 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Process Assisted Meta-learning for Image Classification and Object Detection Models
Dec 23, 2025



Collecting operationally realistic data to inform machine learning models can be costly. Before collecting new data, it is helpful to understand where a model is deficient. For example, object detectors trained on images of rare objects may not be good at identification in poorly represented conditions. We offer a way of informing subsequent data acquisition to maximize model performance by leveraging the toolkit of computer experiments and metadata describing the circumstances under which the training data was collected (e.g., season, time of day, location). We do this by evaluating the learner as the training data is varied according to its metadata. A Gaussian process (GP) surrogate fit to that response surface can inform new data acquisitions. This meta-learning approach offers improvements to learner performance as compared to data with randomly selected metadata, which we illustrate on both classic learning examples, and on a motivating application involving the collection of aerial images in search of airplanes.
Modular Jump Gaussian Processes
May 21, 2025Gaussian processes (GPs) furnish accurate nonlinear predictions with well-calibrated uncertainty. However, the typical GP setup has a built-in stationarity assumption, making it ill-suited for modeling data from processes with sudden changes, or "jumps" in the output variable. The "jump GP" (JGP) was developed for modeling data from such processes, combining local GPs and latent "level" variables under a joint inferential framework. But joint modeling can be fraught with difficulty. We aim to simplify by suggesting a more modular setup, eschewing joint inference but retaining the main JGP themes: (a) learning optimal neighborhood sizes that locally respect manifolds of discontinuity; and (b) a new cluster-based (latent) feature to capture regions of distinct output levels on both sides of the manifold. We show that each of (a) and (b) separately leads to dramatic improvements when modeling processes with jumps. In tandem (but without requiring joint inference) that benefit is compounded, as illustrated on real and synthetic benchmark examples from the recent literature.
Voronoi Candidates for Bayesian Optimization
Feb 07, 2024


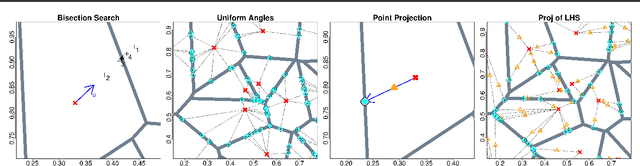
Bayesian optimization (BO) offers an elegant approach for efficiently optimizing black-box functions. However, acquisition criteria demand their own challenging inner-optimization, which can induce significant overhead. Many practical BO methods, particularly in high dimension, eschew a formal, continuous optimization of the acquisition function and instead search discretely over a finite set of space-filling candidates. Here, we propose to use candidates which lie on the boundary of the Voronoi tessellation of the current design points, so they are equidistant to two or more of them. We discuss strategies for efficient implementation by directly sampling the Voronoi boundary without explicitly generating the tessellation, thus accommodating large designs in high dimension. On a battery of test problems optimized via Gaussian processes with expected improvement, our proposed approach significantly improves the execution time of a multi-start continuous search without a loss in accuracy.
Robust expected improvement for Bayesian optimization
Feb 16, 2023Bayesian Optimization (BO) links Gaussian Process (GP) surrogates with sequential design toward optimizing expensive-to-evaluate black-box functions. Example design heuristics, or so-called acquisition functions, like expected improvement (EI), balance exploration and exploitation to furnish global solutions under stringent evaluation budgets. However, they fall short when solving for robust optima, meaning a preference for solutions in a wider domain of attraction. Robust solutions are useful when inputs are imprecisely specified, or where a series of solutions is desired. A common mathematical programming technique in such settings involves an adversarial objective, biasing a local solver away from ``sharp'' troughs. Here we propose a surrogate modeling and active learning technique called robust expected improvement (REI) that ports adversarial methodology into the BO/GP framework. After describing the methods, we illustrate and draw comparisons to several competitors on benchmark synthetic and real problems of varying complexity.
