segmented images based on output images and ground-truth images. By topology approach, Euler characteristic is used to identify and minimize the number of isolated objects on segmented images. Experiments show that our scheme successfully captures pixel neighbor relations and improves the performance of the convolutional neural network better than the baseline without a regularization term.
Single-Image Super-Resolution Reconstruction based on the Differences of Neighboring Pixels
Dec 28, 2022The deep learning technique was used to increase the performance of single image super-resolution (SISR). However, most existing CNN-based SISR approaches primarily focus on establishing deeper or larger networks to extract more significant high-level features. Usually, the pixel-level loss between the target high-resolution image and the estimated image is used, but the neighbor relations between pixels in the image are seldom used. On the other hand, according to observations, a pixel's neighbor relationship contains rich information about the spatial structure, local context, and structural knowledge. Based on this fact, in this paper, we utilize pixel's neighbor relationships in a different perspective, and we propose the differences of neighboring pixels to regularize the CNN by constructing a graph from the estimated image and the ground-truth image. The proposed method outperforms the state-of-the-art methods in terms of quantitative and qualitative evaluation of the benchmark datasets. Keywords: Super-resolution, Convolutional Neural Networks, Deep Learning
Attention-effective multiple instance learning on weakly stem cell colony segmentation
Mar 09, 2022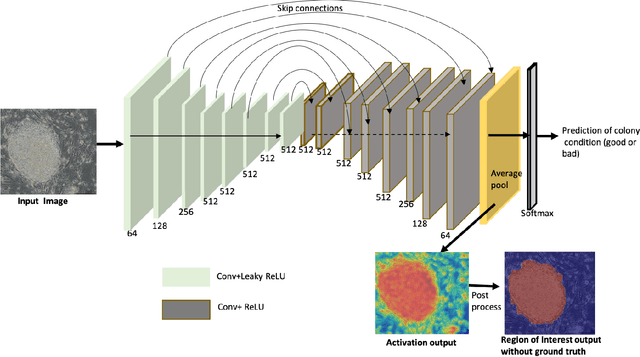
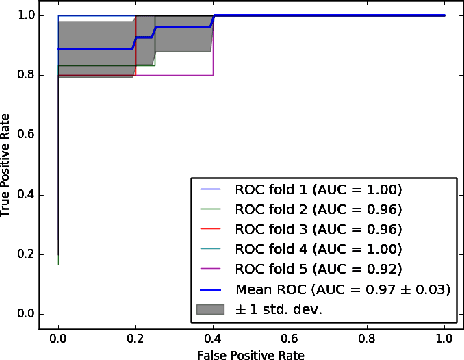
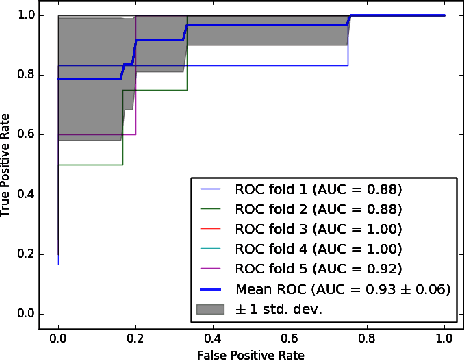
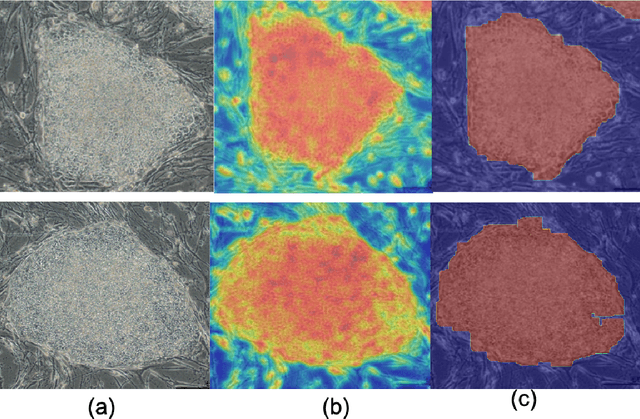
The detection of induced pluripotent stem cell (iPSC) colonies often needs the precise extraction of the colony features. However, existing computerized systems relied on segmentation of contours by preprocessing for classifying the colony conditions were task-extensive. To maximize the efficiency in categorizing colony conditions, we propose a multiple instance learning (MIL) in weakly supervised settings. It is designed in a single model to produce weak segmentation and classification of colonies without using finely labeled samples. As a single model, we employ a U-net-like convolution neural network (CNN) to train on binary image-level labels for MIL colonies classification. Furthermore, to specify the object of interest we used a simple post-processing method. The proposed approach is compared over conventional methods using five-fold cross-validation and receiver operating characteristic (ROC) curve. The maximum accuracy of the MIL-net is 95%, which is 15 % higher than the conventional methods. Furthermore, the ability to interpret the location of the iPSC colonies based on the image level label without using a pixel-wise ground truth image is more appealing and cost-effective in colony condition recognition.
