 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Object Grounding and Mapping for Natural Language Robot Instruction Following
Nov 14, 2020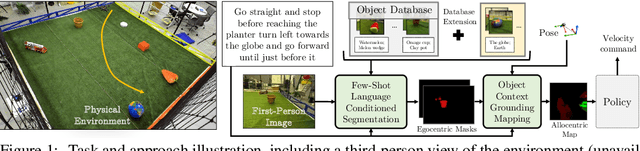
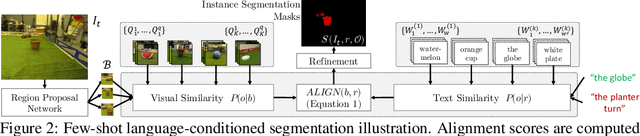
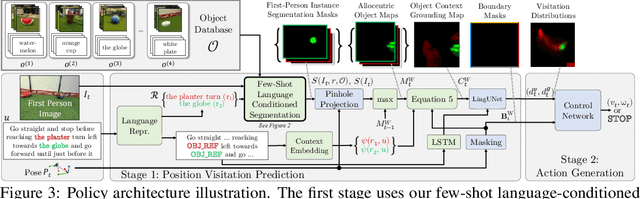
We study the problem of learning a robot policy to follow natural language instructions that can be easily extended to reason about new objects. We introduce a few-shot language-conditioned object grounding method trained from augmented reality data that uses exemplars to identify objects and align them to their mentions in instructions. We present a learned map representation that encodes object locations and their instructed use, and construct it from our few-shot grounding output. We integrate this mapping approach into an instruction-following policy, thereby allowing it to reason about previously unseen objects at test-time by simply adding exemplars. We evaluate on the task of learning to map raw observations and instructions to continuous control of a physical quadcopter. Our approach significantly outperforms the prior state of the art in the presence of new objects, even when the prior approach observes all objects during training.
An Information-Theoretic Approach to Persistent Environment Monitoring Through Low Rank Model Based Planning and Prediction
Sep 02, 2020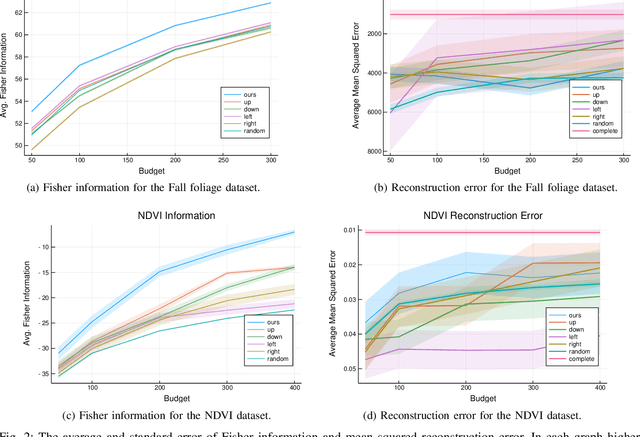
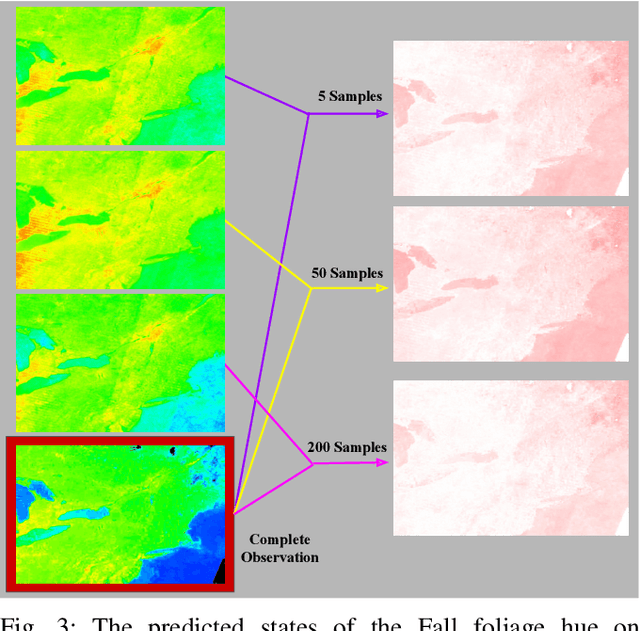
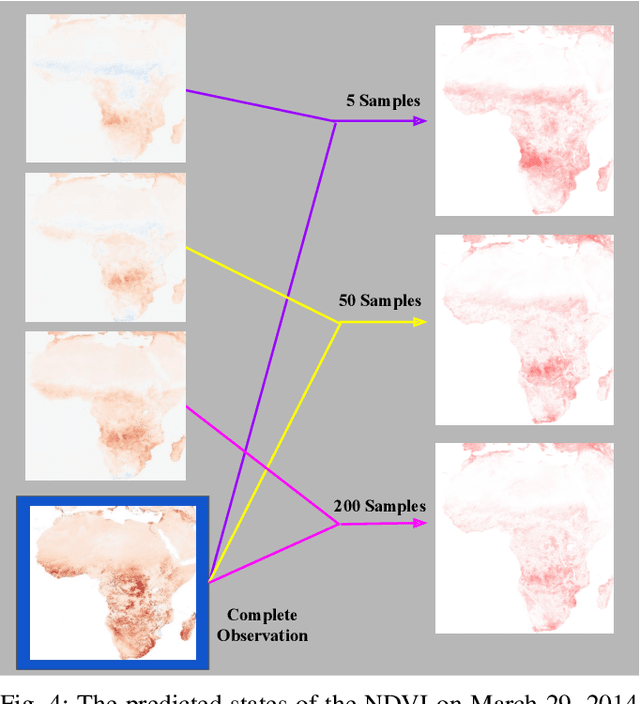
Robots can be used to collect environmental data in regions that are difficult for humans to traverse. However, limitations remain in the size of region that a robot can directly observe per unit time. We introduce a method for selecting a limited number of observation points in a large region, from which we can predict the state of unobserved points in the region. We combine a low rank model of a target attribute with an information-maximizing path planner to predict the state of the attribute throughout a region. Our approach is agnostic to the choice of target attribute and robot monitoring platform. We evaluate our method in simulation on two real-world environment datasets, each containing observations from one to two million possible sampling locations. We compare against a random sampler and four variations of a baseline sampler from the ecology literature. Our method outperforms the baselines in terms of average Fisher information gain per samples taken and performs comparably for average reconstruction error in most trials.
