 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Planting for Deep Neural Networks using Knowledge Distillation
Nov 04, 2020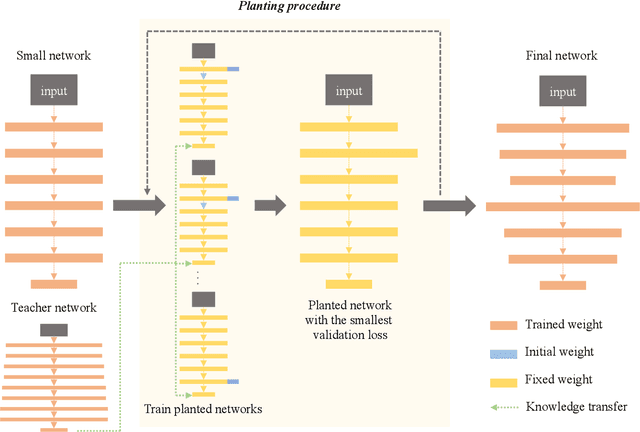
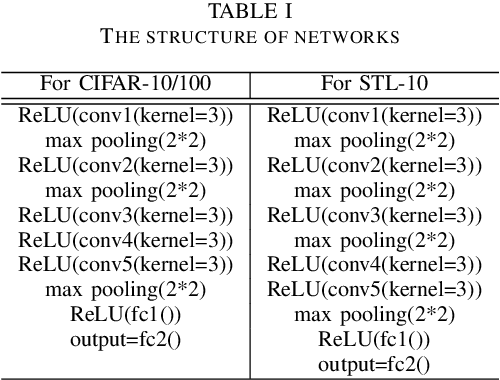
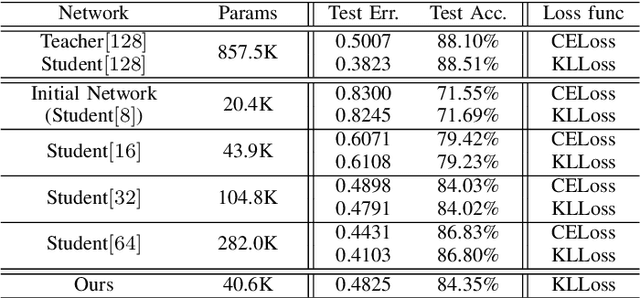
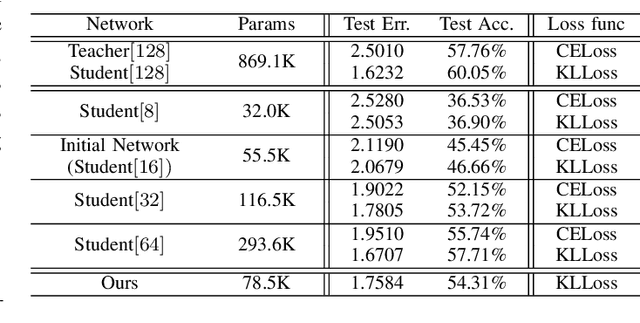
In recent years, deeper and wider neural networks have shown excellent performance in computer vision tasks, while their enormous amount of parameters results in increased computational cost and overfitting. Several methods have been proposed to compress the size of the networks without reducing network performance. Network pruning can reduce redundant and unnecessary parameters from a network. Knowledge distillation can transfer the knowledge of deeper and wider networks to smaller networks. The performance of the smaller network obtained by these methods is bounded by the predefined network. Neural architecture search has been proposed, which can search automatically the architecture of the networks to break the structure limitation. Also, there is a dynamic configuration method to train networks incrementally as sub-networks. In this paper, we present a novel incremental training algorithm for deep neural networks called planting. Our planting can search the optimal network architecture with smaller number of parameters for improving the network performance by augmenting channels incrementally to layers of the initial networks while keeping the earlier trained parameters fixed. Also, we propose using the knowledge distillation method for training the channels planted. By transferring the knowledge of deeper and wider networks, we can grow the networks effectively and efficiently. We evaluate the effectiveness of the proposed method on different datasets such as CIFAR-10/100 and STL-10. For the STL-10 dataset, we show that we are able to achieve comparable performance with only 7% parameters compared to the larger network and reduce the overfitting caused by a small amount of the data.
