 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware learning for finite mixture models
Paper and Code
Jul 29, 2015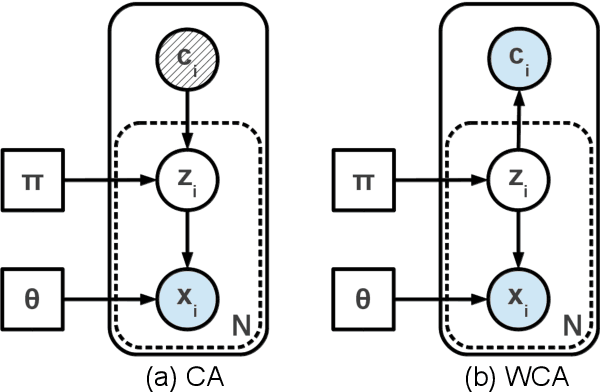
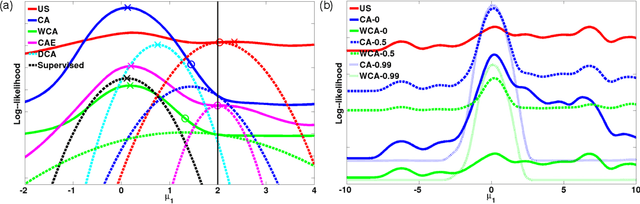

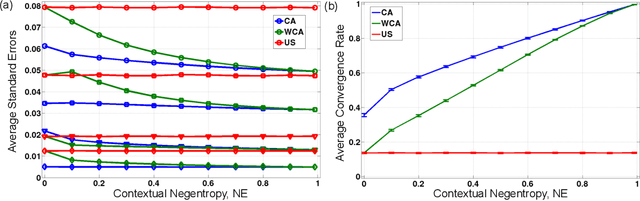
This work introduces algorithms able to exploit contextual information in order to improve maximum-likelihood (ML) parameter estimation in finite mixture models (FMM), demonstrating their benefits and properties in several scenarios. The proposed algorithms are derived in a probabilistic framework with regard to situations where the regular FMM graphs can be extended with context-related variables, respecting the standard expectation-maximization (EM) methodology and, thus, rendering explicit supervision completely redundant. We show that, by direct application of the missing information principle, the compared algorithms' learning behaviour operates between the extremities of supervised and unsupervised learning, proportionally to the information content of contextual assistance. Our simulation results demonstrate the superiority of context-aware FMM training as compared to conventional unsupervised training in terms of estimation precision, standard errors, convergence rates and classification accuracy or regression fitness in various scenarios, while also highlighting important differences among the outlined situations. Finally, the improved classification outcome of contextually enhanced FMMs is showcased in a brain-computer interface application scenario.