 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Action Localization and Action Recognition using Global-Local Attention of 3D CNN
Paper and Code
Dec 17, 2020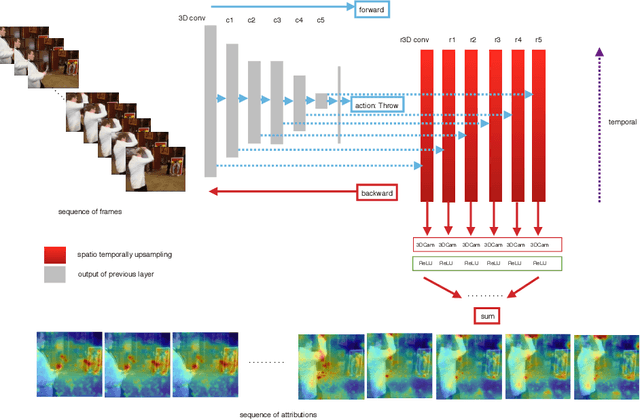

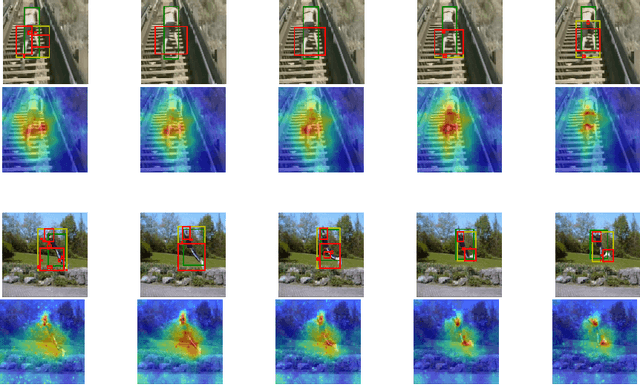

3D Convolutional Neural Network (3D CNN) captures spatial and temporal information on 3D data such as video sequences. However, due to the convolution and pooling mechanism, the information loss seems unavoidable. To improve the visual explanations and classification in 3D CNN, we propose two approaches; i) aggregate layer-wise global to local (global-local) discrete gradients using trained 3DResNext network, and ii) implement attention gating network to improve the accuracy of the action recognition. The proposed approach intends to show the usefulness of every layer termed as global-local attention in 3D CNN via visual attribution, weakly-supervised action localization, and action recognition. Firstly, the 3DResNext is trained and applied for action classification using backpropagation concerning the maximum predicted class. The gradients and activations of every layer are then up-sampled. Later, aggregation is used to produce more nuanced attention, which points out the most critical part of the predicted class's input videos. We use contour thresholding of final attention for final localization. We evaluate spatial and temporal action localization in trimmed videos using fine-grained visual explanation via 3DCam. Experimental results show that the proposed approach produces informative visual explanations and discriminative attention. Furthermore, the action recognition via attention gating on each layer produces better classification results than the baseline model.