Triangulation candidates for Bayesian optimization
Dec 14, 2021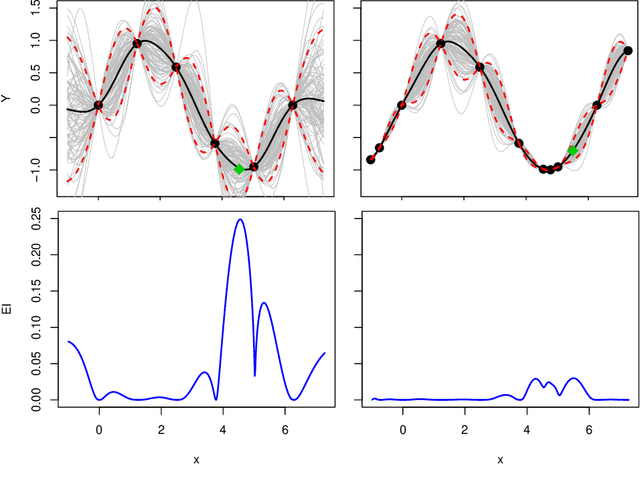
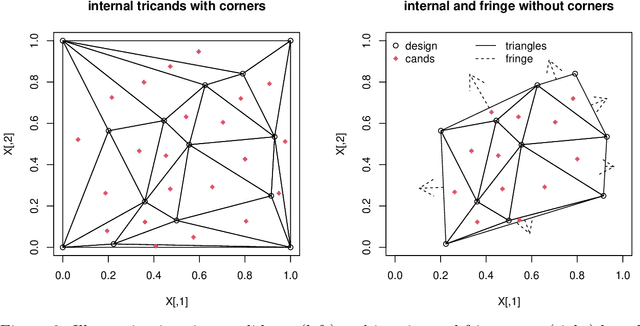
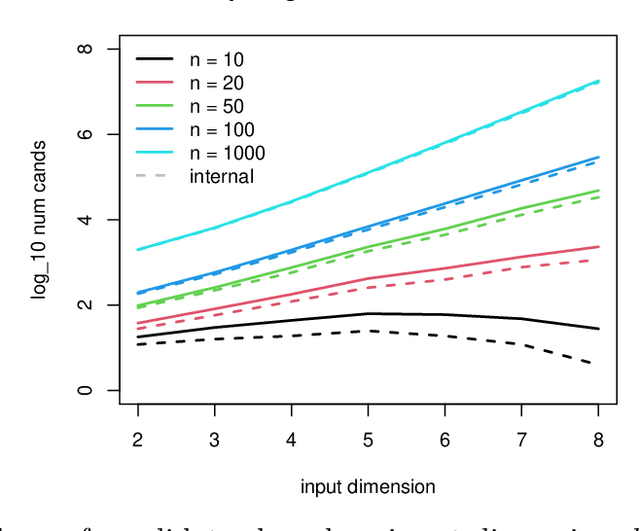

Bayesian optimization is a form of sequential design: idealize input-output relationships with a suitably flexible nonlinear regression model; fit to data from an initial experimental campaign; devise and optimize a criterion for selecting the next experimental condition(s) under the fitted model (e.g., via predictive equations) to target outcomes of interest (say minima); repeat after acquiring output under those conditions and updating the fit. In many situations this "inner optimization" over the new-data acquisition criterion is cumbersome because it is non-convex/highly multi-modal, may be non-differentiable, or may otherwise thwart numerical optimizers, especially when inference requires Monte Carlo. In such cases it is not uncommon to replace continuous search with a discrete one over random candidates. Here we propose using candidates based on a Delaunay triangulation of the existing input design. In addition to detailing construction of these "tricands", based on a simple wrapper around a conventional convex hull library, we promote several advantages based on properties of the geometric criterion involved. We then demonstrate empirically how tricands can lead to better Bayesian optimization performance compared to both numerically optimized acquisitions and random candidate-based alternatives on benchmark problems.
Entropy-based adaptive design for contour finding and estimating reliability
May 24, 2021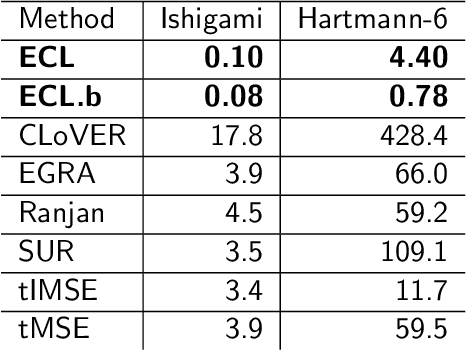
In reliability analysis, methods used to estimate failure probability are often limited by the costs associated with model evaluations. Many of these methods, such as multifidelity importance sampling (MFIS), rely upon a computationally efficient, surrogate model like a Gaussian process (GP) to quickly generate predictions. The quality of the GP fit, particularly in the vicinity of the failure region(s), is instrumental in supplying accurately predicted failures for such strategies. We introduce an entropy-based GP adaptive design that, when paired with MFIS, provides more accurate failure probability estimates and with higher confidence. We show that our greedy data acquisition strategy better identifies multiple failure regions compared to existing contour-finding schemes. We then extend the method to batch selection, without sacrificing accuracy. Illustrative examples are provided on benchmark data as well as an application to an impact damage simulator for National Aeronautics and Space Administration (NASA) spacesuits.
