 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Fusion with Kullback--Leibler Divergence
Jul 13, 2020

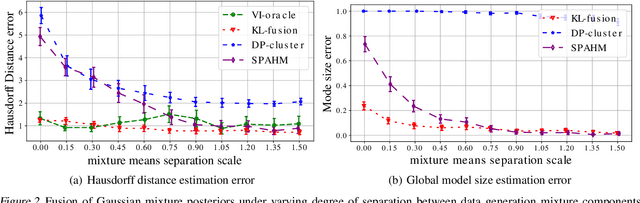
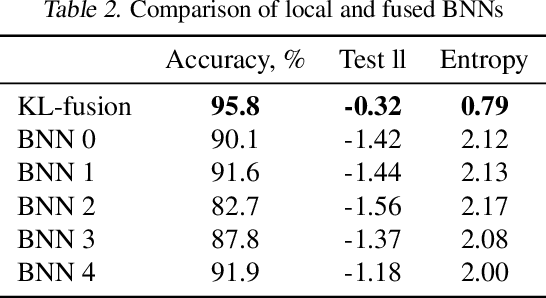
We propose a method to fuse posterior distributions learned from heterogeneous datasets. Our algorithm relies on a mean field assumption for both the fused model and the individual dataset posteriors and proceeds using a simple assign-and-average approach. The components of the dataset posteriors are assigned to the proposed global model components by solving a regularized variant of the assignment problem. The global components are then updated based on these assignments by their mean under a KL divergence. For exponential family variational distributions, our formulation leads to an efficient non-parametric algorithm for computing the fused model. Our algorithm is easy to describe and implement, efficient, and competitive with state-of-the-art on motion capture analysis, topic modeling, and federated learning of Bayesian neural networks.
Incorporating Unlabeled Data into Distributionally Robust Learning
Dec 18, 2019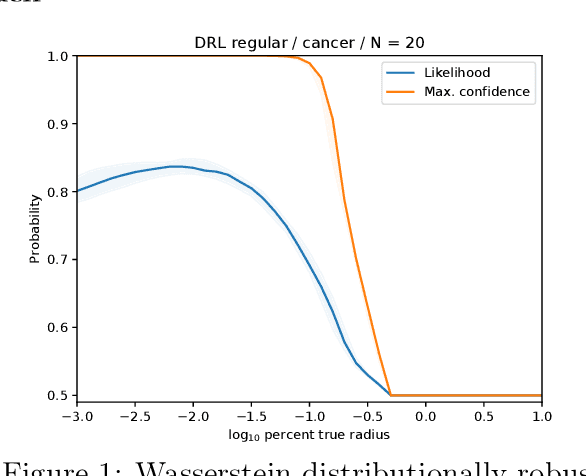

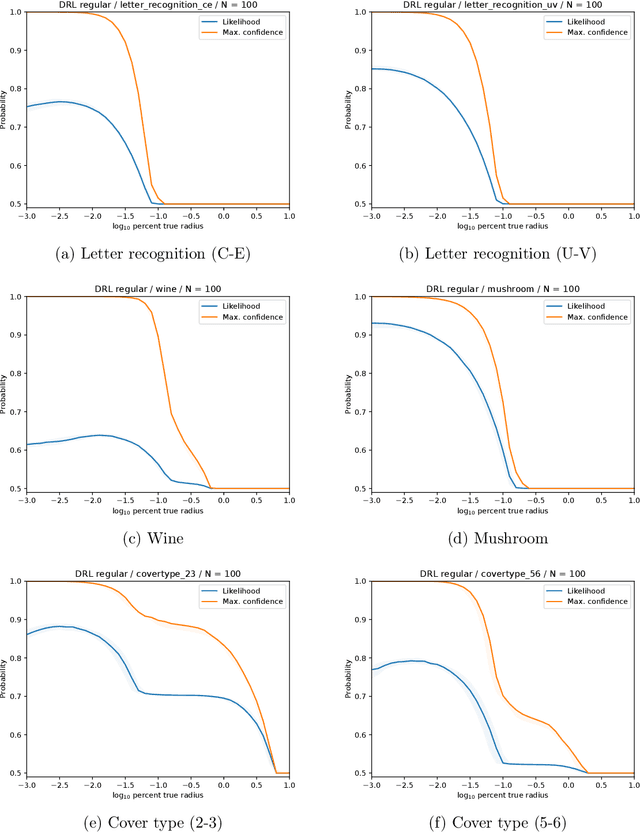
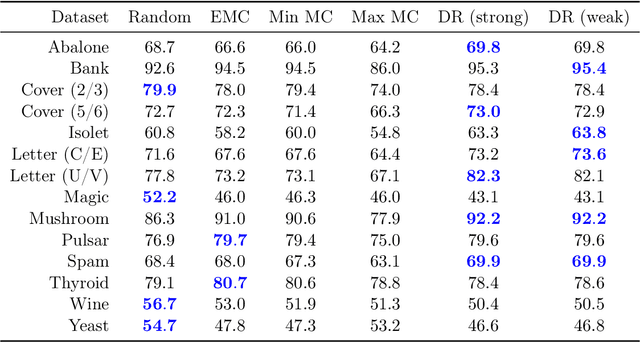
We study a robust alternative to empirical risk minimization called distributionally robust learning (DRL), in which one learns to perform against an adversary who can choose the data distribution from a specified set of distributions. We illustrate a problem with current DRL formulations, which rely on an overly broad definition of allowed distributions for the adversary, leading to learned classifiers that are unable to predict with any confidence. We propose a solution that incorporates unlabeled data into the DRL problem to further constrain the adversary. We show that this new formulation is tractable for stochastic gradient-based optimization and yields a computable guarantee on the future performance of the learned classifier, analogous to -- but tighter than -- guarantees from conventional DRL. We examine the performance of this new formulation on 14 real datasets and find that it often yields effective classifiers with nontrivial performance guarantees in situations where conventional DRL produces neither. Inspired by these results, we extend our DRL formulation to active learning with a novel, distributionally-robust version of the standard model-change heuristic. Our active learning algorithm often achieves superior learning performance to the original heuristic on real datasets.
Alleviating Label Switching with Optimal Transport
Nov 10, 2019

