 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal and multicontrast image fusion via deep generative models
Mar 28, 2023Recently, it has become progressively more evident that classic diagnostic labels are unable to reliably describe the complexity and variability of several clinical phenotypes. This is particularly true for a broad range of neuropsychiatric illnesses (e.g., depression, anxiety disorders, behavioral phenotypes). Patient heterogeneity can be better described by grouping individuals into novel categories based on empirically derived sections of intersecting continua that span across and beyond traditional categorical borders. In this context, neuroimaging data carry a wealth of spatiotemporally resolved information about each patient's brain. However, they are usually heavily collapsed a priori through procedures which are not learned as part of model training, and consequently not optimized for the downstream prediction task. This is because every individual participant usually comes with multiple whole-brain 3D imaging modalities often accompanied by a deep genotypic and phenotypic characterization, hence posing formidable computational challenges. In this paper we design a deep learning architecture based on generative models rooted in a modular approach and separable convolutional blocks to a) fuse multiple 3D neuroimaging modalities on a voxel-wise level, b) convert them into informative latent embeddings through heavy dimensionality reduction, c) maintain good generalizability and minimal information loss. As proof of concept, we test our architecture on the well characterized Human Connectome Project database demonstrating that our latent embeddings can be clustered into easily separable subject strata which, in turn, map to different phenotypical information which was not included in the embedding creation process. This may be of aid in predicting disease evolution as well as drug response, hence supporting mechanistic disease understanding and empowering clinical trials.
DBGDGM: Dynamic Brain Graph Deep Generative Model
Jan 26, 2023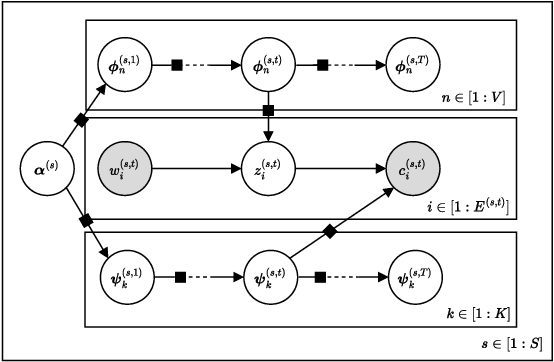
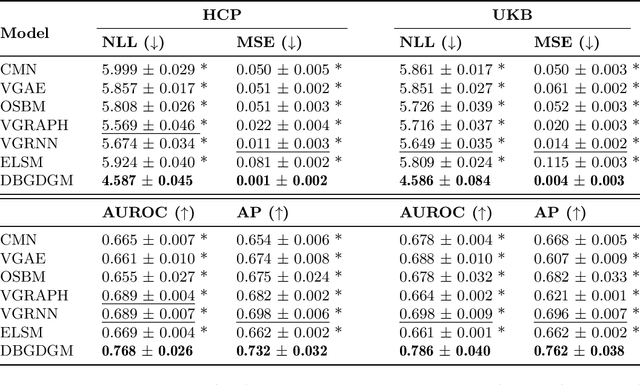
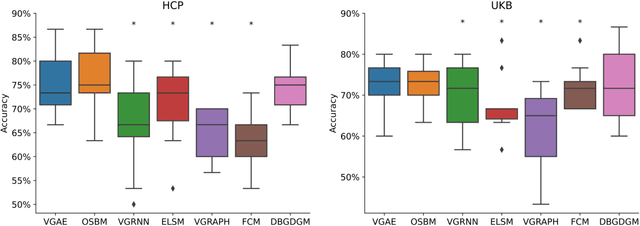

Graphs are a natural representation of brain activity derived from functional magnetic imaging (fMRI) data. It is well known that clusters of anatomical brain regions, known as functional connectivity networks (FCNs), encode temporal relationships which can serve as useful biomarkers for understanding brain function and dysfunction. Previous works, however, ignore the temporal dynamics of the brain and focus on static graphs. In this paper, we propose a dynamic brain graph deep generative model (DBGDGM) which simultaneously clusters brain regions into temporally evolving communities and learns dynamic unsupervised node embeddings. Specifically, DBGDGM represents brain graph nodes as embeddings sampled from a distribution over communities that evolve over time. We parameterise this community distribution using neural networks that learn from subject and node embeddings as well as past community assignments. Experiments demonstrate DBGDGM outperforms baselines in graph generation, dynamic link prediction, and is comparable for graph classification. Finally, an analysis of the learnt community distributions reveals overlap with known FCNs reported in neuroscience literature.