Sensitivity Prewarping for Local Surrogate Modeling
Jan 15, 2021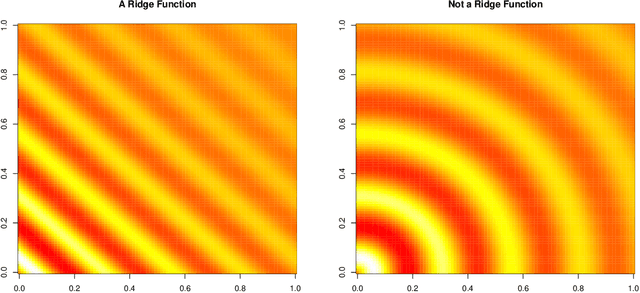
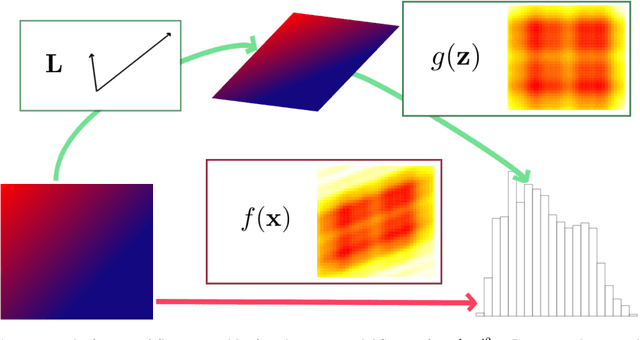
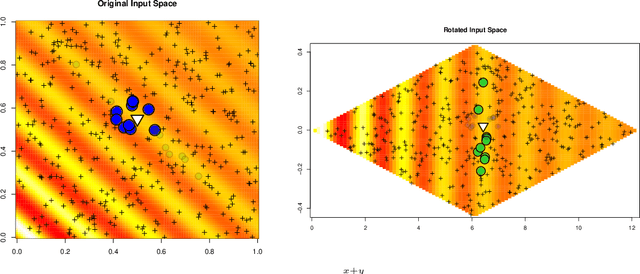
In the continual effort to improve product quality and decrease operations costs, computational modeling is increasingly being deployed to determine feasibility of product designs or configurations. Surrogate modeling of these computer experiments via local models, which induce sparsity by only considering short range interactions, can tackle huge analyses of complicated input-output relationships. However, narrowing focus to local scale means that global trends must be re-learned over and over again. In this article, we propose a framework for incorporating information from a global sensitivity analysis into the surrogate model as an input rotation and rescaling preprocessing step. We discuss the relationship between several sensitivity analysis methods based on kernel regression before describing how they give rise to a transformation of the input variables. Specifically, we perform an input warping such that the "warped simulator" is equally sensitive to all input directions, freeing local models to focus on local dynamics. Numerical experiments on observational data and benchmark test functions, including a high-dimensional computer simulator from the automotive industry, provide empirical validation.
Active Learning for Deep Gaussian Process Surrogates
Dec 15, 2020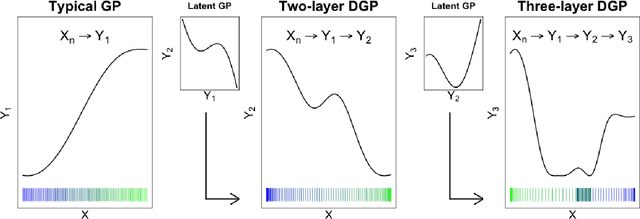
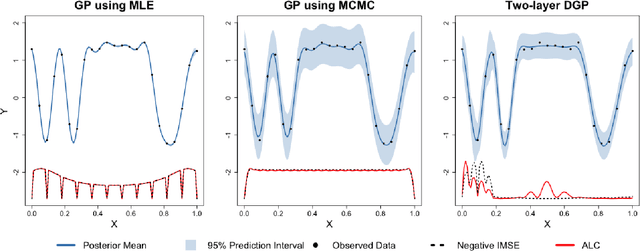
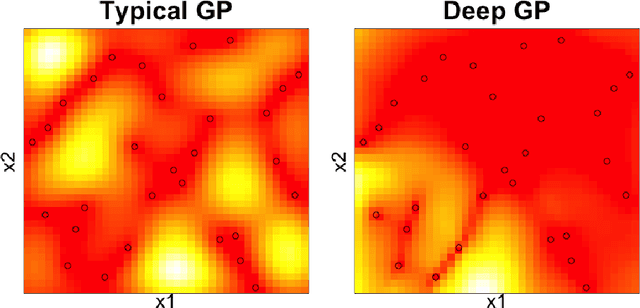
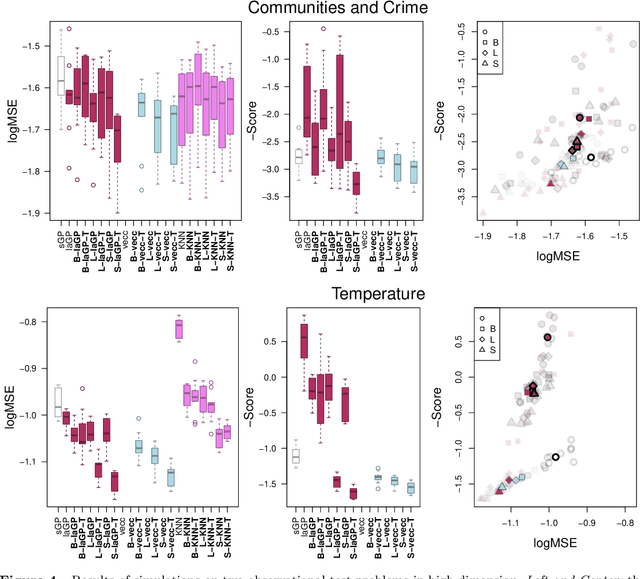
Deep Gaussian processes (DGPs) are increasingly popular as predictive models in machine learning (ML) for their non-stationary flexibility and ability to cope with abrupt regime changes in training data. Here we explore DGPs as surrogates for computer simulation experiments whose response surfaces exhibit similar characteristics. In particular, we transport a DGP's automatic warping of the input space and full uncertainty quantification (UQ), via a novel elliptical slice sampling (ESS) Bayesian posterior inferential