Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnapsack Constrained Contextual Submodular List Prediction with Application to Multi-document Summarization
Paper and Code
Mar 15, 2014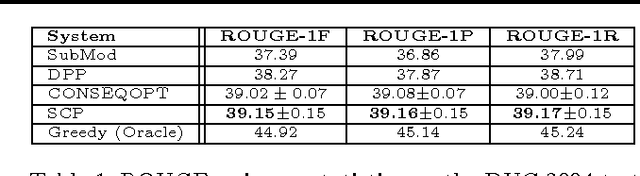
We study the problem of predicting a set or list of options under knapsack constraint. The quality of such lists are evaluated by a submodular reward function that measures both quality and diversity. Similar to DAgger (Ross et al., 2010), by a reduction to online learning, we show how to adapt two sequence prediction models to imitate greedy maximization under knapsack constraint problems: CONSEQOPT (Dey et al., 2012) and SCP (Ross et al., 2013). Experiments on extractive multi-document summarization show that our approach outperforms existing state-of-the-art methods.
* 8 pages, ICML 2013 Workshop on Inferning: Interactions between
Inference and Learning
View paper on