Weakly-Supervised Action Localization and Action Recognition using Global-Local Attention of 3D CNN
Dec 17, 2020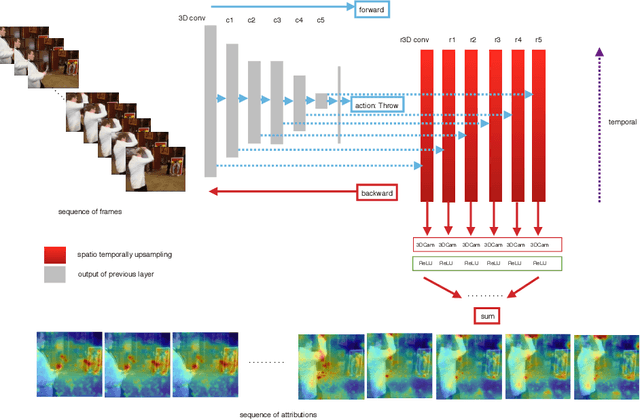

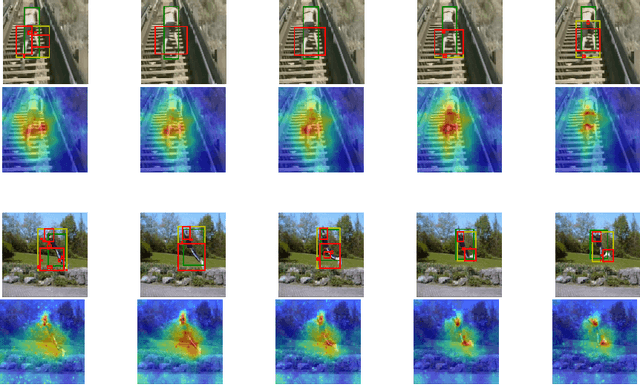

3D Convolutional Neural Network (3D CNN) captures spatial and temporal information on 3D data such as video sequences. However, due to the convolution and pooling mechanism, the information loss seems unavoidable. To improve the visual explanations and classification in 3D CNN, we propose two approaches; i) aggregate layer-wise global to local (global-local) discrete gradients using trained 3DResNext network, and ii) implement attention gating network to improve the accuracy of the action recognition. The proposed approach intends to show the usefulness of every layer termed as global-local attention in 3D CNN via visual attribution, weakly-supervised action localization, and action recognition. Firstly, the 3DResNext is trained and applied for action classification using backpropagation concerning the maximum predicted class. The gradients and activations of every layer are then up-sampled. Later, aggregation is used to produce more nuanced attention, which points out the most critical part of the predicted class's input videos. We use contour thresholding of final attention for final localization. We evaluate spatial and temporal action localization in trimmed videos using fine-grained visual explanation via 3DCam. Experimental results show that the proposed approach produces informative visual explanations and discriminative attention. Furthermore, the action recognition via attention gating on each layer produces better classification results than the baseline model.
