 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Credit Assignment Compiler for Joint Prediction
Jun 01, 2016


Many machine learning applications involve jointly predicting multiple mutually dependent output variables. Learning to search is a family of methods where the complex decision problem is cast into a sequence of decisions via a search space. Although these methods have shown promise both in theory and in practice, implementing them has been burdensomely awkward. In this paper, we show the search space can be defined by an arbitrary imperative program, turning learning to search into a credit assignment compiler. Altogether with the algorithmic improvements for the compiler, we radically reduce the complexity of programming and the running time. We demonstrate the feasibility of our approach on multiple joint prediction tasks. In all cases, we obtain accuracies as high as alternative approaches, at drastically reduced execution and programming time.
Normalized Online Learning
Aug 09, 2014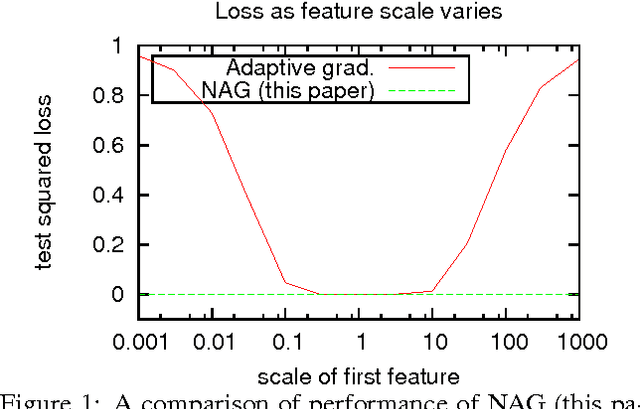
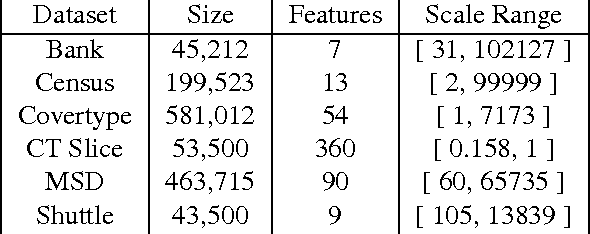
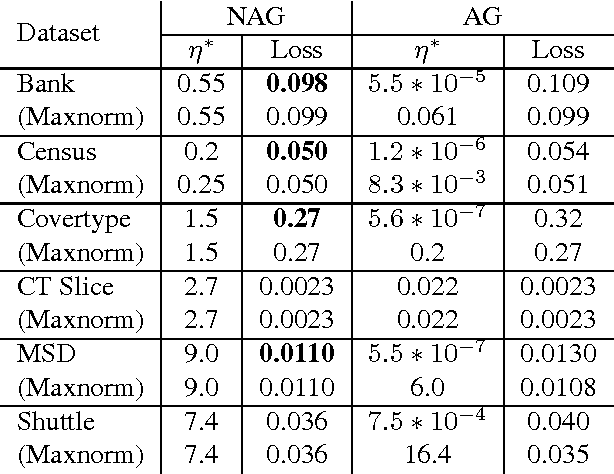
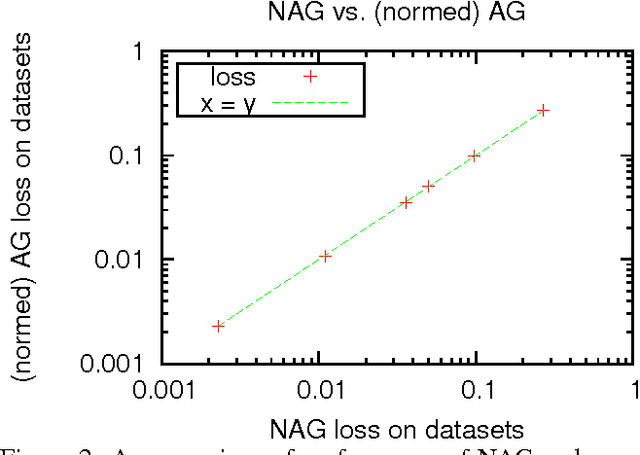
We introduce online learning algorithms which are independent of feature scales, proving regret bounds dependent on the ratio of scales existent in the data rather than the absolute scale. This has several useful effects: there is no need to pre-normalize data, the test-time and test-space complexity are reduced, and the algorithms are more robust.
