 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD4: Text-guided diffusion model-based domain adaptive data augmentation for vineyard shoot detection
Sep 06, 2024



In an agricultural field, plant phenotyping using object detection models is gaining attention. However, collecting the training data necessary to create generic and high-precision models is extremely challenging due to the difficulty of annotation and the diversity of domains. Furthermore, it is difficult to transfer training data across different crops, and although machine learning models effective for specific environments, conditions, or crops have been developed, they cannot be widely applied in actual fields. In this study, we propose a generative data augmentation method (D4) for vineyard shoot detection. D4 uses a pre-trained text-guided diffusion model based on a large number of original images culled from video data collected by unmanned ground vehicles or other means, and a small number of annotated datasets. The proposed method generates new annotated images with background information adapted to the target domain while retaining annotation information necessary for object detection. In addition, D4 overcomes the lack of training data in agriculture, including the difficulty of annotation and diversity of domains. We confirmed that this generative data augmentation method improved the mean average precision by up to 28.65% for the BBox detection task and the average precision by up to 13.73% for the keypoint detection task for vineyard shoot detection. Our generative data augmentation method D4 is expected to simultaneously solve the cost and domain diversity issues of training data generation in agriculture and improve the generalization performance of detection models.
Channel Planting for Deep Neural Networks using Knowledge Distillation
Nov 04, 2020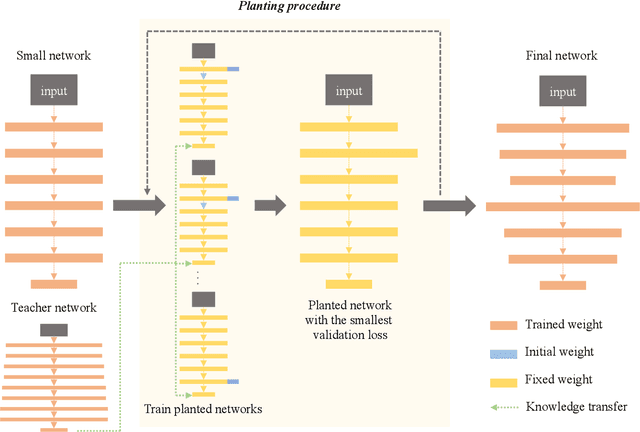
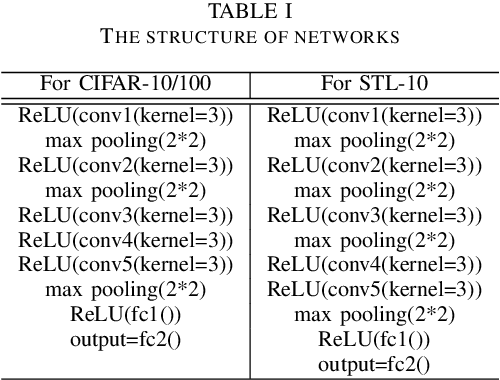
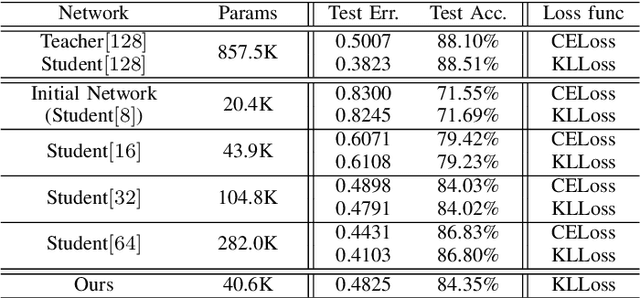
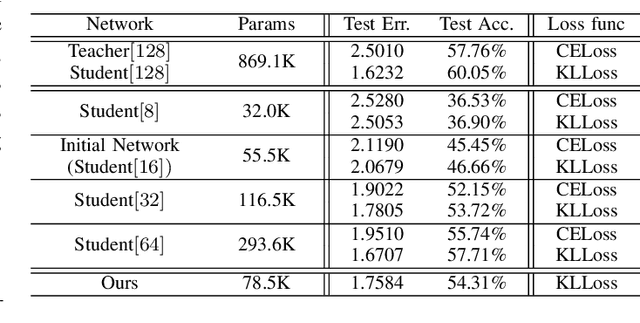
In recent years, deeper and wider neural networks have shown excellent performance in computer vision tasks, while their enormous amount of parameters results in increased computational cost and overfitting. Several methods have been proposed to compress the size of the networks without reducing network performance. Network pruning can reduce redundant and unnecessary parameters from a network. Knowledge distillation can transfer the knowledge of deeper and wider networks to smaller networks. The performance of the smaller network obtained by these methods is bounded by the predefined network. Neural architecture search has been proposed, which can search automatically the architecture of the networks to break the structure limitation. Also, there is a dynamic configuration method to train networks incrementally as sub-networks. In this paper, we present a novel incremental training algorithm for deep neural networks called planting. Our planting can search the optimal network architecture with smaller number of parameters for improving the network performance by augmenting channels incrementally to layers of the initial networks while keeping the earlier trained parameters fixed. Also, we propose using the knowledge distillation method for training the channels planted. By transferring the knowledge of deeper and wider networks, we can grow the networks effectively and efficiently. We evaluate the effectiveness of the proposed method on different datasets such as CIFAR-10/100 and STL-10. For the STL-10 dataset, we show that we are able to achieve comparable performance with only 7% parameters compared to the larger network and reduce the overfitting caused by a small amount of the data.