 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the onset and offset of motor imagery during passive arm movements induced by an upper-body exoskeleton
Mar 21, 2026Two distinct technologies have gained attention lately due to their prospects for motor rehabilitation: robotics and brain-machine interfaces (BMIs). Harnessing their combined efforts is a largely uncharted and promising direction that has immense clinical potential. However, a significant challenge is whether motor intentions from the user can be accurately detected using non-invasive BMIs in the presence of instrumental noise and passive movements induced by the rehabilitation exoskeleton. As an alternative to the straightforward continuous control approach, this study instead aims to characterize the onset and offset of motor imagery during passive arm movements induced by an upper-body exoskeleton to allow for the natural control (initiation and termination) of functional movements. Ten participants were recruited to perform kinesthetic motor imagery (MI) of the right arm while attached to the robot, simultaneously cued with LEDs indicating the initiation and termination of a goal-oriented reaching task. Using electroencephalogram signals, we built a decoder to detect the transition between i) rest and beginning MI and ii) maintaining and ending MI. Offline decoder evaluation achieved group average onset accuracy of 60.7% and 66.6% for offset accuracy, revealing that the start and stop of MI could be identified while attached to the robot. Furthermore, pseudo-online evaluation could replicate this performance, forecasting reliable online exoskeleton control in the future. Our approach showed that participants could produce quality and reliable sensorimotor rhythms regardless of noise or passive arm movements induced by wearing the exoskeleton, which opens new possibilities for BMI control of assistive devices.
* Accepted to IROS 2023. 6 pages, 6 figures. Project page available at https://mitrakanishka.github.io/projects/passive-arm-mi/
Real-Time Decoding of Movement Onset and Offset for Brain-Controlled Rehabilitation Exoskeleton
Mar 17, 2026Robot-assisted therapy can deliver high-dose, task-specific training after neurologic injury, but most systems act primarily at the limb level-engaging the impaired neural circuits only indirectly-which remains a key barrier to truly contingent, neuroplasticity-targeted rehabilitation. We address this gap by implementing online, dual-state motor imagery control of an upper-limb exoskeleton, enabling goal-directed reaches to be both initiated and terminated directly from non-invasive EEG. Eight participants used EEG to initiate assistance and then volitionally halt the robot mid-trajectory. Across two online sessions, group-mean hit rates were 61.5% for onset and 64.5% for offset, demonstrating reliable start-stop command delivery despite instrumental noise and passive arm motion. Methodologically, we reveal a systematic, class-driven bias induced by common task-based recentering using an asymmetric margin diagnostic, and we introduce a class-agnostic fixation-based recentering method that tracks drift without sampling command classes while preserving class geometry. This substantially improves threshold-free separability (AUC gains: onset +56%, p = 0.0117; offset +34%, p = 0.0251) and reduces bias within and across days. Together, these results help bridge offline decoding and practical, intention-driven start-stop control of a rehabilitation exoskeleton, enabling precisely timed, contingent assistance aligned with neuroplasticity goals while supporting future clinical translation.