q-SNE: Visualizing Data using q-Gaussian Distributed Stochastic Neighbor Embedding
Dec 02, 2020
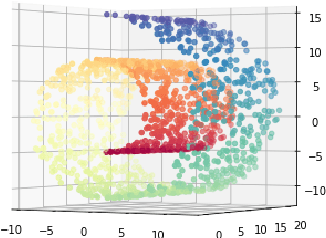
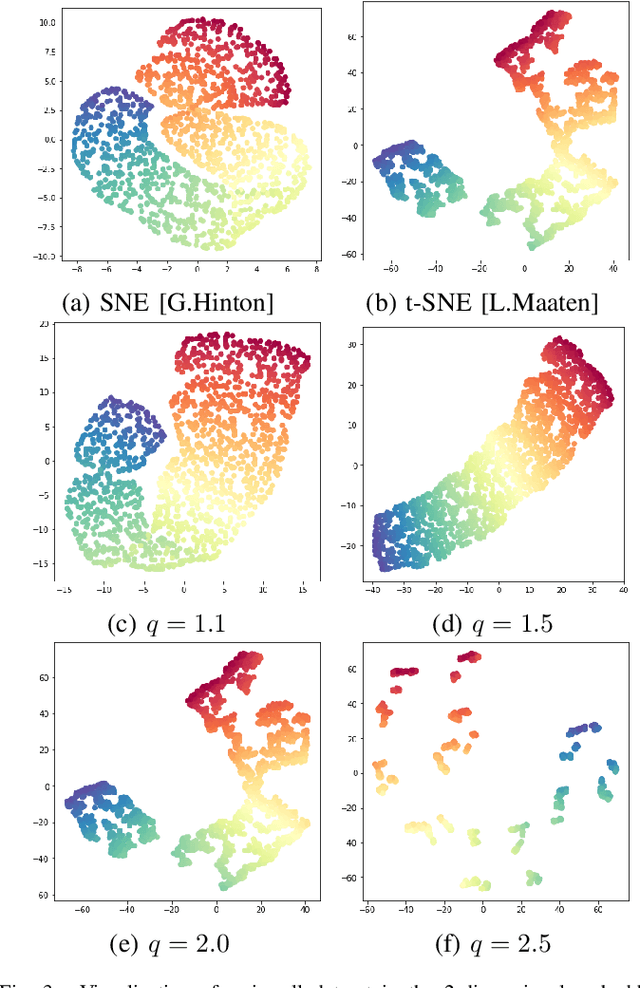
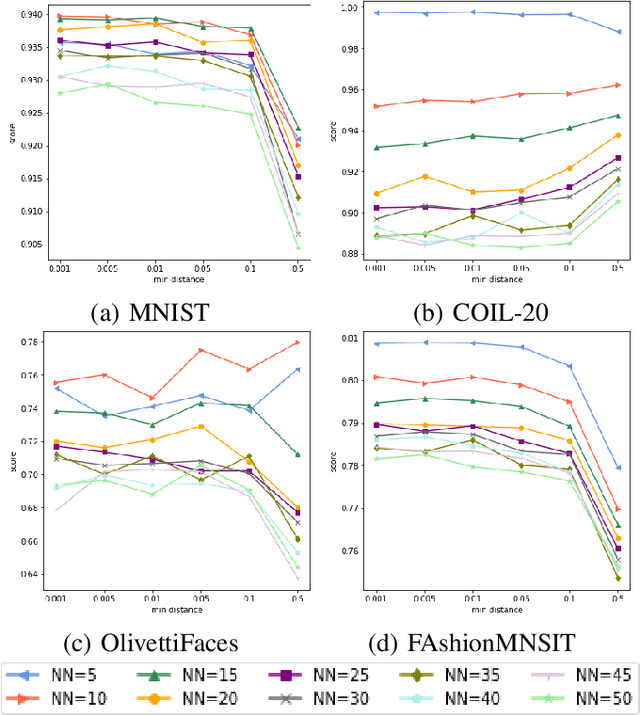
The dimensionality reduction has been widely introduced to use the high-dimensional data for regression, classification, feature analysis, and visualization. As the one technique of dimensionality reduction, a stochastic neighbor embedding (SNE) was introduced. The SNE leads powerful results to visualize high-dimensional data by considering the similarity between the local Gaussian distributions of high and low-dimensional space. To improve the SNE, a t-distributed stochastic neighbor embedding (t-SNE) was also introduced. To visualize high-dimensional data, the t-SNE leads to more powerful and flexible visualization on 2 or 3-dimensional mapping than the SNE by using a t-distribution as the distribution of low-dimensional data. Recently, Uniform manifold approximation and projection (UMAP) is proposed as a dimensionality reduction technique. We present a novel technique called a q-Gaussian distributed stochastic neighbor embedding (q-SNE). The q-SNE leads to more powerful and flexible visualization on 2 or 3-dimensional mapping than the t-SNE and the SNE by using a q-Gaussian distribution as the distribution of low-dimensional data. The q-Gaussian distribution includes the Gaussian distribution and the t-distribution as the special cases with q=1.0 and q=2.0. Therefore, the q-SNE can also express the t-SNE and the SNE by changing the parameter q, and this makes it possible to find the best visualization by choosing the parameter q. We show the performance of q-SNE as visualization on 2-dimensional mapping and classification by k-Nearest Neighbors (k-NN) classifier in embedded space compared with SNE, t-SNE, and UMAP by using the datasets MNIST, COIL-20, OlivettiFaces, FashionMNIST, and Glove.