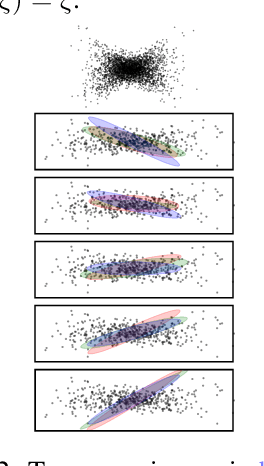
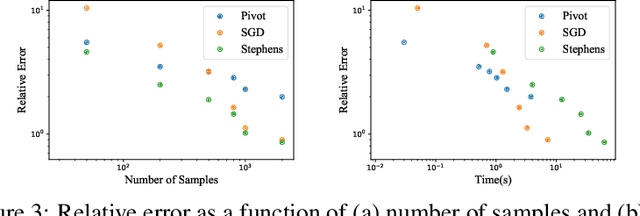
Label switching is a phenomenon arising in mixture model posterior inference that prevents one from meaningfully assessing posterior statistics using standard Monte Carlo procedures. This issue arises due to invariance of the posterior under actions of a group; for example, permuting the ordering of mixture components has no effect on the likelihood. We propose a resolution to label switching that leverages machinery from optimal transport. Our algorithm efficiently computes posterior statistics in the quotient space of the symmetry group. We give conditions under which there is a meaningful solution to label switching and demonstrate advantages over alternative approaches on simulated and real data.
Hierarchical Optimal Transport for Document Representation
Jun 26, 2019
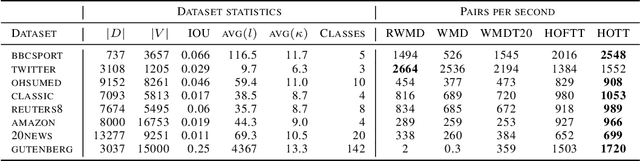
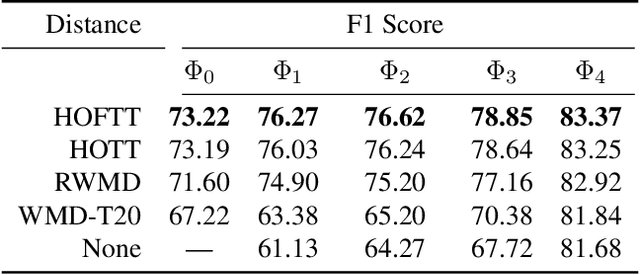

The ability to measure similarity between documents enables intelligent summarization and analysis of large corpora. Past distances between documents suffer from either an inability to incorporate semantic similarities between words or from scalability issues. As an alternative, we introduce hierarchical optimal transport as a meta-distance between documents, where documents are modeled as distributions over topics, which themselves are modeled as distributions over words. We then solve an optimal transport problem on the smaller topic space to compute a similarity score. We give conditions on the topics under which this construction defines a distance, and we relate it to the word mover's distance. We evaluate our technique for $k$-NN classification and show better interpretability and scalability with comparable performance to current methods at a fraction of the cost.
Stochastic Wasserstein Barycenters
Jun 07, 2018