VAESim: A probabilistic approach for self-supervised prototype discovery
Sep 25, 2022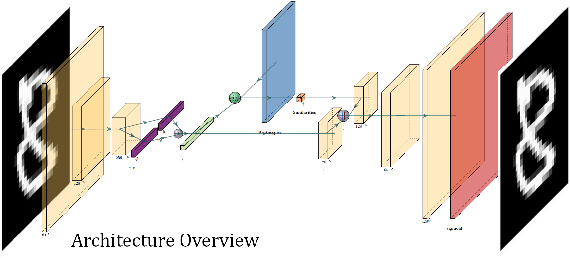
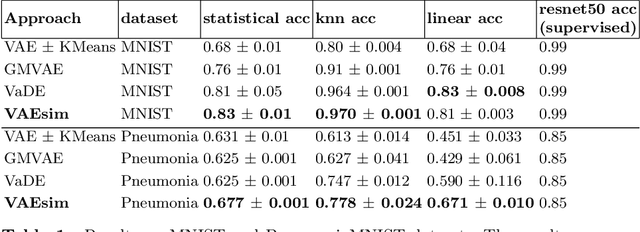
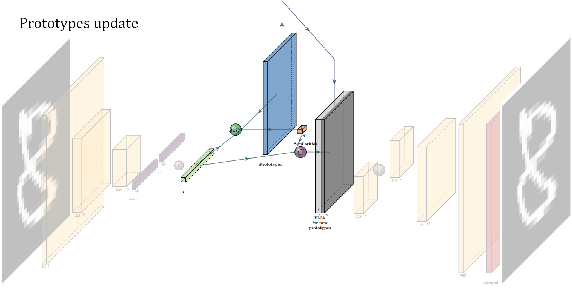

In medicine, curated image datasets often employ discrete labels to describe what is known to be a continuous spectrum of healthy to pathological conditions, such as e.g. the Alzheimer's Disease Continuum or other areas where the image plays a pivotal point in diagnosis. We propose an architecture for image stratification based on a conditional variational autoencoder. Our framework, VAESim, leverages a continuous latent space to represent the continuum of disorders and finds clusters during training, which can then be used for image/patient stratification. The core of the method learns a set of prototypical vectors, each associated with a cluster. First, we perform a soft assignment of each data sample to the clusters. Then, we reconstruct the sample based on a similarity measure between the sample embedding and the prototypical vectors of the clusters. To update the prototypical embeddings, we use an exponential moving average of the most similar representations between actual prototypes and samples in the batch size. We test our approach on the MNIST-handwritten digit dataset and on a medical benchmark dataset called PneumoniaMNIST. We demonstrate that our method outperforms baselines in terms of kNN accuracy measured on a classification task against a standard VAE (up to 15% improvement in performance) in both datasets, and also performs at par with classification models trained in a fully supervised way. We also demonstrate how our model outperforms current, end-to-end models for unsupervised stratification.
