 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Bi-Manual Block Assembly via Sim-to-Real Reinforcement Learning
Mar 27, 2023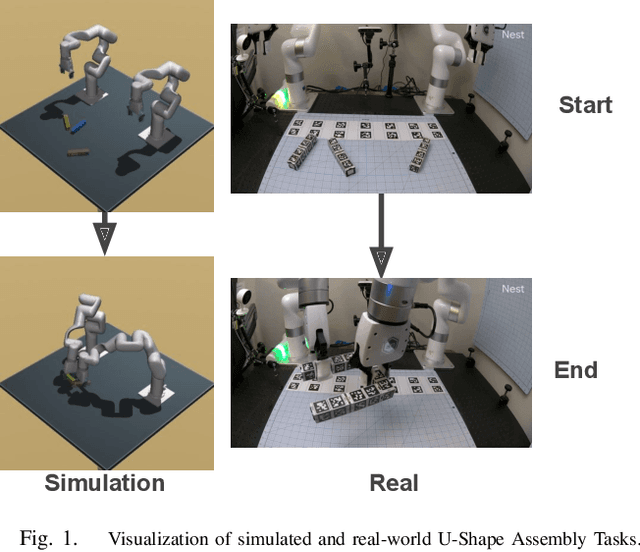

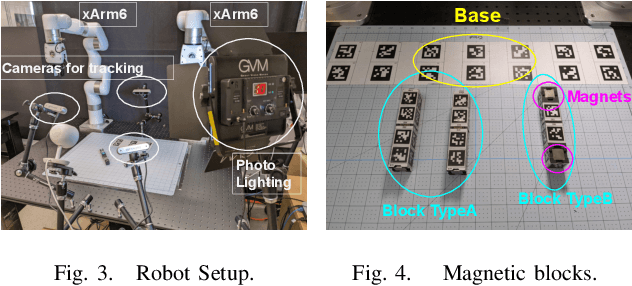
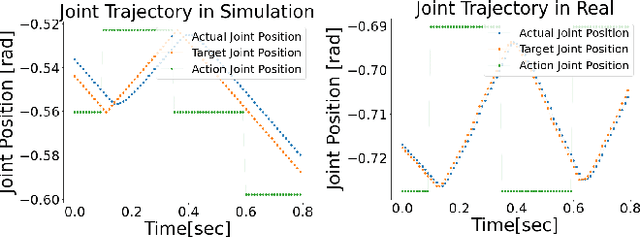
Most successes in robotic manipulation have been restricted to single-arm gripper robots, whose low dexterity limits the range of solvable tasks to pick-and-place, inser-tion, and object rearrangement. More complex tasks such as assembly require dual and multi-arm platforms, but entail a suite of unique challenges such as bi-arm coordination and collision avoidance, robust grasping, and long-horizon planning. In this work we investigate the feasibility of training deep reinforcement learning (RL) policies in simulation and transferring them to the real world (Sim2Real) as a generic methodology for obtaining performant controllers for real-world bi-manual robotic manipulation tasks. As a testbed for bi-manual manipulation, we develop the U-Shape Magnetic BlockAssembly Task, wherein two robots with parallel grippers must connect 3 magnetic blocks to form a U-shape. Without manually-designed controller nor human demonstrations, we demonstrate that with careful Sim2Real considerations, our policies trained with RL in simulation enable two xArm6 robots to solve the U-shape assembly task with a success rate of above90% in simulation, and 50% on real hardware without any additional real-world fine-tuning. Through careful ablations,we highlight how each component of the system is critical for such simple and successful policy learning and transfer,including task specification, learning algorithm, direct joint-space control, behavior constraints, perception and actuation noises, action delays and action interpolation. Our results present a significant step forward for bi-arm capability on real hardware, and we hope our system can inspire future research on deep RL and Sim2Real transfer of bi-manualpolicies, drastically scaling up the capability of real-world robot manipulators.
Blocks Assemble! Learning to Assemble with Large-Scale Structured Reinforcement Learning
Apr 12, 2022

