 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Unlabeled Data into Distributionally Robust Learning
Dec 18, 2019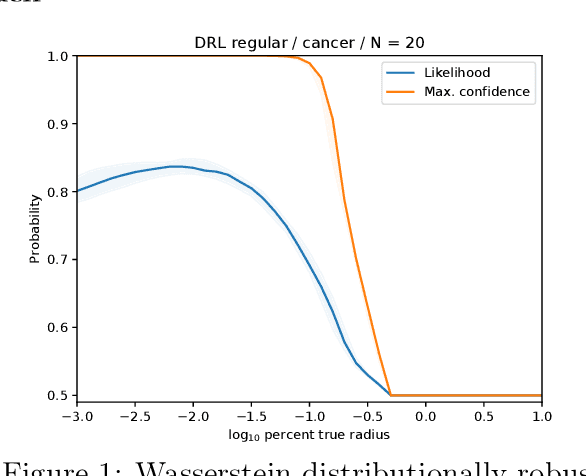

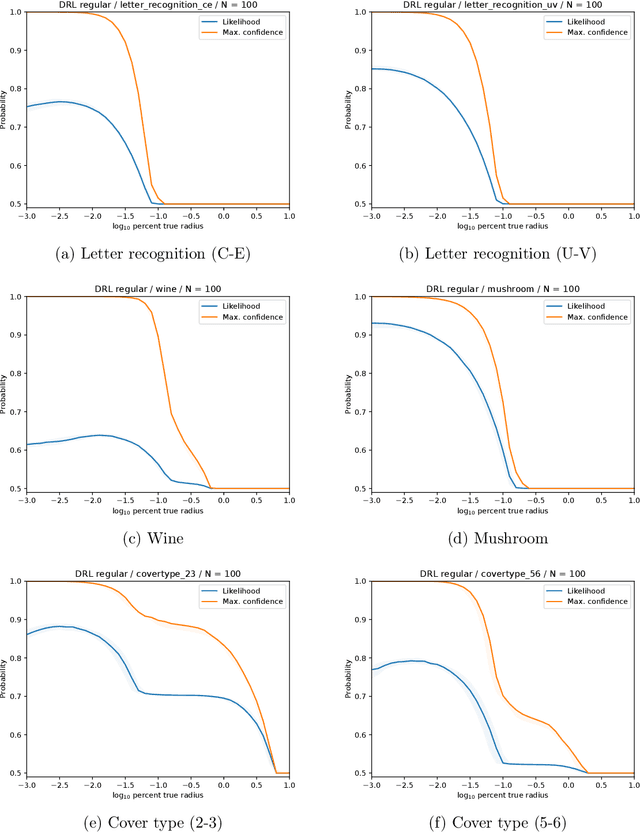
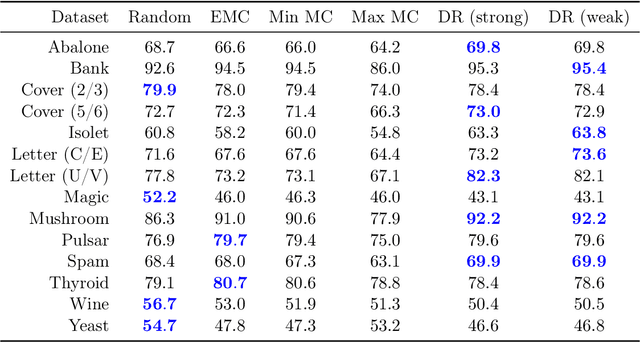
We study a robust alternative to empirical risk minimization called distributionally robust learning (DRL), in which one learns to perform against an adversary who can choose the data distribution from a specified set of distributions. We illustrate a problem with current DRL formulations, which rely on an overly broad definition of allowed distributions for the adversary, leading to learned classifiers that are unable to predict with any confidence. We propose a solution that incorporates unlabeled data into the DRL problem to further constrain the adversary. We show that this new formulation is tractable for stochastic gradient-based optimization and yields a computable guarantee on the future performance of the learned classifier, analogous to -- but tighter than -- guarantees from conventional DRL. We examine the performance of this new formulation on 14 real datasets and find that it often yields effective classifiers with nontrivial performance guarantees in situations where conventional DRL produces neither. Inspired by these results, we extend our DRL formulation to active learning with a novel, distributionally-robust version of the standard model-change heuristic. Our active learning algorithm often achieves superior learning performance to the original heuristic on real datasets.