Channel Planting for Deep Neural Networks using Knowledge Distillation
Nov 04, 2020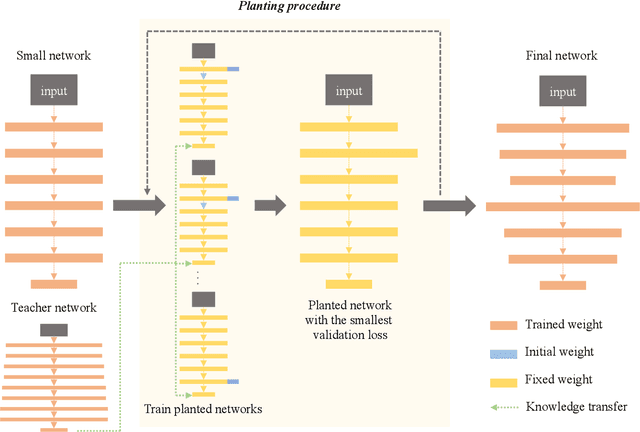
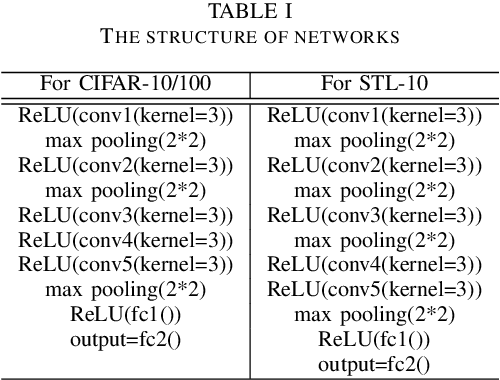
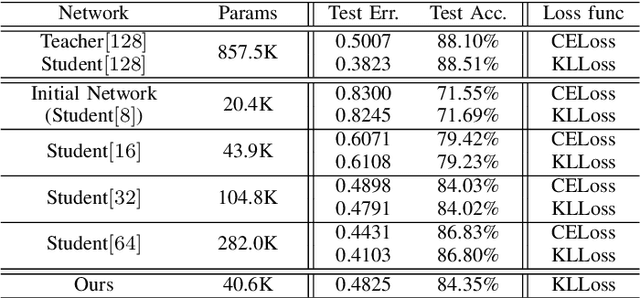
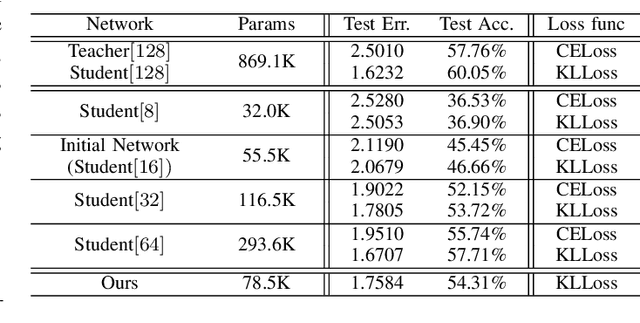
In recent years, deeper and wider neural networks have shown excellent performance in computer vision tasks, while their enormous amount of parameters results in increased computational cost and overfitting. Several methods have been proposed to compress the size of the networks without reducing network performance. Network pruning can reduce redundant and unnecessary parameters from a network. Knowledge distillation can transfer the knowledge of deeper and wider networks to smaller networks. The performance of the smaller network obtained by these methods is bounded by the predefined network. Neural architecture search has been proposed, which can search automatically the architecture of the networks to break the structure limitation. Also, there is a dynamic configuration method to train networks incrementally as sub-networks. In this paper, we present a novel incremental training algorithm for deep neural networks called planting. Our planting can search the optimal network architecture with smaller number of parameters for improving the network performance by augmenting channels incrementally to layers of the initial networks while keeping the earlier trained parameters fixed. Also, we propose using the knowledge distillation method for training the channels planted. By transferring the knowledge of deeper and wider networks, we can grow the networks effectively and efficiently. We evaluate the effectiveness of the proposed method on different datasets such as CIFAR-10/100 and STL-10. For the STL-10 dataset, we show that we are able to achieve comparable performance with only 7% parameters compared to the larger network and reduce the overfitting caused by a small amount of the data.