Applying Transfer Learning To Deep Learned Models For EEG Analysis
Jul 02, 2019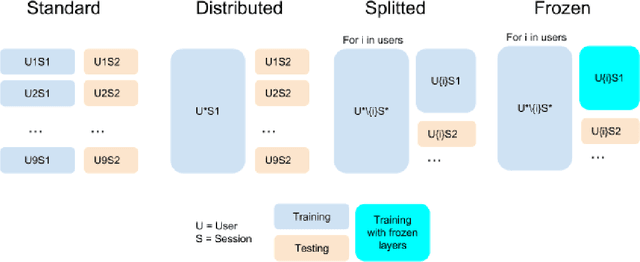
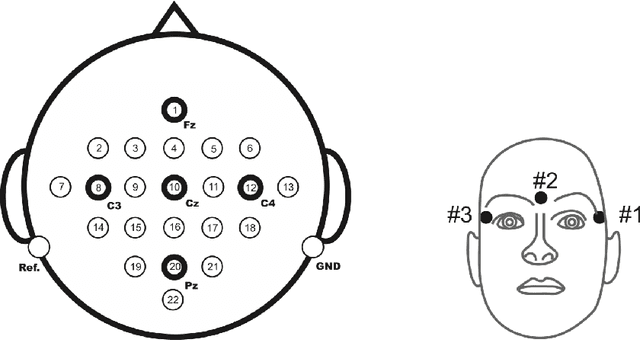
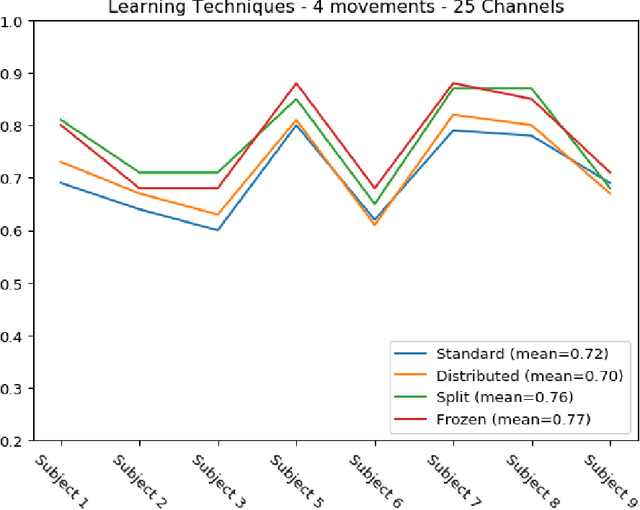
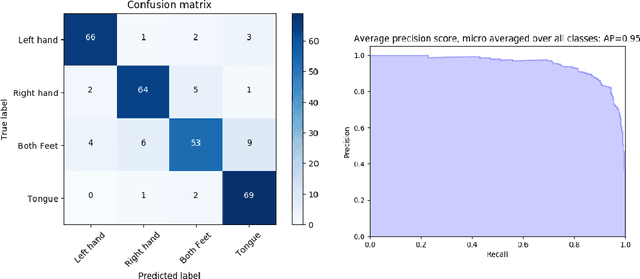
The introduction of deep learning and transfer learning techniques in fields such as computer vision allowed a leap forward in the accuracy of image classification tasks. Currently there is only limited use of such techniques in neuroscience. The challenge of using deep learning methods to successfully train models in neuroscience, lies in the complexity of the information that is processed, the availability of data and the cost of producing sufficient high quality annotations. Inspired by its application in computer vision, we introduce transfer learning on electrophysiological data to enable training a model with limited amounts of data. Our method was tested on the dataset of the BCI competition IV 2a and compared to the top results that were obtained using traditional machine learning techniques. Using our DL model we outperform the top result of the competition by 33%. We also explore transferability of knowledge between trained models over different experiments, called inter-experimental transfer learning. This reduces the amount of required data even further and is especially useful when few subjects are available. This method is able to outperform the standard deep learning methods used in the BCI competition IV 2b approaches by 18%. In this project we propose a method that can produce reliable electroencephalography (EEG) signal classification, based on modest amounts of training data through the use of transfer learning.
Exploring Embedding Methods in Binary Hyperdimensional Computing: A Case Study for Motor-Imagery based Brain-Computer Interfaces
Dec 30, 2018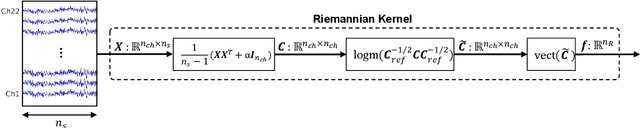
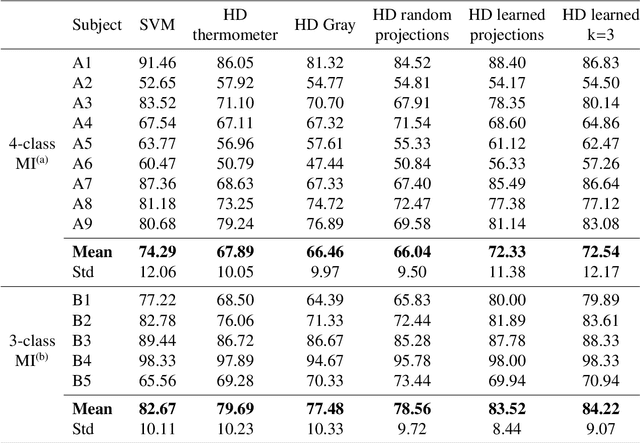
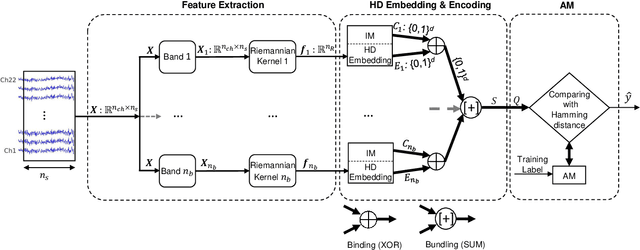
