 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Planting for Deep Neural Networks using Knowledge Distillation
Paper and Code
Nov 04, 2020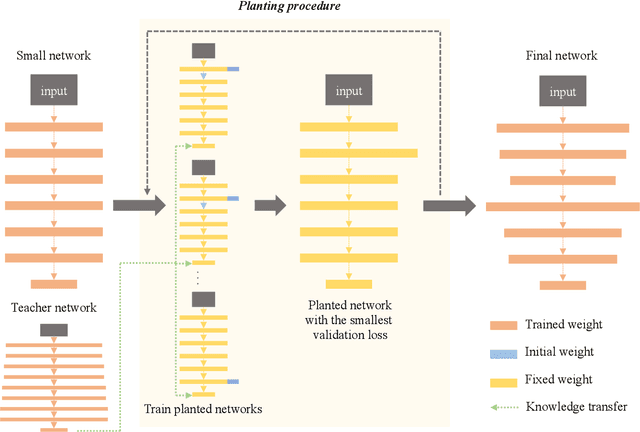
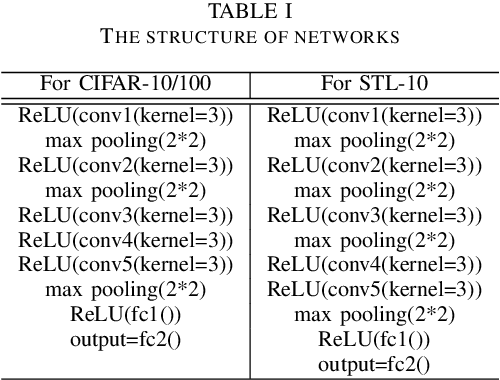
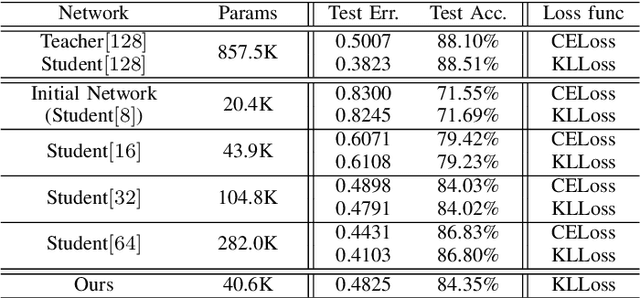
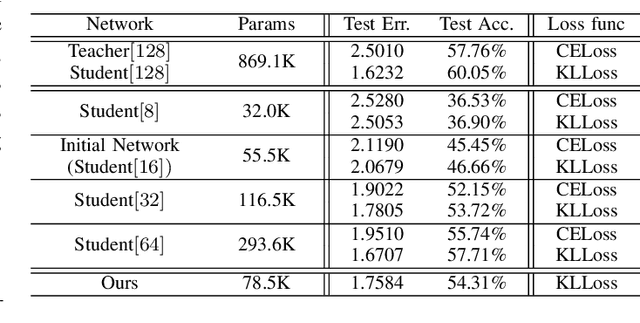
In recent years, deeper and wider neural networks have shown excellent performance in computer vision tasks, while their enormous amount of parameters results in increased computational cost and overfitting. Several methods have been proposed to compress the size of the networks without reducing network performance. Network pruning can reduce redundant and unnecessary parameters from a network. Knowledge distillation can transfer the knowledge of deeper and wider networks to smaller networks. The performance of the smaller network obtained by these methods is bounded by the predefined network. Neural architecture search has been proposed, which can search automatically the architecture of the networks to break the structure limitation. Also, there is a dynamic configuration method to train networks incrementally as sub-networks. In this paper, we present a novel incremental training algorithm for deep neural networks called planting. Our planting can search the optimal network architecture with smaller number of parameters for improving the network performance by augmenting channels incrementally to layers of the initial networks while keeping the earlier trained parameters fixed. Also, we propose using the knowledge distillation method for training the channels planted. By transferring the knowledge of deeper and wider networks, we can grow the networks effectively and efficiently. We evaluate the effectiveness of the proposed method on different datasets such as CIFAR-10/100 and STL-10. For the STL-10 dataset, we show that we are able to achieve comparable performance with only 7% parameters compared to the larger network and reduce the overfitting caused by a small amount of the data.