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Jun 23, 2014Recent work has demonstrated that problems-- particularly imitation learning and structured prediction-- where a learner's predictions influence the input-distribution it is tested on can be naturally addressed by an interactive approach and analyzed using no-regret online learning. These approaches to imitation learning, however, neither require nor benefit from information about the cost of actions. We extend existing results in two directions: first, we develop an interactive imitation learning approach that leverages cost information; second, we extend the technique to address reinforcement learning. The results provide theoretical support to the commonly observed successes of online approximate policy iteration. Our approach suggests a broad new family of algorithms and provides a unifying view of existing techniques for imitation and reinforcement learning.
Knapsack Constrained Contextual Submodular List Prediction with Application to Multi-document Summarization
Mar 15, 2014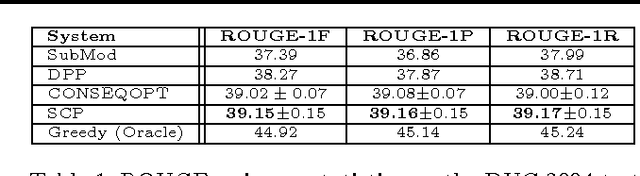
We study the problem of predicting a set or list of options under knapsack constraint. The quality of such lists are evaluated by a submodular reward function that measures both quality and diversity. Similar to DAgger (Ross et al., 2010), by a reduction to online learning, we show how to adapt two sequence prediction models to imitate greedy maximization under knapsack constraint problems: CONSEQOPT (Dey et al., 2012) and SCP (Ross et al., 2013). Experiments on extractive multi-document summarization show that our approach outperforms existing state-of-the-art methods.
Learning Policies for Contextual Submodular Prediction
May 11, 2013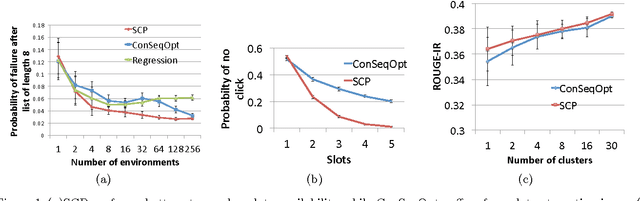

Many prediction domains, such as ad placement, recommendation, trajectory prediction, and document summarization, require predicting a set or list of options. Such lists are often evaluated using submodular reward functions that measure both quality and diversity. We propose a simple, efficient, and provably near-optimal approach to optimizing such prediction problems based on no-regret learning. Our method leverages a surprising result from online submodular optimization: a single no-regret online learner can compete with an optimal sequence of predictions. Compared to previous work, which either learn a sequence of classifiers or rely on stronger assumptions such as realizability, we ensure both data-efficiency as well as performance guarantees in the fully agnostic setting. Experiments validate the efficiency and applicability of the approach on a wide range of problems including manipulator trajectory optimization, news recommendation and document summarization.
Learning Monocular Reactive UAV Control in Cluttered Natural Environments
Nov 07, 2012


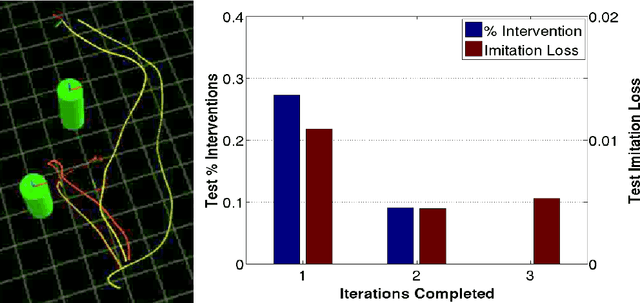
Autonomous navigation for large Unmanned Aerial Vehicles (UAVs) is fairly straight-forward, as expensive sensors and monitoring devices can be employed. In contrast, obstacle avoidance remains a challenging task for Micro Aerial Vehicles (MAVs) which operate at low altitude in cluttered environments. Unlike large vehicles, MAVs can only carry very light sensors, such as cameras, making autonomous navigation through obstacles much more challenging. In this paper, we describe a system that navigates a small quadrotor helicopter autonomously at low altitude through natural forest environments. Using only a single cheap camera to perceive the environment, we are able to maintain a constant velocity of up to 1.5m/s. Given a small set of human pilot demonstrations, we use recent state-of-the-art imitation learning techniques to train a controller that can avoid trees by adapting the MAVs heading. We demonstrate the performance of our system in a more controlled environment indoors, and in real natural forest environments outdoors.
