 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Agnostic Continual Learning for Chest Radiograph Classification
Feb 17, 2026Clinical deployment of chest radiograph classifiers requires models that can be updated as new datasets become available without retraining on previously ob- served data or degrading validated performance. We study, for the first time, a task-incremental continual learning setting for chest radiograph classification, in which heterogeneous chest X-ray datasets arrive sequentially and task identifiers are unavailable at inference. We propose a continual adapter-based routing learning strategy for Chest X-rays (CARL-XRay) that maintains a fixed high-capacity backbone and incrementally allocates lightweight task-specific adapters and classifier heads. A latent task selector operates on task-adapted features and leverages both current and historical context preserved through compact prototypes and feature-level experience replay. This design supports stable task identification and adaptation across sequential updates while avoiding raw-image storage. Experiments on large-scale public chest radiograph datasets demonstrate robust performance retention and reliable task-aware inference under continual dataset ingestion. CARL-XRay outperforms joint training under task-unknown deployment, achieving higher routing accuracy (75.0\% vs.\ 62.5\%), while maintaining competitive diagnostic performance with AUROC of 0.74 in the oracle setting with ground-truth task identity and 0.75 under task-unknown inference, using significantly fewer trainable parameters. Finally, the proposed framework provides a practical alternative to joint training and repeated full retraining in continual clinical deployment.
iReasoner: Trajectory-Aware Intrinsic Reasoning Supervision for Self-Evolving Large Multimodal Models
Jan 09, 2026Recent work shows that large multimodal models (LMMs) can self-improve from unlabeled data via self-play and intrinsic feedback. Yet existing self-evolving frameworks mainly reward final outcomes, leaving intermediate reasoning weakly constrained despite its importance for visually grounded decision making. We propose iReasoner, a self-evolving framework that improves an LMM's implicit reasoning by explicitly eliciting chain-of-thought (CoT) and rewarding its internal agreement. In a Proposer--Solver loop over unlabeled images, iReasoner augments outcome-level intrinsic rewards with a trajectory-aware signal defined over intermediate reasoning steps, providing learning signals that distinguish reasoning paths leading to the same answer without ground-truth labels or external judges. Starting from Qwen2.5-VL-7B, iReasoner yields up to $+2.1$ points across diverse multimodal reasoning benchmarks under fully unsupervised post-training. We hope this work serves as a starting point for reasoning-aware self-improvement in LMMs in purely unsupervised settings.
Attention-effective multiple instance learning on weakly stem cell colony segmentation
Mar 09, 2022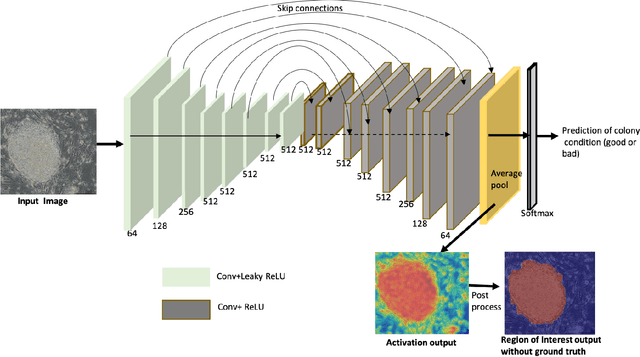