Learning Embeddings into Entropic Wasserstein Spaces
May 08, 2019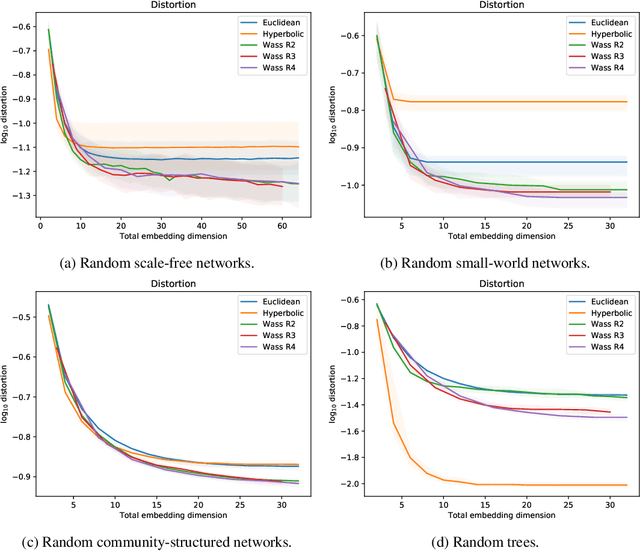

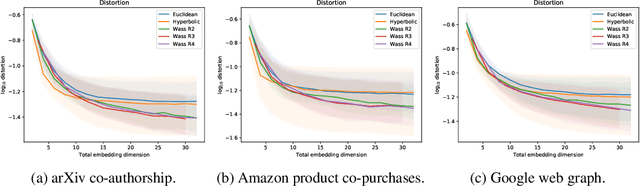

Euclidean embeddings of data are fundamentally limited in their ability to capture latent semantic structures, which need not conform to Euclidean spatial assumptions. Here we consider an alternative, which embeds data as discrete probability distributions in a Wasserstein space, endowed with an optimal transport metric. Wasserstein spaces are much larger and more flexible than Euclidean spaces, in that they can successfully embed a wider variety of metric structures. We exploit this flexibility by learning an embedding that captures semantic information in the Wasserstein distance between embedded distributions. We examine empirically the representational capacity of our learned Wasserstein embeddings, showing that they can embed a wide variety of metric structures with smaller distortion than an equivalent Euclidean embedding. We also investigate an application to word embedding, demonstrating a unique advantage of Wasserstein embeddings: We can visualize the high-dimensional embedding directly, since it is a probability distribution on a low-dimensional space. This obviates the need for dimensionality reduction techniques like t-SNE for visualization.
Approximate inference with Wasserstein gradient flows
Jun 12, 2018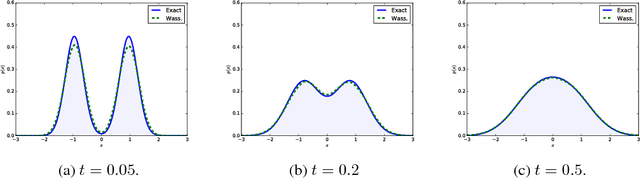
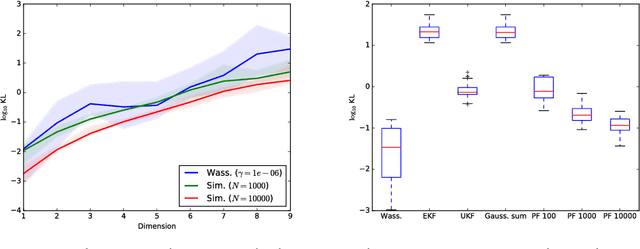
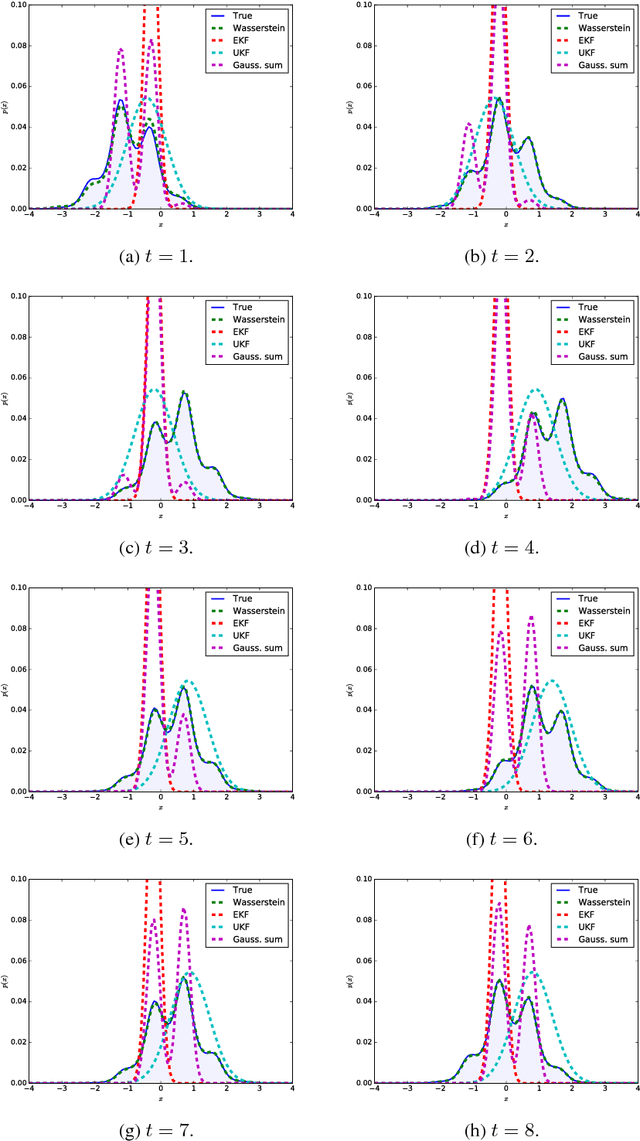
