 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeed for Objective Task-based Evaluation of Deep Learning-Based Denoising Methods: A Study in the Context of Myocardial Perfusion SPECT
Mar 16, 2023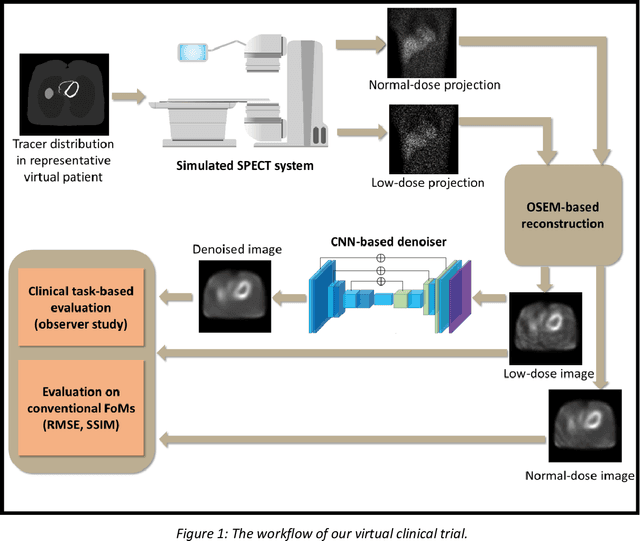
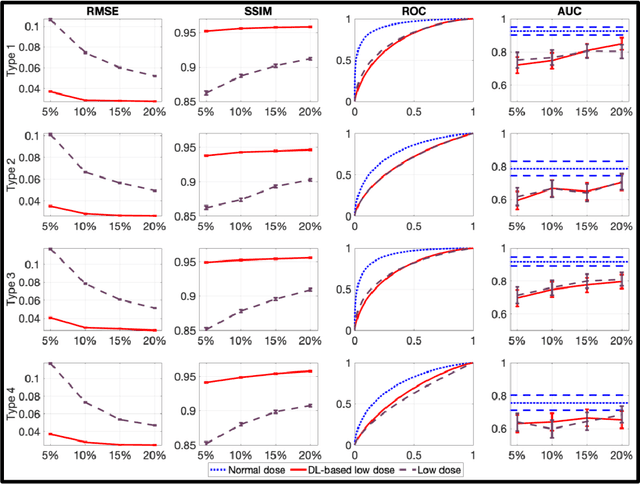
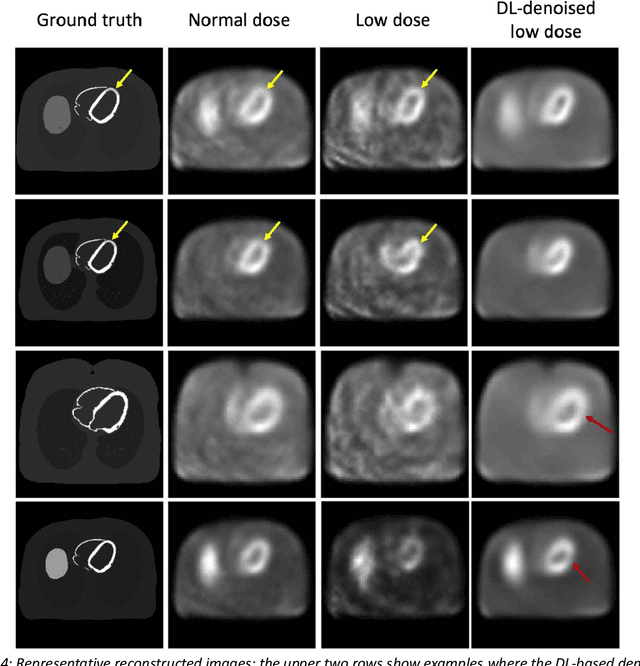
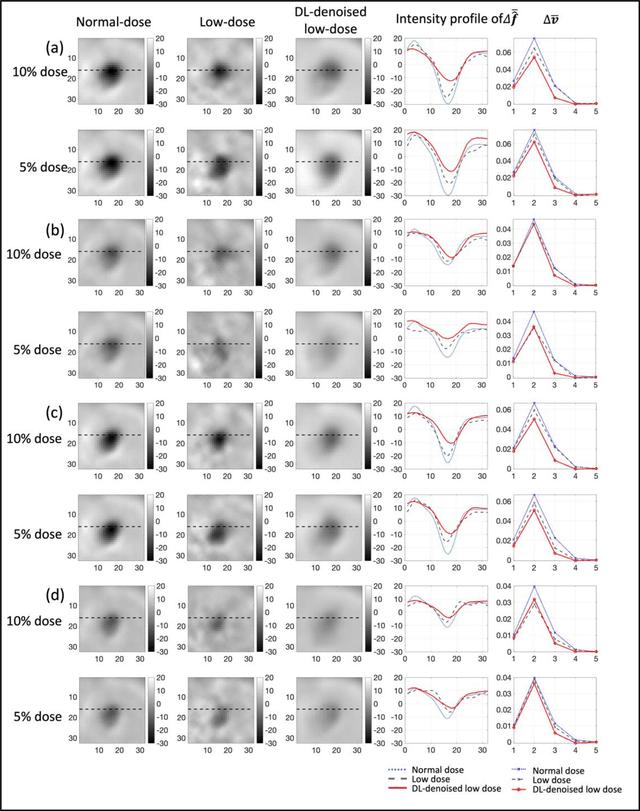
Artificial intelligence-based methods have generated substantial interest in nuclear medicine. An area of significant interest has been using deep-learning (DL)-based approaches for denoising images acquired with lower doses, shorter acquisition times, or both. Objective evaluation of these approaches is essential for clinical application. DL-based approaches for denoising nuclear-medicine images have typically been evaluated using fidelity-based figures of merit (FoMs) such as RMSE and SSIM. However, these images are acquired for clinical tasks and thus should be evaluated based on their performance in these tasks. Our objectives were to (1) investigate whether evaluation with these FoMs is consistent with objective clinical-task-based evaluation; (2) provide a theoretical analysis for determining the impact of denoising on signal-detection tasks; (3) demonstrate the utility of virtual clinical trials (VCTs) to evaluate DL-based methods. A VCT to evaluate a DL-based method for denoising myocardial perfusion SPECT (MPS) images was conducted. The impact of DL-based denoising was