 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conceptual Framework for AI-based Decision Systems in Critical Infrastructures
Apr 21, 2025



The interaction between humans and AI in safety-critical systems presents a unique set of challenges that remain partially addressed by existing frameworks. These challenges stem from the complex interplay of requirements for transparency, trust, and explainability, coupled with the necessity for robust and safe decision-making. A framework that holistically integrates human and AI capabilities while addressing these concerns is notably required, bridging the critical gaps in designing, deploying, and maintaining safe and effective systems. This paper proposes a holistic conceptual framework for critical infrastructures by adopting an interdisciplinary approach. It integrates traditionally distinct fields such as mathematics, decision theory, computer science, philosophy, psychology, and cognitive engineering and draws on specialized engineering domains, particularly energy, mobility, and aeronautics. The flexibility in its adoption is also demonstrated through its instantiation on an already existing framework.
EEG-Based Brain-Computer Interfaces Are Vulnerable to Backdoor Attacks
Oct 30, 2020
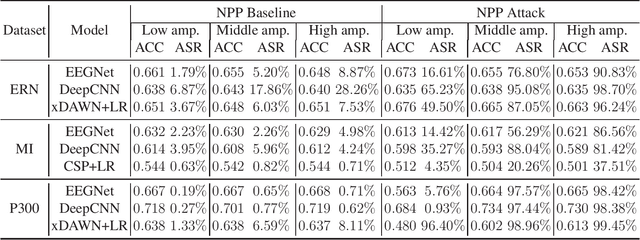
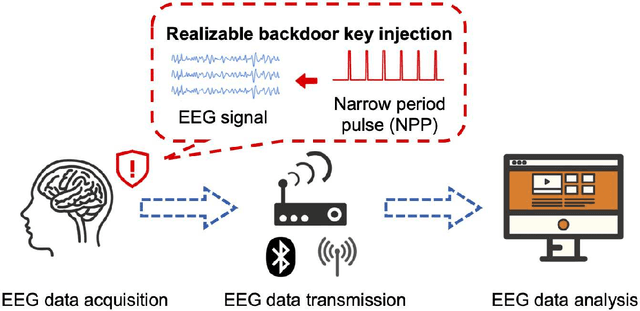
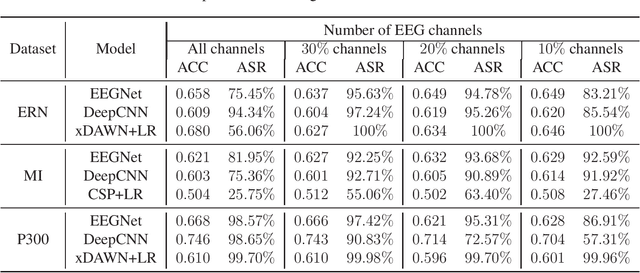
Research and development of electroencephalogram (EEG) based brain-computer interfaces (BCIs) have advanced rapidly, partly due to the wide adoption of sophisticated machine learning approaches for decoding the EEG signals. However, recent studies have shown that machine learning algorithms are vulnerable to adversarial attacks, e.g., the attacker can add tiny adversarial perturbations to a test sample to fool the model, or poison the training data to insert a secret backdoor. Previous research has shown that adversarial attacks are also possible for EEG-based BCIs. However, only adversarial perturbations have been considered, and the approaches are theoretically sound but very difficult to implement in practice. This article proposes to use narrow period pulse for poisoning attack of EEG-based BCIs, which is more feasible in practice and has never been considered before. One can create dangerous backdoors in the machine learning model by injecting poisoning samples into the training set. Test samples with the backdoor key will then be classified into the target class specified by the attacker. What most distinguishes our approach from previous ones is that the backdoor key does not need to be synchronized with the EEG trials, making it very easy to implement. The effectiveness and robustness of the backdoor attack approach is demonstrated, highlighting a critical security concern for EEG-based BCIs.