Contrastive learning for unsupervised medical image clustering and reconstruction
Sep 24, 2022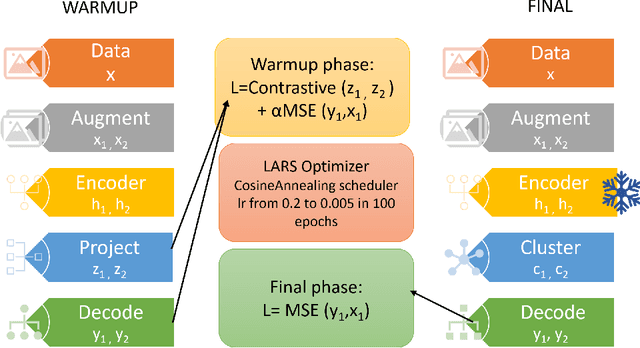
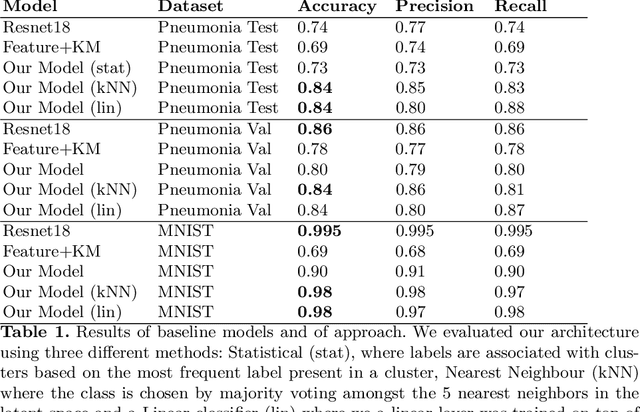
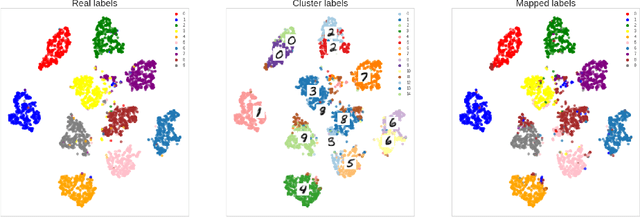
The lack of large labeled medical imaging datasets, along with significant inter-individual variability compared to clinically established disease classes, poses significant challenges in exploiting medical imaging information in a precision medicine paradigm, where in principle dense patient-specific data can be employed to formulate individual predictions and/or stratify patients into finer-grained groups which may follow more homogeneous trajectories and therefore empower clinical trials. In order to efficiently explore the effective degrees of freedom underlying variability in medical images in an unsupervised manner, in this work we propose an unsupervised autoencoder framework which is augmented with a contrastive loss to encourage high separability in the latent space. The model is validated on (medical) benchmark datasets. As cluster labels are assigned to each example according to cluster assignments, we compare performance with a supervised transfer learning baseline. Our method achieves similar performance to the supervised architecture, indicating that separation in the latent space reproduces expert medical observer-assigned labels. The proposed method could be beneficial for patient stratification, exploring new subdivisions of larger classes or pathological continua or, due to its sampling abilities in a variation setting, data augmentation in medical image processing.
GRADE: Graph Dynamic Embedding
Jul 16, 2020
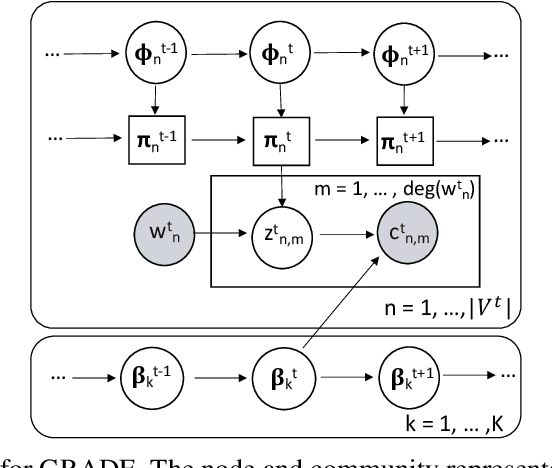


Representation learning of static and more recently dynamically evolving graphs has gained noticeable attention. Existing approaches for modelling graph dynamics focus extensively on the evolution of individual nodes independently of the evolution of mesoscale community structures. As a result, current methods do not provide useful tools to study and cannot explicitly capture temporal community dynamics. To address this challenge, we propose GRADE - a probabilistic model that learns to generate evolving node and community representations by imposing a random walk prior over their trajectories. Our model also learns node community membership which is updated between time steps via a transition matrix. At each time step link generation is performed by first assigning node membership from a distribution over the communities, and then sampling a neighbor from a distribution over the nodes for the assigned community. We parametrize the node and community distributions with neural networks and learn their parameters via variational inference. Experiments demonstrate GRADE meets or outperforms baselines in dynamic link prediction, shows favourable performance on dynamic community detection, and identifies coherent and interpretable evolving communities.