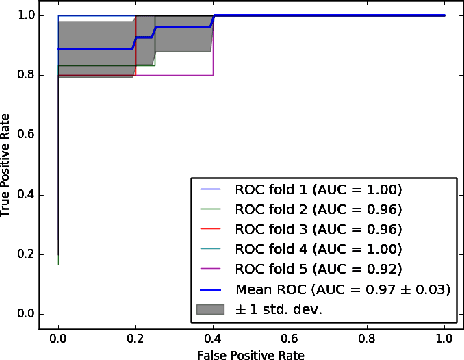
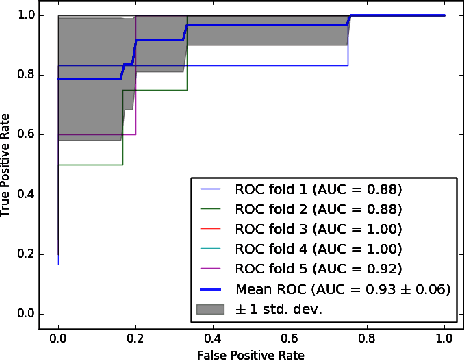
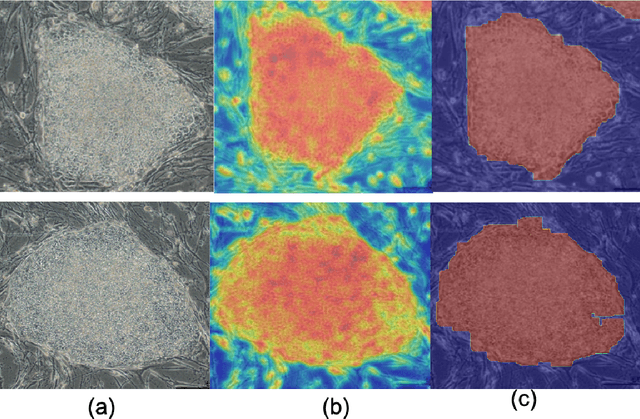
The detection of induced pluripotent stem cell (iPSC) colonies often needs the precise extraction of the colony features. However, existing computerized systems relied on segmentation of contours by preprocessing for classifying the colony conditions were task-extensive. To maximize the efficiency in categorizing colony conditions, we propose a multiple instance learning (MIL) in weakly supervised settings. It is designed in a single model to produce weak segmentation and classification of colonies without using finely labeled samples. As a single model, we employ a U-net-like convolution neural network (CNN) to train on binary image-level labels for MIL colonies classification. Furthermore, to specify the object of interest we used a simple post-processing method. The proposed approach is compared over conventional methods using five-fold cross-validation and receiver operating characteristic (ROC) curve. The maximum accuracy of the MIL-net is 95%, which is 15 % higher than the conventional methods. Furthermore, the ability to interpret the location of the iPSC colonies based on the image level label without using a pixel-wise ground truth image is more appealing and cost-effective in colony condition recognition.
Weakly-Supervised Action Localization and Action Recognition using Global-Local Attention of 3D CNN
Dec 17, 2020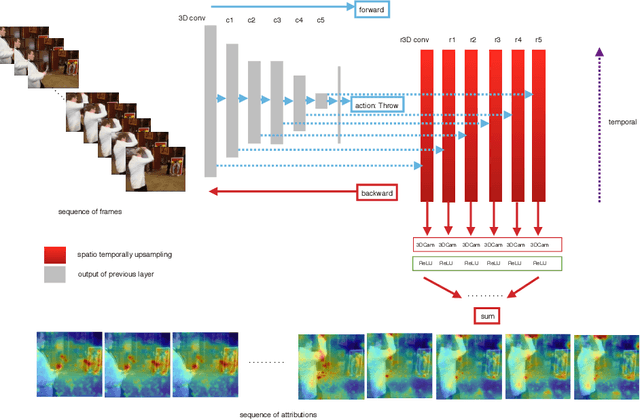

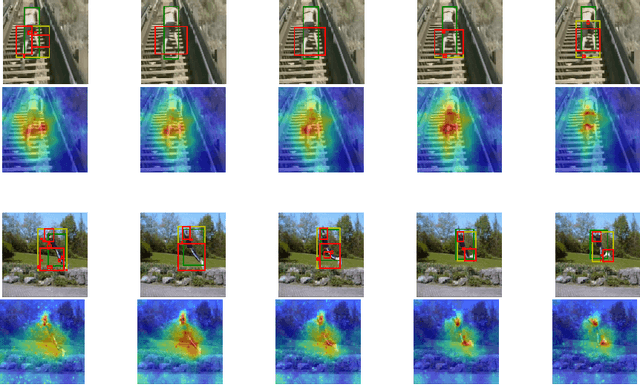

3D Convolutional Neural Network (3D CNN) captures spatial and temporal information on 3D data such as video sequences. However, due to the convolution and pooling mechanism, the information loss seems unavoidable. To improve the visual explanations and classification in 3D CNN, we propose two approaches; i) aggregate layer-wise global to local (global-local) discrete gradients using trained 3DResNext network, and ii) implement attention gating network to improve the accuracy of the action recognition. The proposed approach intends to show the usefulness of every layer termed as global-local attention in 3D CNN via visual attribution, weakly-supervised action localization, and action recognition. Firstly, the 3DResNext is trained and applied for action classification using backpropagation concerning the maximum predicted class. The gradients and activations of every layer are then up-sampled. Later, aggregation is used to produce more nuanced attention, which points out the most critical part of the predicted class's input videos. We use contour thresholding of final attention for final localization. We evaluate spatial and temporal action localization in trimmed videos using fine-grained visual explanation via 3DCam. Experimental results show that the proposed approach produces informative visual explanations and discriminative attention. Furthermore, the action recognition via attention gating on each layer produces better classification results than the baseline model.