Tiny Noise Can Make an EEG-Based Brain-Computer Interface Speller Output Anything
Mar 04, 2020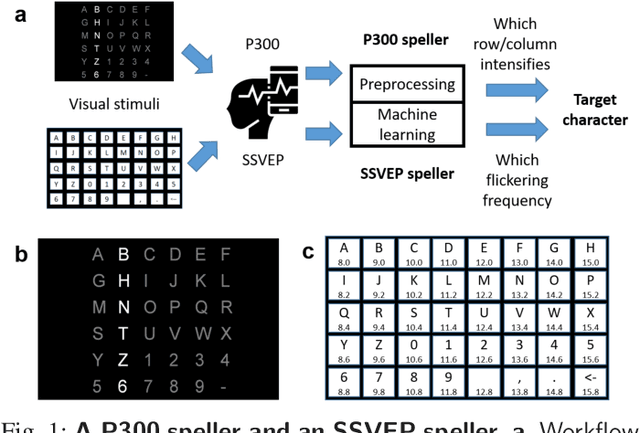
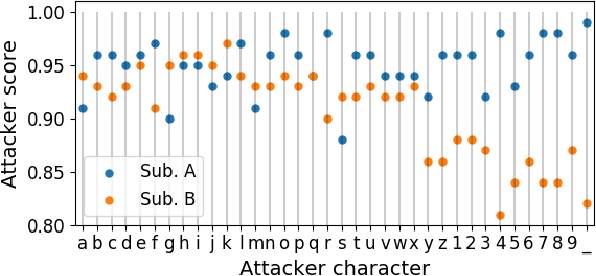
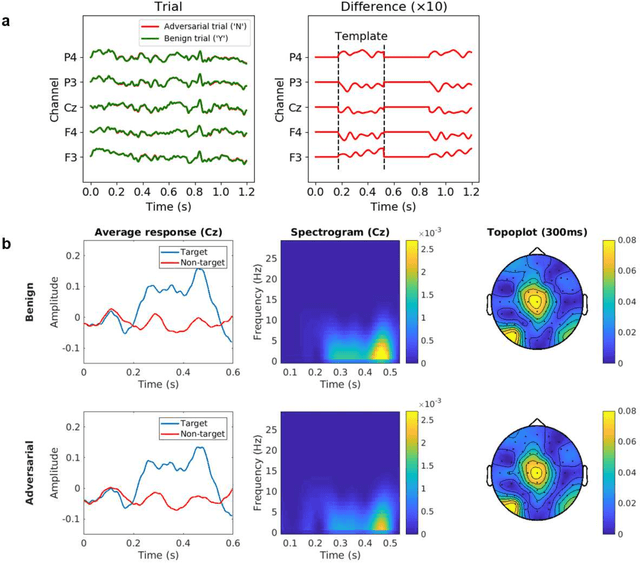
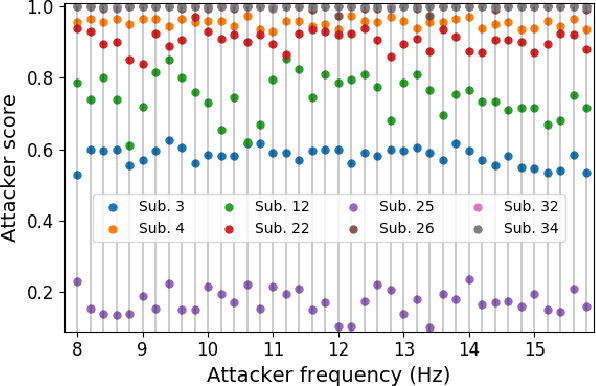
An electroencephalogram (EEG) based brain-computer interface (BCI) speller allows a user to input text to a computer by thought. It is particularly useful to severely disabled individuals, e.g., amyotrophic lateral sclerosis patients, who have no other effective means of communication with another person or a computer. Most studies so far focused on making EEG-based BCI spellers faster and more reliable; however, few have considered their security. Here we show that P300 and steady-state visual evoked potential BCI spellers are very vulnerable, i.e., they can be severely attacked by adversarial perturbations, which are too tiny to be noticed when added to EEG signals, but can mislead the spellers to spell anything the attacker wants. The consequence could range from merely user frustration to severe misdiagnosis in clinical applications. We hope our research can attract more attention to the security of EEG-based BCI spellers, and more broadly, EEG-based BCIs, which has received little attention before.
Applying Transfer Learning To Deep Learned Models For EEG Analysis
Jul 02, 2019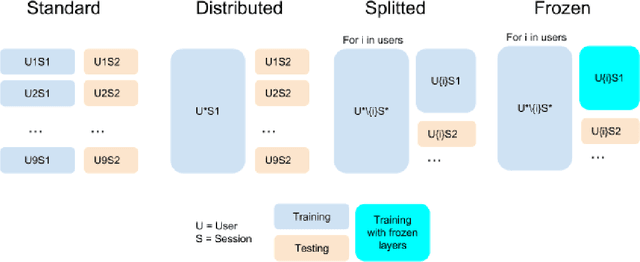
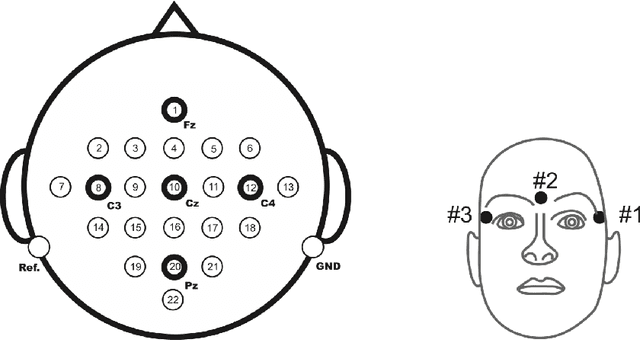
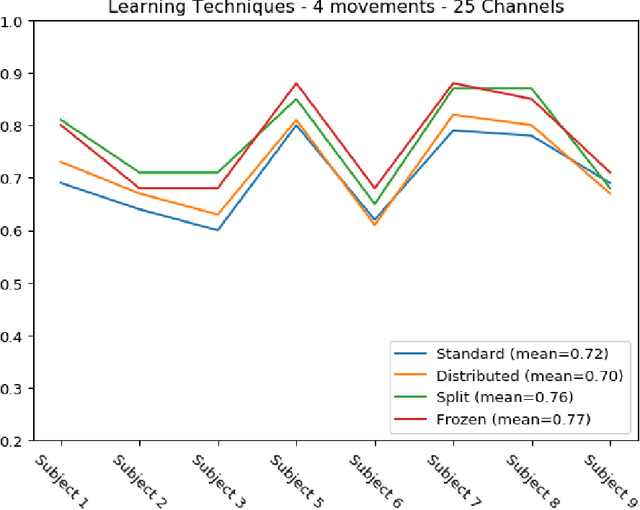
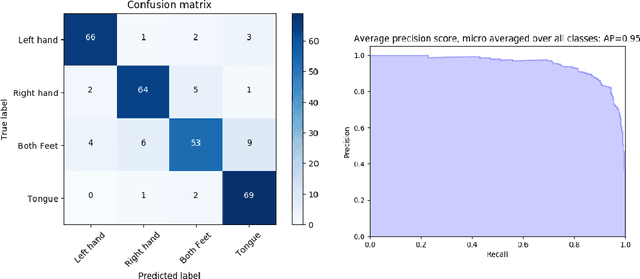
The introduction of deep learning and transfer learning techniques in fields such as computer vision allowed a leap forward in the accuracy of image classification tasks. Currently there is only limited use of such techniques in neuroscience. The challenge of using deep learning methods to successfully train models in neuroscience, lies in the complexity of the information that is processed, the availability of data and the cost of producing sufficient high quality annotations. Inspired by its application in computer vision, we introduce transfer learning on electrophysiological data to enable training a model with limited amounts of data. Our method was tested on the dataset of the BCI