Filter Pruning using Hierarchical Group Sparse Regularization for Deep Convolutional Neural Networks
Nov 04, 2020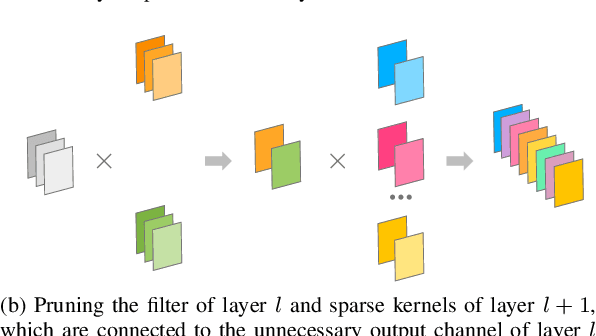
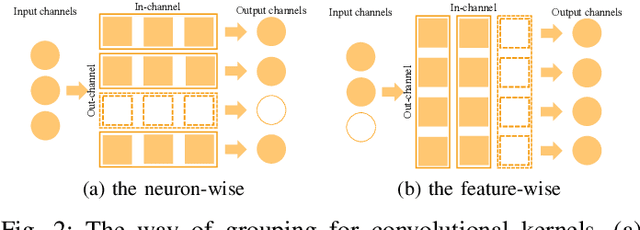
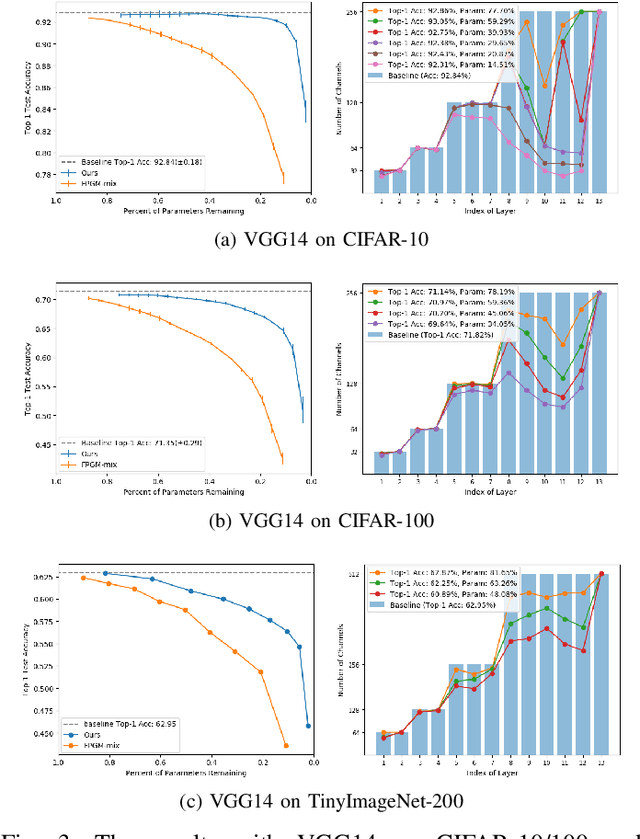
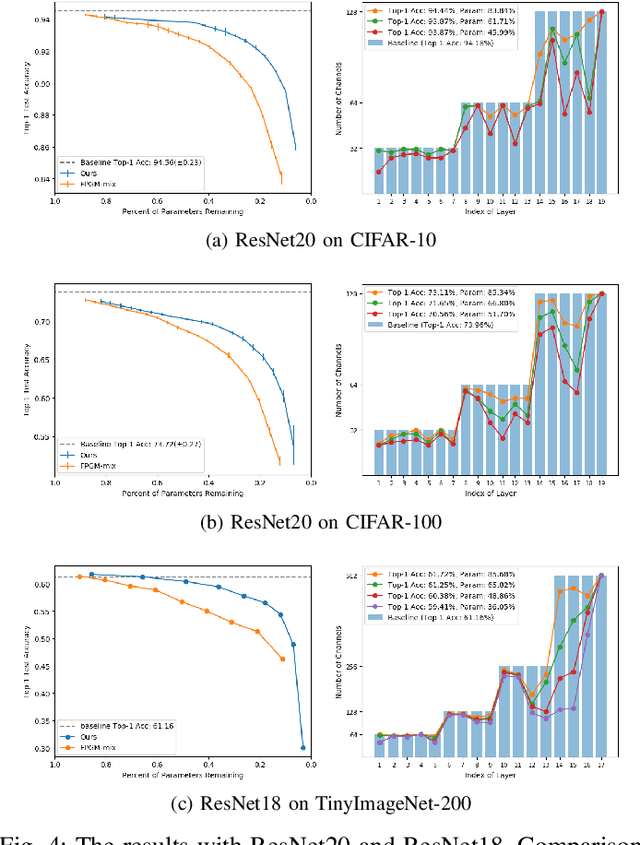
Since the convolutional neural networks are often trained with redundant parameters, it is possible to reduce redundant kernels or filters to obtain a compact network without dropping the classification accuracy. In this paper, we propose a filter pruning method using the hierarchical group sparse regularization. It is shown in our previous work that the hierarchical group sparse regularization is effective in obtaining sparse networks in which filters connected to unnecessary channels are automatically close to zero. After training the convolutional neural network with the hierarchical group sparse regularization, the unnecessary filters are selected based on the increase of the classification loss of the randomly selected training samples to obtain a compact network. It is shown that the proposed method can reduce more than 50% parameters of ResNet for CIFAR-10 with only 0.3% decrease in the accuracy of test samples. Also, 34% parameters of ResNet are reduced for TinyImageNet-200 with higher accuracy than the baseline network.