We present a stochastic algorithm to compute the barycenter of a set of probability distributions under the Wasserstein metric from optimal transport. Unlike previous approaches, our method extends to continuous input distributions and allows the support of the barycenter to be adjusted in each iteration. We tackle the problem without regularization, allowing us to recover a sharp output whose support is contained within the support of the true barycenter. We give examples where our algorithm recovers a more meaningful barycenter than previous work. Our method is versatile and can be extended to applications such as generating super samples from a given distribution and recovering blue noise approximations.
Wasserstein Coresets for Lipschitz Costs
May 18, 2018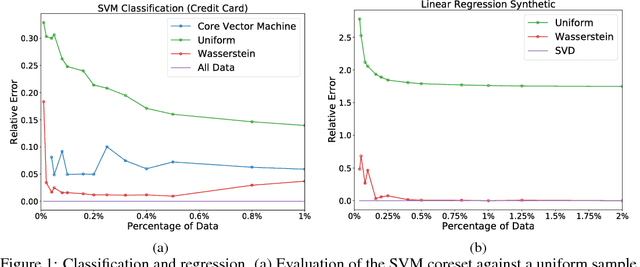
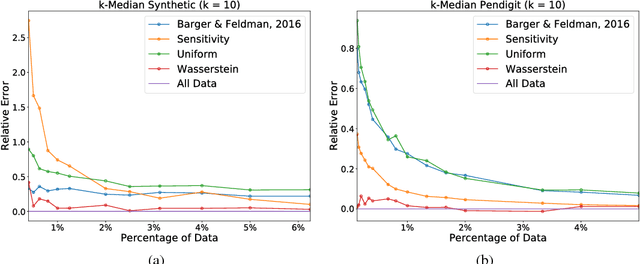
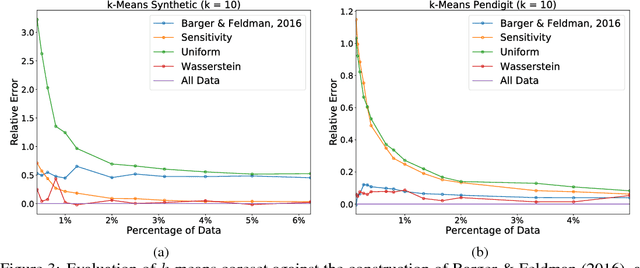
Sparsification is becoming more and more relevant with the proliferation of huge data sets. Coresets are a principled way to construct representative weighted subsets of a data set that have matching performance with the full data set for specific problems. However, coreset language neglects the nature of the underlying data distribution, which is often continuous. In this paper, we address this oversight by introducing a notion of measure coresets that generalizes coreset language to arbitrary probability measures. Our definition reveals a surprising connection to optimal transport theory which we leverage to design a coreset for problems with Lipschitz costs. We validate our construction on support vector machine (SVM) training, k-means clustering, k-median clustering, and linear regression and show that we are competitive with previous coreset constructions.
Parallel Streaming Wasserstein Barycenters
Nov 14, 2017

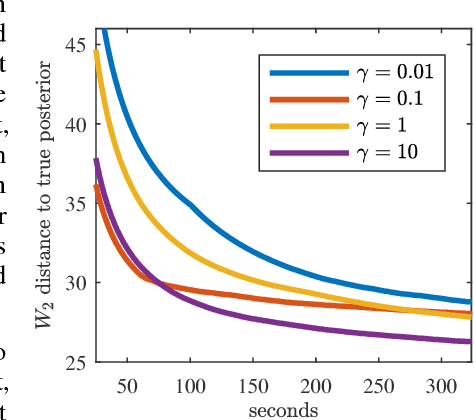
Efficiently aggregating data from different sources is a challenging problem, particularly when samples from each source are distributed differently. These differences can be inherent to the inference task or present for other reasons: sensors in a sensor network may be placed far apart, affecting their individual measurements. Conversely, it is computationally advantageous to split Bayesian inference tasks across subsets of data, but data need not be identically distributed across subsets. One principled way to fuse probability distributions is via the lens of optimal transport: the Wasserstein barycenter is a single distribution that summarizes a collection of input measures while respecting their geometry. However, computing the barycenter scales poorly and requires discretization of all input distributions and the barycenter itself. Improving on this situation, we present a scalable, communication-efficient, parallel algorithm for computing the Wasserstein barycenter of arbitrary distributions. Our algorithm can operate directly on continuous input distributions and is optimized for streaming data. Our method is even robust to nonstationary input distributions and produces a barycenter estimate that tracks the input measures over time. The algorithm is semi-discrete, needing to discretize only the barycenter estimate. To the best of our knowledge, we also provide the first bounds on the quality of the approximate barycenter as the discretization becomes finer. Finally, we demonstrate the practical effectiveness of our method, both in tracking moving distributions on a sphere, as well as in a large-scale Bayesian inference task.