scheme, through to active learning (AL) strategies that distribute runs non-uniformly in the input space -- something an ordinary (stationary) GP could not do. Building up the design sequentially in this way allows smaller training sets, limiting both expensive evaluation of the simulator code and mitigating cubic costs of DGP inference. When training data sizes are kept small through careful acquisition, and with parsimonious layout of latent layers, the framework can be both effective and computationally tractable. Our methods are illustrated on simulation data and two real computer experiments of varying input dimensionality. We provide an open source implementation in the "deepgp" package on CRAN.
Locally induced Gaussian processes for large-scale simulation experiments
Aug 28, 2020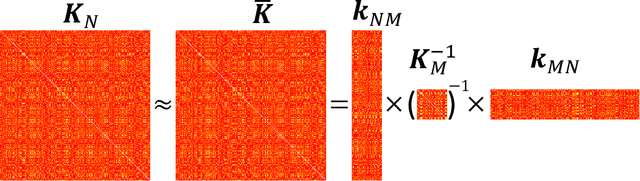
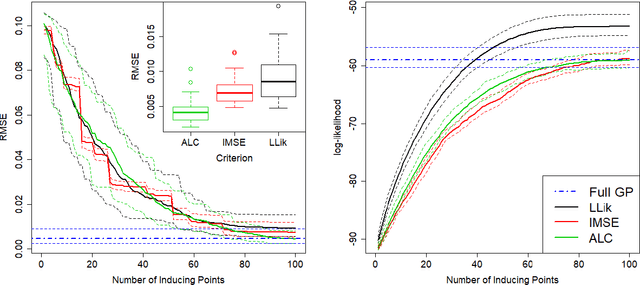
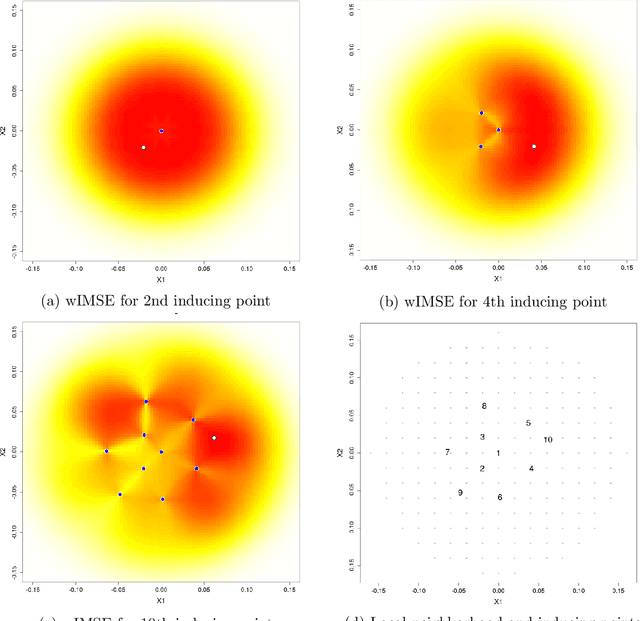
Gaussian processes (GPs) serve as flexible surrogates for complex surfaces, but buckle under the cubic cost of matrix decompositions with big training data sizes. Geospatial and machine learning communities suggest pseudo-inputs, or inducing points, as one strategy to obtain an approximation easing that computational burden. However, we show how placement of inducing points and their multitude can be thwarted by pathologies, especially in large-scale dynamic response surface modeling tasks. As remedy, we suggest porting the inducing point idea, which is usually applied globally, over to a more local context where selection is both easier and faster. In this way, our proposed methodology hybridizes global inducing point and data subset-based local GP approximation. A cascade of strategies for planning the selection of local inducing points is provided, and comparisons are drawn to related methodology with emphasis on computer surrogate modeling applications. We show that local inducing points extend their global and data-subset component parts on the accuracy--computational efficiency frontier. Illustrative examples are provided on benchmark data and a large-scale real-simulation satellite drag interpolation problem.