evaluated using fidelity-based FoMs and AUC, which quantified performance on detecting perfusion defects in MPS images as obtained using a model observer with anthropomorphic channels. Based on fidelity-based FoMs, denoising using the considered DL-based method led to significantly superior performance. However, based on ROC analysis, denoising did not improve, and in fact, often degraded detection-task performance. The results motivate the need for objective task-based evaluation of DL-based denoising approaches. Further, this study shows how VCTs provide a mechanism to conduct such evaluations using VCTs. Finally, our theoretical treatment reveals insights into the reasons for the limited performance of the denoising approach.
Issues and Challenges in Applications of Artificial Intelligence to Nuclear Medicine -- The Bethesda Report (AI Summit 2022)
Nov 07, 2022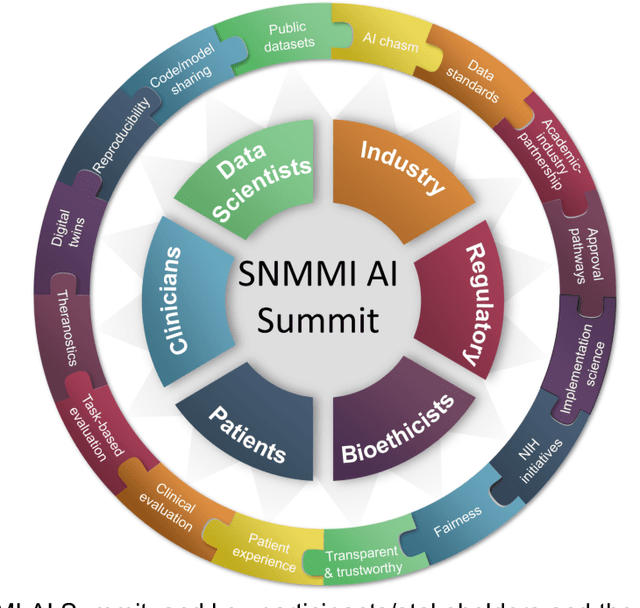
The SNMMI Artificial Intelligence (SNMMI-AI) Summit, organized by the SNMMI AI Task Force, took place in Bethesda, MD on March 21-22, 2022. It brought together various community members and stakeholders from academia, healthcare, industry, patient representatives, and government (NIH, FDA), and considered various key themes to envision and facilitate a bright future for routine, trustworthy use of AI in nuclear medicine. In what follows, essential issues, challenges, controversies and findings emphasized in the meeting are summarized.