Filter Pruning using Hierarchical Group Sparse Regularization for Deep Convolutional Neural Networks
Nov 04, 2020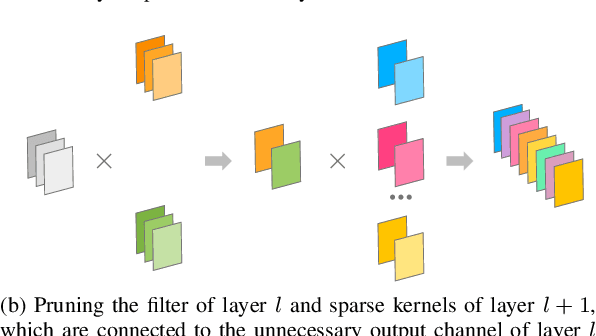
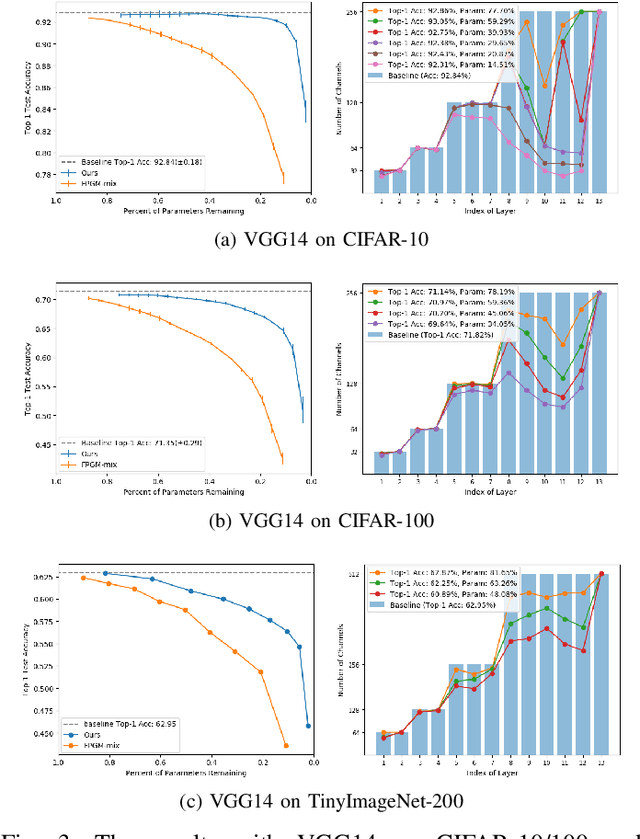
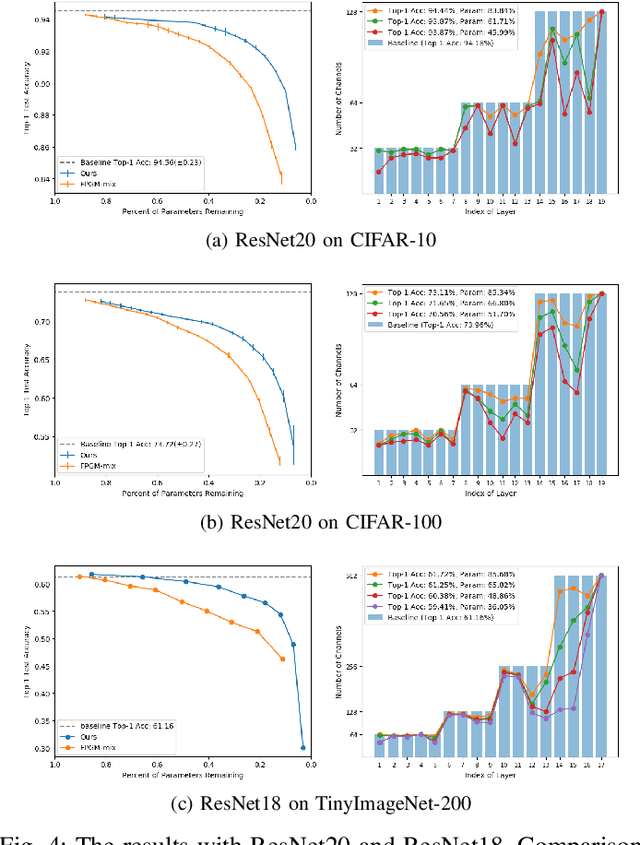
Since the convolutional neural networks are often trained with redundant parameters, it is possible to reduce redundant kernels or filters to obtain a compact network without dropping the classification accuracy. In this paper, we propose a filter pruning method using the hierarchical group sparse regularization. It is shown in our previous work that the hierarchical group sparse regularization is effective in obtaining sparse networks in which filters connected to unnecessary channels are automatically close to zero. After training the convolutional neural network with the hierarchical group sparse regularization, the unnecessary filters are selected based on the increase of the classification loss of the randomly selected training samples to obtain a compact network. It is shown that the proposed method can reduce more than 50% parameters of ResNet for CIFAR-10 with only 0.3% decrease in the accuracy of test samples. Also, 34% parameters of ResNet are reduced for TinyImageNet-200 with higher accuracy than the baseline network.