RicciNets: Curvature-guided Pruning of High-performance Neural Networks Using Ricci Flow
Jul 08, 2020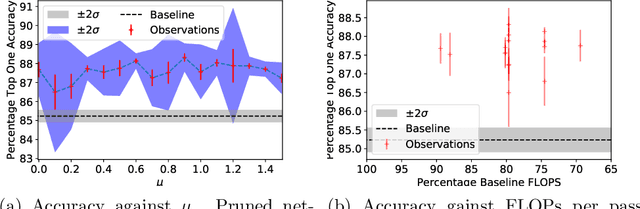
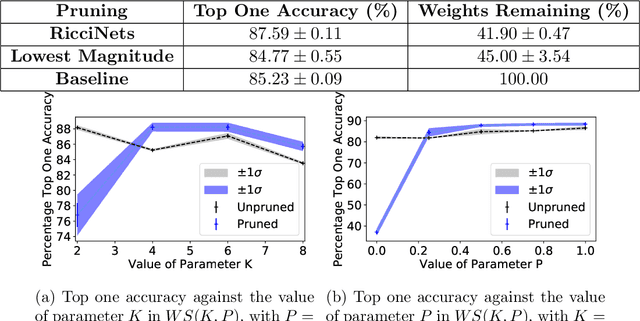
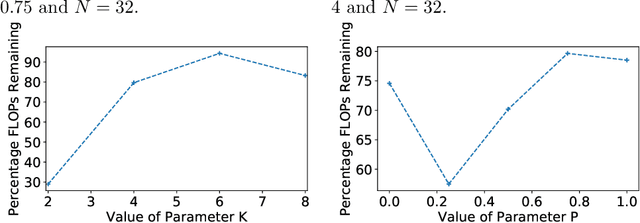
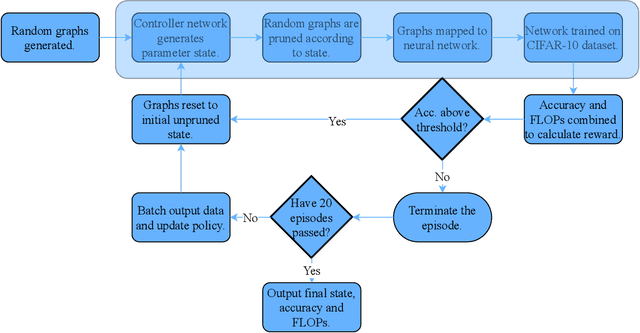
A novel method to identify salient computational paths within randomly wired neural networks before training is proposed. The computational graph is pruned based on a node mass probability function defined by local graph measures and weighted by hyperparameters produced by a reinforcement learning-based controller neural network. We use the definition of Ricci curvature to remove edges of low importance before mapping the computational graph to a neural network. We show a reduction of almost $35\%$ in the number of floating-point operations (FLOPs) per pass, with no degradation in performance. Further, our method can successfully regularize randomly wired neural networks based on purely structural properties, and also find that the favourable characteristics identified in one network generalise to other networks. The method produces networks with better performance under similar compression to those pruned by lowest-magnitude weights. To our best knowledge, this is the first work on pruning randomly wired neural networks, as well as the first to utilize the topological measure of Ricci curvature in the pruning mechanism.
Co-Attentive Cross-Modal Deep Learning for Medical Evidence Synthesis and Decision Making
Sep 13, 2019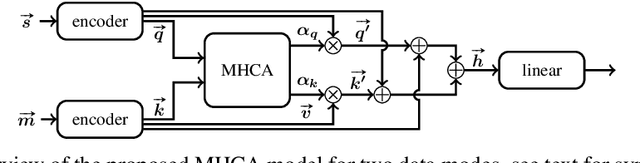


Modern medicine requires generalised approaches to the synthesis and integration of multimodal data, often at different biological scales, that can be applied to a variety of evidence structures, such as complex disease analyses and epidemiological models. However, current methods are either slow and expensive, or ineffective due to the inability to model the complex relationships between data modes which differ in scale and format. We address these issues by proposing a cross-modal deep learning architecture and co-attention mechanism to accurately model the relationships between the different data modes, while further reducing patient diagnosis time. Differentiating Parkinson's Disease (PD) patients from healthy patients forms the basis of the evaluation. The model outperforms the previous state-of-the-art unimodal analysis by 2.35%, while also being 53% more parameter efficient than the industry standard cross-modal model. Furthermore, the evaluation of the attention coefficients allows for qualitative insights to be obtained. Through the coupling with bioinformatics, a novel link between the interferon-gamma-mediated pathway, DNA methylation and PD was identified. We believe that our approach is general and could optimise the process of medical evidence synthesis and decision making in an actionable way.