Bayesian optimization under mixed constraints with a slack-variable augmented Lagrangian
May 31, 2016
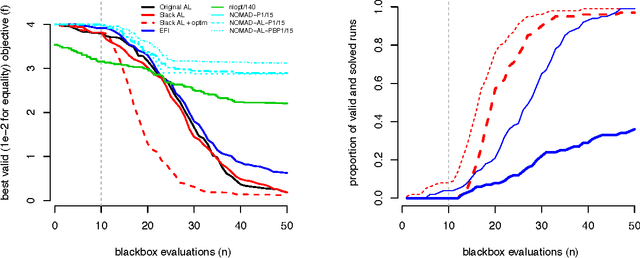
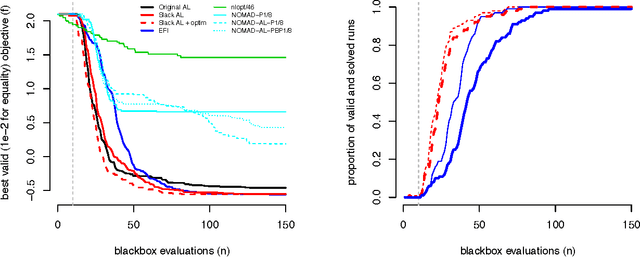
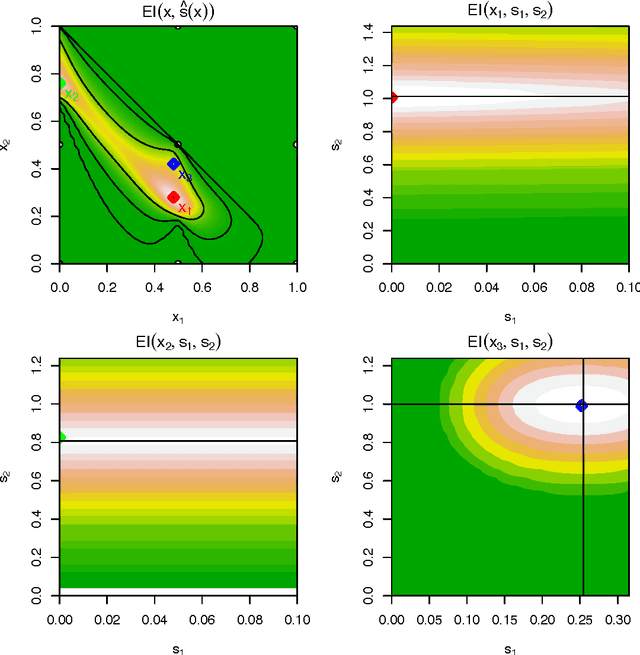
An augmented Lagrangian (AL) can convert a constrained optimization problem into a sequence of simpler (e.g., unconstrained) problems, which are then usually solved with local solvers. Recently, surrogate-based Bayesian optimization (BO) sub-solvers have been successfully deployed in the AL framework for a more global search in the presence of inequality constraints; however, a drawback was that expected improvement (EI) evaluations relied on Monte Carlo. Here we introduce an alternative slack variable AL, and show that in this formulation the EI may be evaluated with library routines. The slack variables furthermore facilitate equality as well as inequality constraints, and mixtures thereof. We show how our new slack "ALBO" compares favorably to the original. Its superiority over conventional alternatives is reinforced on several mixed constraint examples.