 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Object Grounding and Mapping for Natural Language Robot Instruction Following
Paper and Code
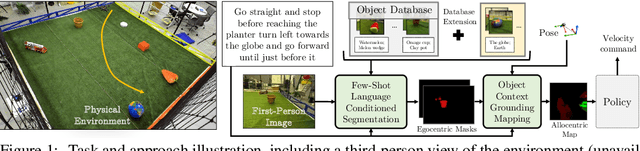
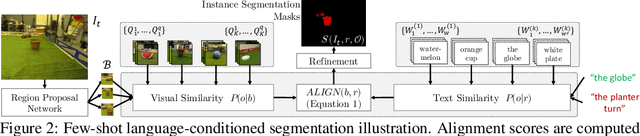
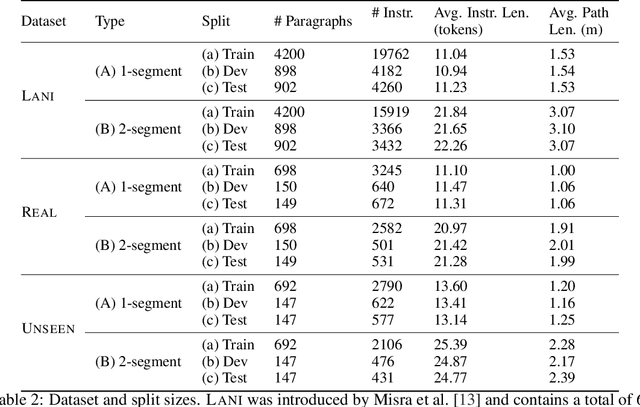
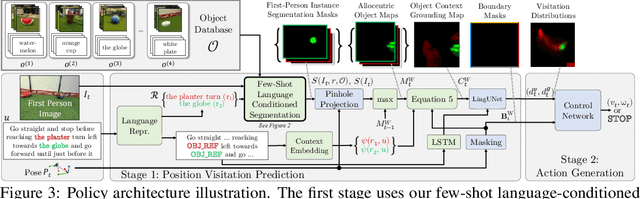
We study the problem of learning a robot policy to follow natural language instructions that can be easily extended to reason about new objects. We introduce a few-shot language-conditioned object grounding method trained from augmented reality data that uses exemplars to identify objects and align them to their mentions in instructions. We present a learned map representation that encodes object locations and their instructed use, and construct it from our few-shot grounding output. We integrate this mapping approach into an instruction-following policy, thereby allowing it to reason about previously unseen objects at test-time by simply adding exemplars. We evaluate on the task of learning to map raw observations and instructions to continuous control of a physical quadcopter. Our approach significantly outperforms the prior state of the art in the presence of new objects, even when the prior approach observes all objects during training.