Transfer Learning by Cascaded Network to identify and classify lung nodules for cancer detection
Sep 24, 2020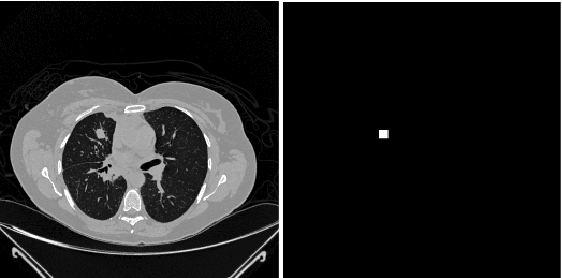

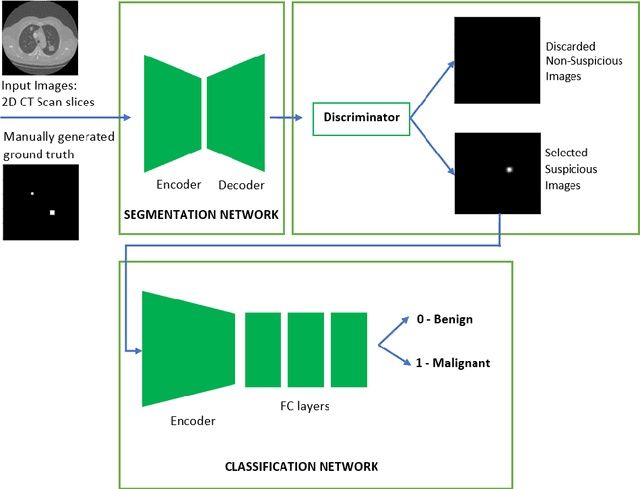

Lung cancer is one of the most deadly diseases in the world. Detecting such tumors at an early stage can be a tedious task. Existing deep learning architecture for lung nodule identification used complex architecture with large number of parameters. This study developed a cascaded architecture which can accurately segment and classify the benign or malignant lung nodules on computed tomography (CT) images. The main contribution of this study is to introduce a segmentation network where the first stage trained on a public data set can help to recognize the images which included a nodule from any data set by means of transfer learning. And the segmentation of a nodule improves the second stage to classify the nodules into benign and malignant. The proposed architecture outperformed the conventional methods with an area under curve value of 95.67\%. The experimental results showed that the classification accuracy of 97.96\% of our proposed architecture outperformed other simple and complex architectures in classifying lung nodules for lung cancer detection.