Agnostic System Identification for Model-Based Reinforcement Learning
Jul 03, 2012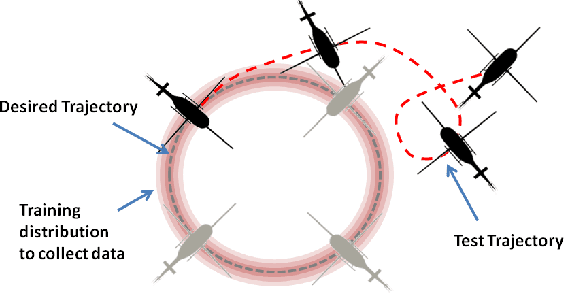
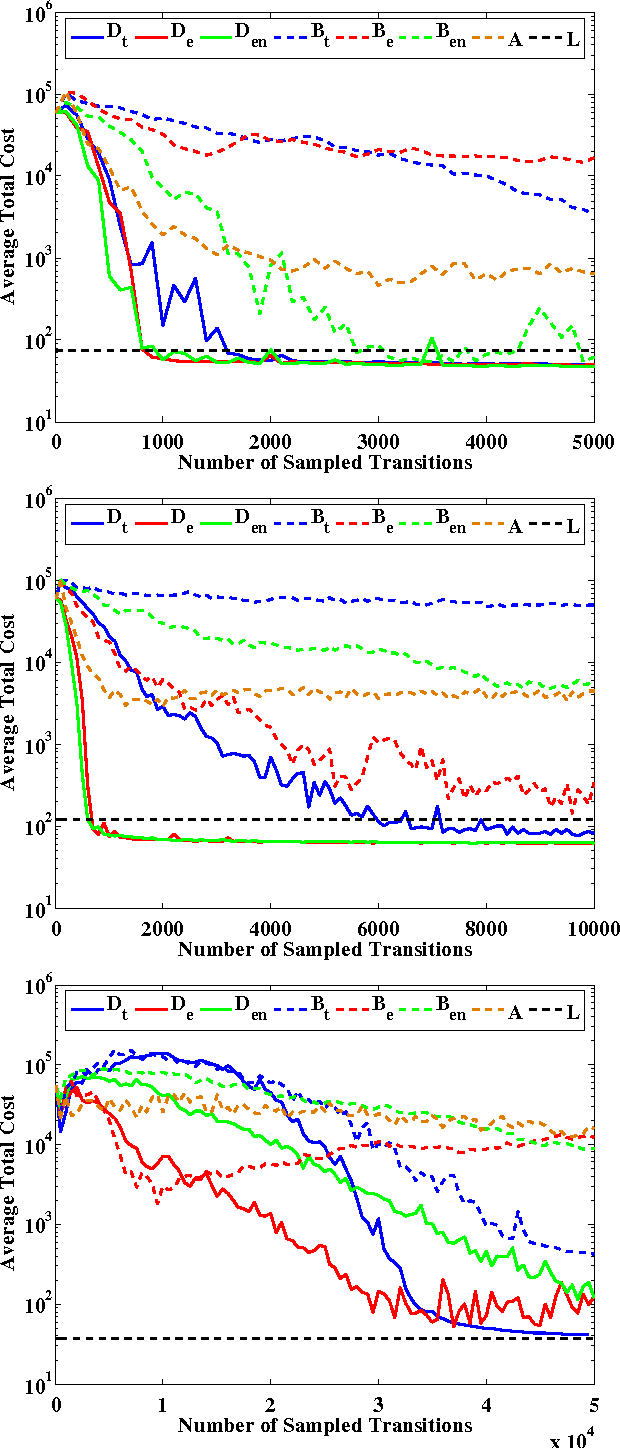
A fundamental problem in control is to learn a model of a system from observations that is useful for controller synthesis. To provide good performance guarantees, existing methods must assume that the real system is in the class of models considered during learning. We present an iterative method with strong guarantees even in the agnostic case where the system is not in the class. In particular, we show that any no-regret online learning algorithm can be used to obtain a near-optimal policy, provided some model achieves low training error and access to a good exploration distribution. Our approach applies to both discrete and continuous domains. We demonstrate its efficacy and scalability on a challenging helicopter domain from the literature.