A deep learning algorithm for reducing false positives in screening mammography
Apr 13, 2022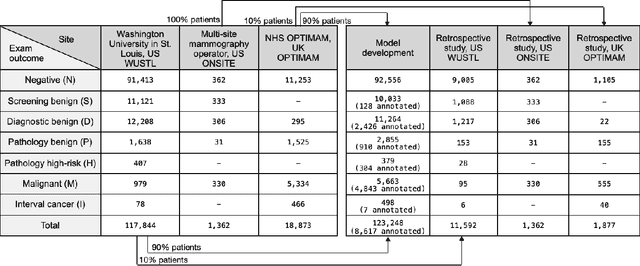
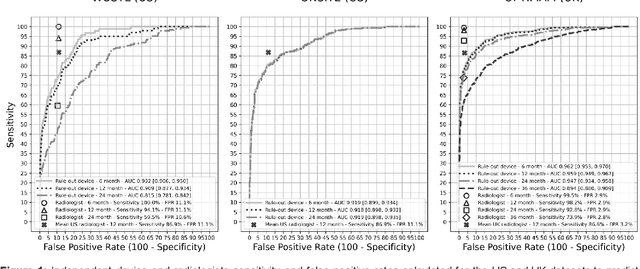
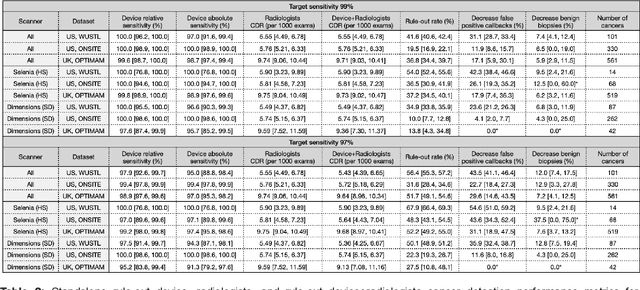
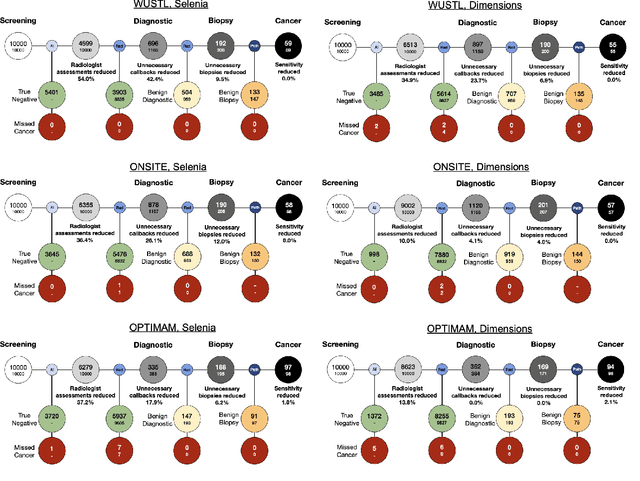
Screening mammography improves breast cancer outcomes by enabling early detection and treatment. However, false positive callbacks for additional imaging from screening exams cause unnecessary procedures, patient anxiety, and financial burden. This work demonstrates an AI algorithm that reduces false positives by identifying mammograms not suspicious for breast cancer. We trained the algorithm to determine the absence of cancer using 123,248 2D digital mammograms (6,161 cancers) and performed a retrospective study on 14,831 screening exams (1,026 cancers) from 15 US and 3 UK sites. Retrospective evaluation of the algorithm on the largest of the US sites (11,592 mammograms, 101 cancers) a) left the cancer detection rate unaffected (p=0.02, non-inferiority margin 0.25 cancers per 1000 exams), b) reduced callbacks for diagnostic exams by 31.1% compared to standard clinical readings, c) reduced benign needle biopsies by 7.4%, and d) reduced screening exams requiring radiologist interpretation by 41.6% in the simulated clinical workflow. This work lays the foundation for semi-autonomous breast cancer screening systems that could benefit patients and healthcare systems by reducing false positives, unnecessary procedures, patient anxiety, and expenses.