Learning to Map Natural Language Instructions to Physical Quadcopter Control using Simulated Flight
Oct 21, 2019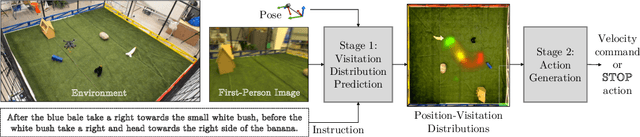
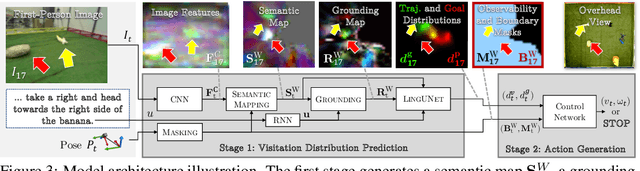

We propose a joint simulation and real-world learning framework for mapping navigation instructions and raw first-person observations to continuous control. Our model estimates the need for environment exploration, predicts the likelihood of visiting environment positions during execution, and controls the agent to both explore and visit high-likelihood positions. We introduce Supervised Reinforcement Asynchronous Learning (SuReAL). Learning uses both simulation and real environments without requiring autonomous flight in the physical environment during training, and combines supervised learning for predicting positions to visit and reinforcement learning for continuous control. We evaluate our approach on a natural language instruction-following task with a physical quadcopter, and demonstrate effective execution and exploration behavior.
Usability Squared: Principles for doing good systems research in robotics
Jun 16, 2019
Despite recent major advances in robotics research, massive injections of capital into robotics startups, and significant market appetite for robotic solutions, large-scale real-world deployments of robotic systems remain relatively scarce outside of heavy industry and (recently) warehouse logistics. In this paper, we posit that this scarcity comes from the difficulty of building even merely functional, first-pass robotic applications without a dizzying breadth and depth of expertise, in contrast to the relative ease with which non-experts in cloud computing can build complex distributed applications that function reasonably well. We trace this difficulty in application building to the paucity of good systems research in robotics, and lay out a path toward enabling application building by centering usability in systems research in two different ways: privileging the usability of the abstractions defined in systems research, and ensuring that the research itself is usable by application developers in the context of evaluating it for its applicability to their target domain by following principles of realism, empiricism, and exhaustive explication. In addition, we make some suggestions for community-level changes, incentives, and initiatives to create a better environment for systems work in robotics.