Model-Based Bayesian Reinforcement Learning in Large Structured Domains
Jun 13, 2012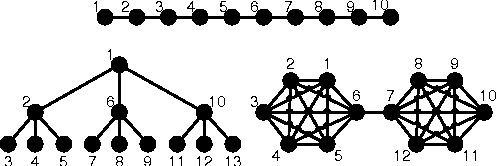
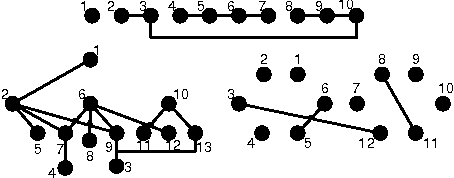
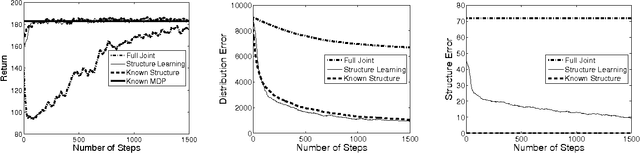
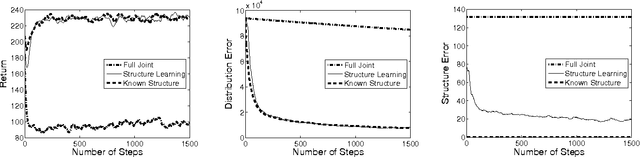
Model-based Bayesian reinforcement learning has generated significant interest in the AI community as it provides an elegant solution to the optimal exploration-exploitation tradeoff in classical reinforcement learning. Unfortunately, the applicability of this type of approach has been limited to small domains due to the high complexity of reasoning about the joint posterior over model parameters. In this paper, we consider the use of factored representations combined with online planning techniques, to improve scalability of these methods. The main contribution of this paper is a Bayesian framework for learning the structure and parameters of a dynamical system, while also simultaneously planning a (near-)optimal sequence of actions.
Stability Conditions for Online Learnability
Aug 17, 2011Stability is a general notion that quantifies the sensitivity of a learning algorithm's output to small change in the training dataset (e.g. deletion or replacement of a single training sample). Such conditions have recently been shown to be more powerful to characterize learnability in the general learning setting under i.i.d. samples where uniform convergence is not necessary for learnability, but where stability is both sufficient and necessary for learnability. We here show that similar stability conditions are also sufficient for online learnability, i.e. whether there exists a learning algorithm such that under any sequence of examples (potentially chosen adversarially) produces a sequence of hypotheses that has no regret in the limit with respect to the best hypothesis in hindsight. We introduce online stability, a stability condition related to uniform-leave-one-out stability in the batch setting, that is sufficient for online learnability. In particular we show that popular classes of online learners, namely algorithms that fall in the category of Follow-the-(Regularized)-Leader, Mirror Descent, gradient-based methods and randomized algorithms like Weighted Majority and Hedge, are guaranteed to have no regret if they have such online stability property. We provide examples that suggest the existence of an algorithm with such stability condition might in fact be necessary for online learnability. For the more restricted binary classification setting, we establish that such stability condition is in fact both sufficient and necessary. We also show that for a large class of online learnable problems in the general learning setting, namely those with a notion of sub-exponential covering, no-regret online algorithms that have such stability condition exists.
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
Mar 16, 2011

Sequential prediction problems such as imitation learning, where future observations depend on previous predictions (actions), violate the common i.i.d. assumptions made in statistical learning. This leads to poor performance in theory and often in practice. Some recent approaches provide stronger guarantees in this setting, but remain somewhat unsatisfactory as they train either non-stationary or stochastic policies and require a large number of iterations. In this paper, we propose a new iterative algorithm, which trains a stationary deterministic policy, that can be seen as a no regret algorithm in an online learning setting. We show that any such no regret algorithm, combined with additional reduction assumptions, must find a policy with good performance under the distribution of observations it induces in such sequential settings. We demonstrate that this new approach outperforms previous approaches on two challenging imitation learning problems and a benchmark sequence labeling problem.