U-Net with Graph Based Smoothing Regularizer for Small Vessel Segmentation on Fundus Image
Sep 16, 2020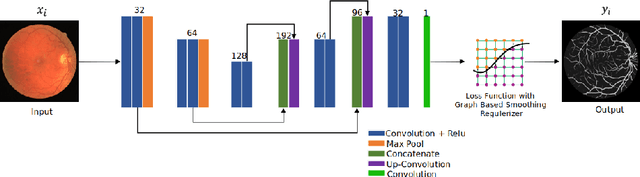
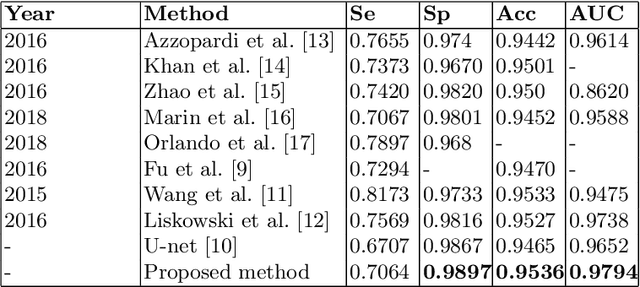
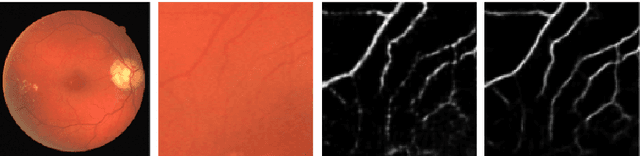
The detection of retinal blood vessels, especially the changes of small vessel condition is the most important indicator to identify the vascular network of the human body. Existing techniques focused mainly on shape of the large vessels, which is not appropriate for the disconnected small and isolated vessels. Paying attention to the low contrast small blood vessel in fundus region, first time we proposed to combine graph based smoothing regularizer with the loss function in the U-net framework. The proposed regularizer treated the image as two graphs by calculating the graph laplacians on vessel regions and the background regions on the image. The potential of the proposed graph based smoothing regularizer in reconstructing small vessel is compared over the classical U-net with or without regularizer. Numerical and visual results shows that our developed regularizer proved its effectiveness in segmenting the small vessels and reconnecting the fragmented retinal blood vessels.
Triplet Loss for Knowledge Distillation
Apr 17, 2020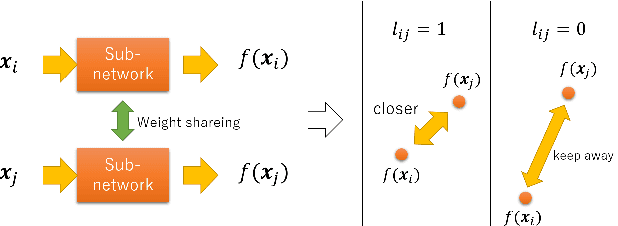
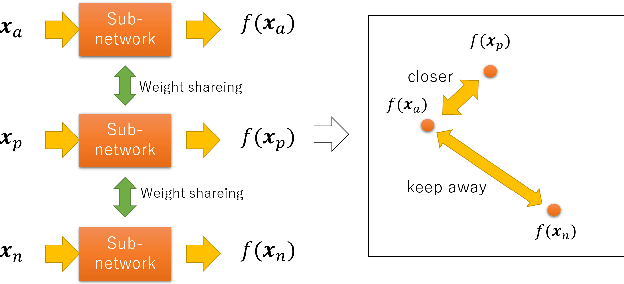
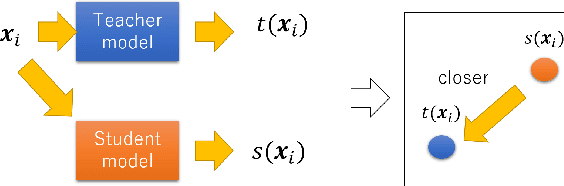

In recent years, deep learning has spread rapidly, and deeper, larger models have been proposed. However, the calculation cost becomes enormous as the size of the models becomes larger. Various techniques for compressing the size of the models have been proposed to improve performance while reducing computational costs. One of the methods to compress the size of the models is knowledge distillation (KD). Knowledge distillation is a technique for transferring knowledge of deep or ensemble models with many parameters (teacher model) to smaller shallow models (student model). Since the purpose of knowledge distillation is to increase the similarity between the teacher model and the student model, we propose to introduce the concept of metric learning into knowledge distillation to make the student model closer to the teacher model using pairs or triplets of the training samples. In metric learning, the researchers are developing the methods to build a model that can increase the similarity of outputs for similar samples. Metric learning aims at reducing the distance between similar and increasing the distance between dissimilar. The functionality of the metric learning to reduce the differences between similar outputs can be used for the knowledge distillation to reduce the differences between the outputs of the teacher model and the student model. Since the outputs of the teacher model for different objects are usually different, the student model needs to distinguish them. We think that metric learning can clarify the difference between the different outputs, and the performance of the student model could be improved. We have performed experiments to compare the proposed method with state-of-the-art knowledge distillation methods.