Mapping Navigation Instructions to Continuous Control Actions with Position-Visitation Prediction
Dec 10, 2018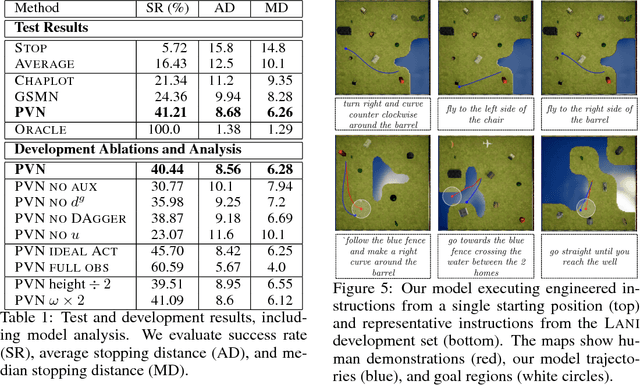
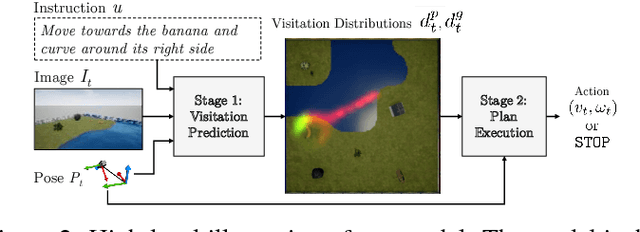
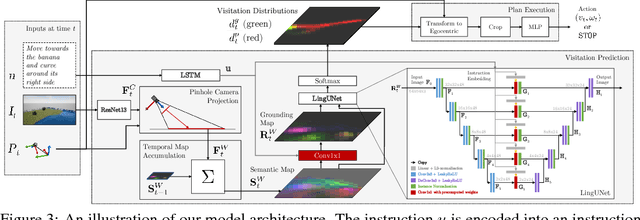

We propose an approach for mapping natural language instructions and raw observations to continuous control of a quadcopter drone. Our model predicts interpretable position-visitation distributions indicating where the agent should go during execution and where it should stop, and uses the predicted distributions to select the actions to execute. This two-step model decomposition allows for simple and efficient training using a combination of supervised learning and imitation learning. We evaluate our approach with a realistic drone simulator, and demonstrate absolute task-completion accuracy improvements of 16.85% over two state-of-the-art instruction-following methods.
* Appeared in Conference on Robot Learning 2018
Following High-level Navigation Instructions on a Simulated Quadcopter with Imitation Learning
May 31, 2018
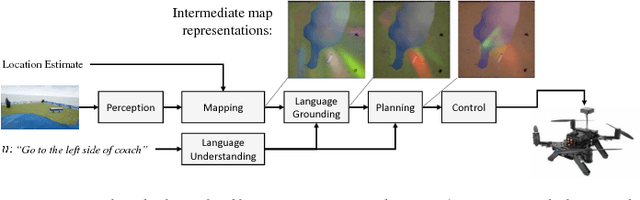

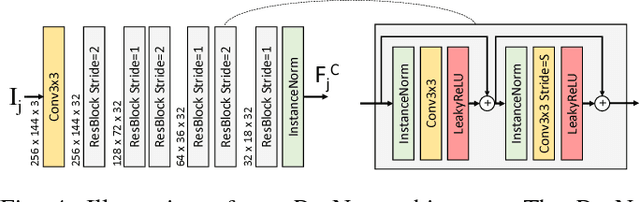
We introduce a method for following high-level navigation instructions by mapping directly from images, instructions and pose estimates to continuous low-level velocity commands for real-time control. The Grounded Semantic Mapping Network (GSMN) is a fully-differentiable neural network architecture that builds an explicit semantic map in the world reference frame by incorporating a pinhole camera projection model within the network. The information stored in the map is learned from experience, while the local-to-world transformation is computed explicitly. We train the model using DAggerFM, a modified variant of DAgger that trades tabular convergence guarantees for improved training speed and memory use. We test GSMN in virtual environments on a realistic quadcopter simulator and show that incorporating an explicit mapping and grounding modules allows GSMN to outperform strong neural baselines and almost reach an expert policy performance. Finally, we analyze the learned map representations and show that using an explicit map leads to an interpretable instruction-following model.