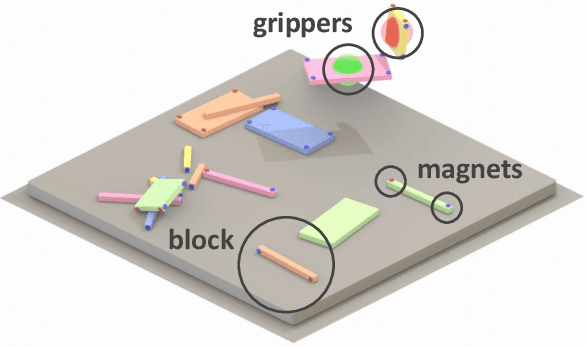

Assembly of multi-part physical structures is both a valuable end product for autonomous robotics, as well as a valuable diagnostic task for open-ended training of embodied intelligent agents. We introduce a naturalistic physics-based environment with a set of connectable magnet blocks inspired by children's toy kits. The objective is to assemble blocks into a succession of target blueprints. Despite the simplicity of this objective, the compositional nature of building diverse blueprints from a set of blocks leads to an explosion of complexity in structures that agents encounter. Furthermore, assembly stresses agents' multi-step planning, physical reasoning, and bimanual coordination. We find that the combination of large-scale reinforcement learning and graph-based policies -- surprisingly without any additional complexity -- is an effective recipe for training agents that not only generalize to complex unseen blueprints in a zero-shot manner, but even operate in a reset-free setting without being trained to do so. Through extensive experiments, we highlight the importance of large-scale training, structured representations, contributions of multi-task vs. single-task learning, as well as the effects of curriculums, and discuss qualitative behaviors of trained agents.
Bi-Manual Manipulation and Attachment via Sim-to-Real Reinforcement Learning
Mar 15, 2022
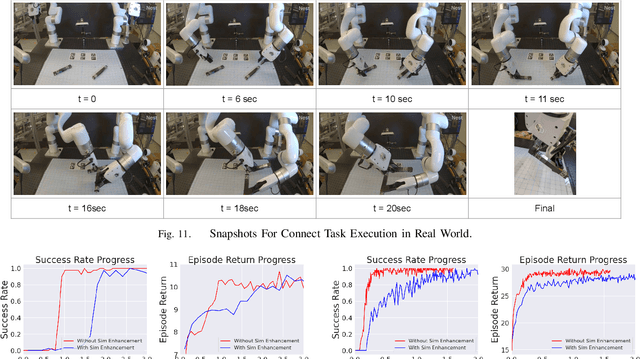
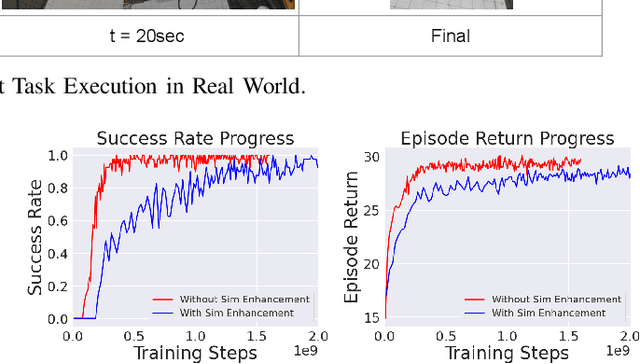

Most successes in robotic manipulation have been restricted to single-arm robots, which limits the range of solvable tasks to pick-and-place, insertion, and objects rearrangement. In contrast, dual and multi arm robot platforms unlock a rich diversity of problems that can be tackled, such as laundry folding and executing cooking skills. However, developing controllers for multi-arm robots is complexified by a number of unique challenges, such as the need for coordinated bimanual behaviors, and collision avoidance amongst robots. Given these challenges, in this work we study how to solve bi-manual tasks using reinforcement learning (RL) trained in simulation, such that the resulting policies can be executed on real robotic platforms. Our RL approach results in significant simplifications due to using real-time (4Hz) joint-space control and directly passing unfiltered observations to neural networks policies. We also extensively discuss modifications to our simulated environment which lead to effective training of RL policies. In addition to designing control algorithms, a key challenge is how to design fair evaluation tasks for bi-manual robots that stress bimanual coordination, while removing orthogonal complicating factors such as high-level perception. In this work, we design a Connect Task, where the aim is for two robot arms to pick up and attach two blocks with magnetic connection points. We validate our approach with two xArm6 robots and 3D printed blocks with magnetic attachments, and find that our system has 100% success rate at picking up blocks, and 65% success rate at the Connect Task.