A multi-site study of a breast density deep learning model for full-field digital mammography and digital breast tomosynthesis exams
Jan 23, 2020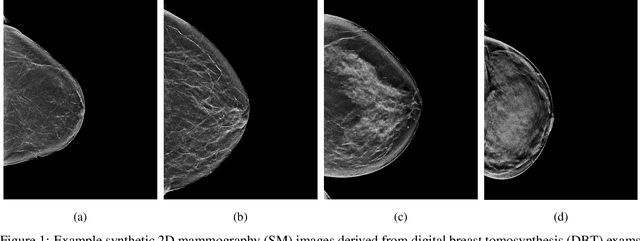
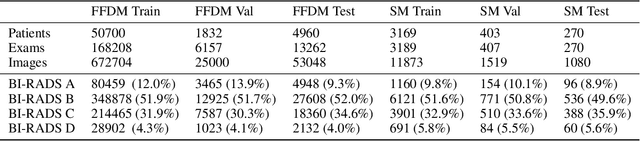
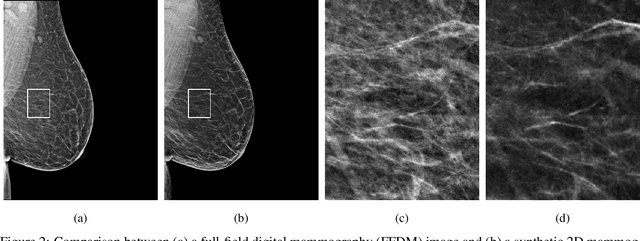
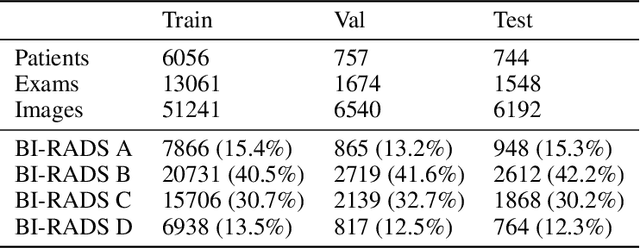
$\textbf{Purpose:}$ To develop a Breast Imaging Reporting and Data System (BI-RADS) breast density DL model in a multi-site setting for synthetic 2D mammography (SM) images derived from 3D DBT exams using FFDM images and limited SM data. $\textbf{Materials and Methods:}$ A DL model was trained to predict BI-RADS breast density using FFDM images acquired from 2008 to 2017 (Site 1: 57492 patients, 187627 exams, 750752 images) for this retrospective study. The FFDM model was evaluated using SM datasets from two institutions (Site 1: 3842 patients, 3866 exams, 14472 images, acquired from 2016 to 2017; Site 2: 7557 patients, 16283 exams, 63973 images, 2015 to 2019). Adaptation methods were investigated to improve performance on the SM datasets and the effect of dataset size on each adaptation method is considered. Statistical significance was assessed using confidence intervals (CI), estimated by bootstrapping. $\textbf{Results:}$ Without adaptation, the model demonstrated close agreement with the original reporting radiologists for all three datasets (Site 1 FFDM: linearly-weighted $\kappa_w$ = 0.75, 95\% CI: [0.74, 0.76]; Site 1 SM: $\kappa_w$ = 0.71, CI: [0.64, 0.78]; Site 2 SM: $\kappa_w$ = 0.72, CI: [0.70, 0.75]). With adaptation, performance improved for Site 2 (Site 1: $\kappa_w$ = 0.72, CI: [0.66, 0.79], Site 2: $\kappa_w$ = 0.79, CI: [0.76, 0.81]) using only 500 SM images from each site. $\textbf{Conclusion:}$ A BI-RADS breast density DL model demonstrated strong performance on FFDM and SM images from two institutions without training on SM images and improved using few SM images.