We present a novel approximate inference method for diffusion processes, based on the Wasserstein gradient flow formulation of the diffusion. In this formulation, the time-dependent density of the diffusion is derived as the limit of implicit Euler steps that follow the gradients of a particular free energy functional. Existing methods for computing Wasserstein gradient flows rely on discretization of the domain of the diffusion, prohibiting their application to domains in more than several dimensions. We propose instead a discretization-free inference method that computes the Wasserstein gradient flow directly in a space of continuous functions. We characterize approximation properties of the proposed method and evaluate it on a nonlinear filtering task, finding performance comparable to the state-of-the-art for filtering diffusions.
Learning with a Wasserstein Loss
Dec 30, 2015

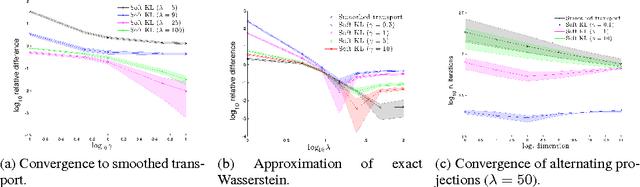
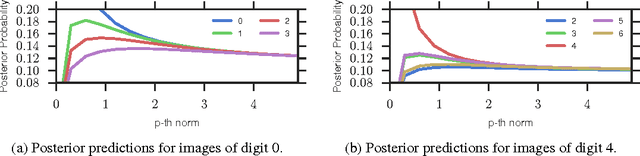
Learning to predict multi-label outputs is challenging, but in many problems there is a natural metric on the outputs that can be used to improve predictions. In this paper we develop a loss function for multi-label learning, based on the Wasserstein distance. The Wasserstein distance provides a natural notion of dissimilarity for probability measures. Although optimizing with respect to the exact Wasserstein distance is costly, recent work has described a regularized approximation that is efficiently computed. We describe an efficient learning algorithm based on this regularization, as well as a novel extension of the Wasserstein distance from probability measures to unnormalized measures. We also describe a statistical learning bound for the loss. The Wasserstein loss can encourage smoothness of the predictions with respect to a chosen metric on the output space. We demonstrate this property on a real-data tag prediction problem, using the Yahoo Flickr Creative Commons dataset, outperforming a baseline that doesn't use the metric.