Hierarchical Group Sparse Regularization for Deep Convolutional Neural Networks
Apr 09, 2020
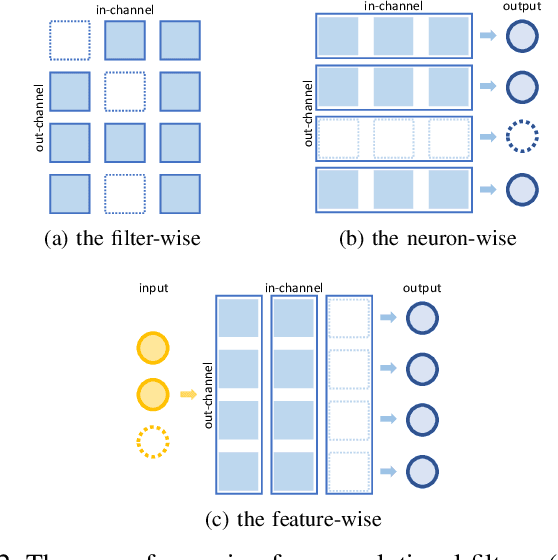

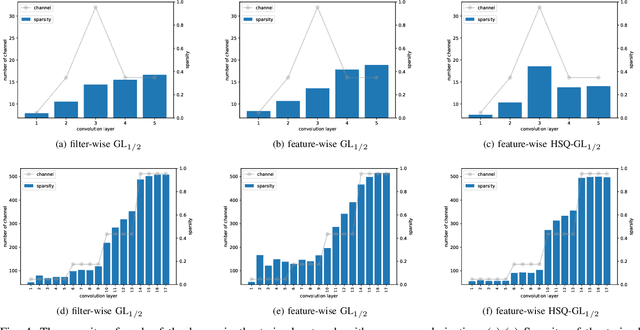
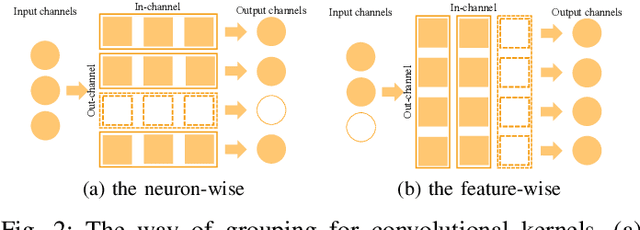
In a deep neural network (DNN), the number of the parameters is usually huge to get high learning performances. For that reason, it costs a lot of memory and substantial computational resources, and also causes overfitting. It is known that some parameters are redundant and can be removed from the network without decreasing performance. Many sparse regularization criteria have been proposed to solve this problem. In a convolutional neural network (CNN), group sparse regularizations are often used to remove unnecessary subsets of the weights, such as filters or channels. When we apply a group sparse regularization for the weights connected to a neuron as a group, each convolution filter is not treated as a target group in the regularization. In this paper, we introduce the concept of hierarchical grouping to solve this problem, and we propose several hierarchical group sparse regularization criteria for CNNs. Our proposed the hierarchical group sparse regularization can treat the weight for the input-neuron or the output-neuron as a group and convolutional filter as a group in the same group to prune the unnecessary subsets of weights. As a result, we can prune the weights more adequately depending on the structure of the network and the number of channels keeping high performance. In the experiment, we investigate the effectiveness of the proposed sparse regularizations through intensive comparison experiments on public datasets with several network architectures. Code is available on GitHub: "https://github.com/K-Mitsuno/hierarchical-group-sparse-regularization"