 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriangulation candidates for Bayesian optimization
Dec 14, 2021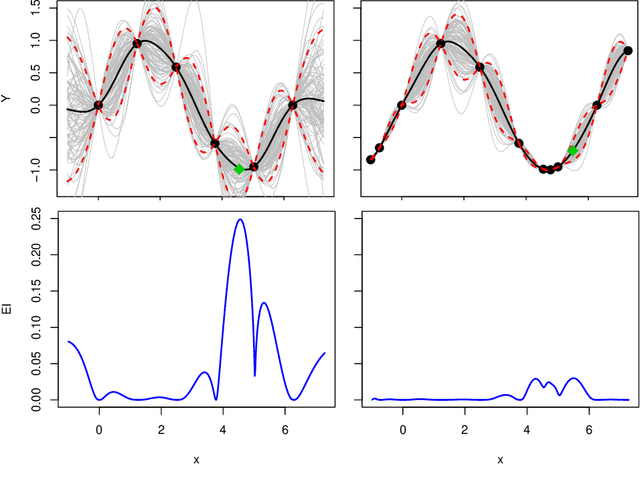
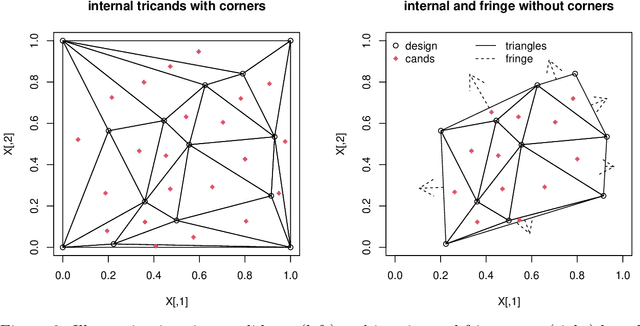
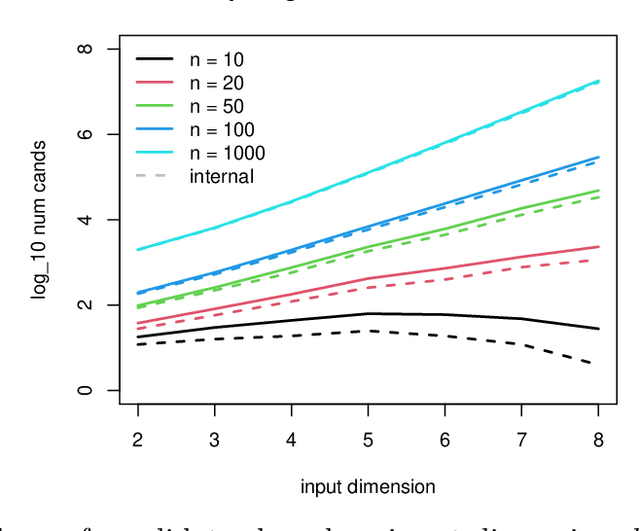

Bayesian optimization is a form of sequential design: idealize input-output relationships with a suitably flexible nonlinear regression model; fit to data from an initial experimental campaign; devise and optimize a criterion for selecting the next experimental condition(s) under the fitted model (e.g., via predictive equations) to target outcomes of interest (say minima); repeat after acquiring output under those conditions and updating the fit. In many situations this "inner optimization" over the new-data acquisition criterion is cumbersome because it is non-convex/highly multi-modal, may be non-differentiable, or may otherwise thwart numerical optimizers, especially when inference requires Monte Carlo. In such cases it is not uncommon to replace continuous search with a discrete one over random candidates. Here we propose using candidates based on a Delaunay triangulation of the existing input design. In addition to detailing construction of these "tricands", based on a simple wrapper around a conventional convex hull library, we promote several advantages based on properties of the geometric criterion involved. We then demonstrate empirically how tricands can lead to better Bayesian optimization performance compared to both numerically optimized acquisitions and random candidate-based alternatives on benchmark problems.
Active Learning for Deep Gaussian Process Surrogates
Dec 15, 2020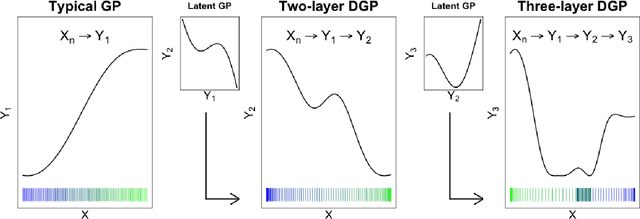
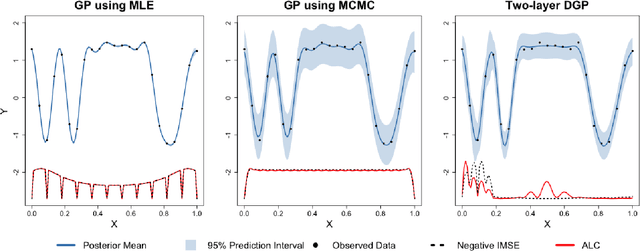
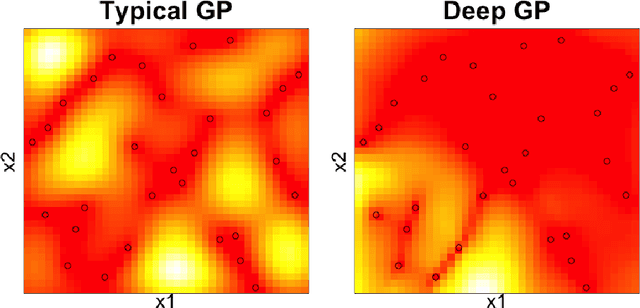
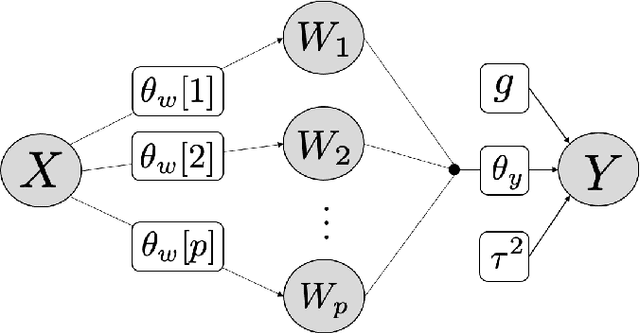
Deep Gaussian processes (DGPs) are increasingly popular as predictive models in machine learning (ML) for their non-stationary flexibility and ability to cope with abrupt regime changes in training data. Here we explore DGPs as surrogates for computer simulation experiments whose response surfaces exhibit similar characteristics. In particular, we transport a DGP's automatic warping of the input space and full uncertainty quantification (UQ), via a novel elliptical slice sampling (ESS) Bayesian posterior inferential scheme, through to active learning (AL) strategies that distribute runs non-uniformly in the input space -- something an ordinary (stationary) GP could not do. Building up the design sequentially in this way allows smaller training sets, limiting both expensive evaluation of the simulator code and mitigating cubic costs of DGP inference. When training data sizes are kept small through careful acquisition, and with parsimonious layout of latent layers, the framework can be both effective and computationally tractable. Our methods are illustrated on simulation data and two real computer experiments of varying input dimensionality. We provide an open source implementation in the "deepgp" package on CRAN.