competition IV 2a and compared to the top results that were obtained using traditional machine learning techniques. Using our DL model we outperform the top result of the competition by 33%. We also explore transferability of knowledge between trained models over different experiments, called inter-experimental transfer learning. This reduces the amount of required data even further and is especially useful when few subjects are available. This method is able to outperform the standard deep learning methods used in the BCI competition IV 2b approaches by 18%. In this project we propose a method that can produce reliable electroencephalography (EEG) signal classification, based on modest amounts of training data through the use of transfer learning.
Context-aware learning for finite mixture models
Jul 29, 2015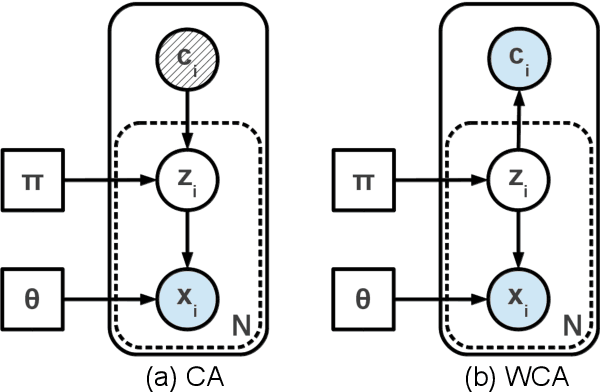
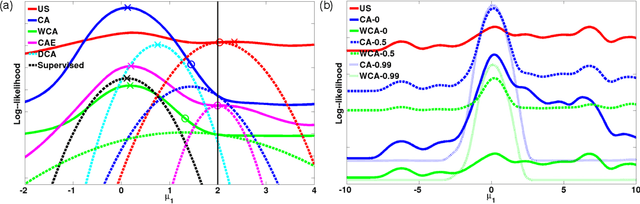

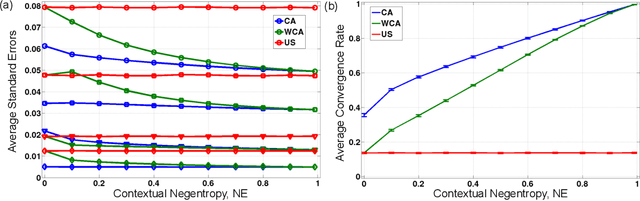
This work introduces algorithms able to exploit contextual information in order to improve maximum-likelihood (ML) parameter estimation in finite mixture models (FMM), demonstrating their benefits and properties in several scenarios. The proposed algorithms are derived in a probabilistic framework with regard to situations where the regular FMM graphs can be extended with context-related variables, respecting the standard expectation-maximization (EM) methodology and, thus, rendering explicit supervision completely redundant. We show that, by direct application of the missing information principle, the compared algorithms' learning behaviour operates between the extremities of supervised and unsupervised learning, proportionally to the information content of contextual assistance. Our simulation results demonstrate the superiority of context-aware FMM training as compared to conventional unsupervised training in terms of estimation precision, standard errors, convergence rates and classification accuracy or regression fitness in various scenarios, while also highlighting important differences among the outlined situations. Finally, the improved classification outcome of contextually enhanced FMMs is showcased in a brain-computer interface application scenario.