Key properties of brain-inspired hyperdimensional (HD) computing make it a prime candidate for energy-efficient and fast learning in biosignal processing. The main challenge is however to formulate embedding methods that map biosignal measures to a binary HD space. In this paper, we explore variety of such embedding methods and examine them with a challenging application of motor imagery brain-computer interface (MI-BCI) from electroencephalography (EEG) recordings. We explore embedding methods including random projections, quantization based thermometer and Gray coding, and learning HD representations using end-to-end training. All these methods, differing in complexity, aim to represent EEG signals in binary HD space, e.g. with 10,000 bits. This leads to development of a set of HD learning and classification methods that can be selectively chosen (or configured) based on accuracy and/or computational complexity requirements of a given task. We compare them with state-of-the-art linear support vector machine (SVM) on an NVIDIA TX2 board using the 4-class BCI competition IV-2a dataset as well as a new 3-class dataset. Compared to SVM, results on 3-class dataset show that simple thermometer embedding achieves moderate average accuracy (79.56% vs. 82.67%) with 26.8$\times$ faster training time and 22.3$\times$ lower energy; on the other hand, switching to end-to-end training with learned HD representations wipes out these training benefits while boosting the accuracy to 84.22% (1.55% higher than SVM). Similar trend is observed on the 4-class dataset where SVM achieves on average 74.29%: the thermometer embedding achieves 89.9$\times$ faster training time and 58.7$\times$ lower energy, but a lower accuracy (67.09%) than the learned representation of 72.54%.
Context-aware learning for finite mixture models
Jul 29, 2015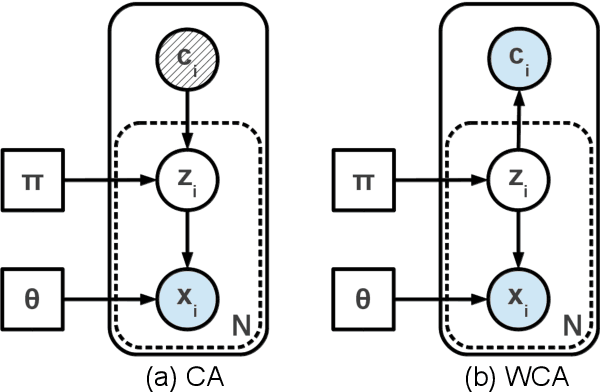
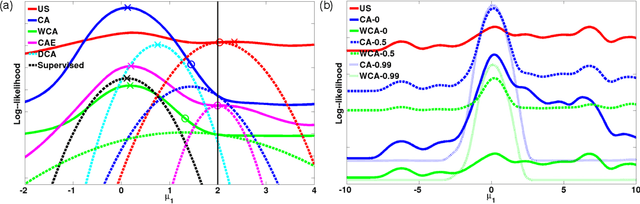

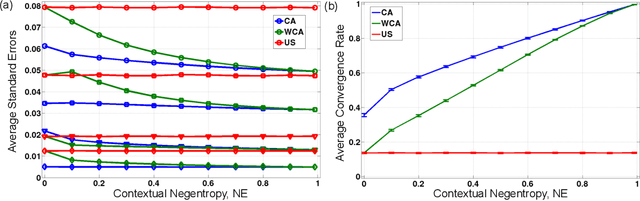
This work introduces algorithms able to exploit contextual information in order to improve maximum-likelihood (ML) parameter estimation in finite mixture models (FMM), demonstrating their benefits and properties in several scenarios. The proposed algorithms are derived in a probabilistic framework with regard to situations where the regular FMM graphs can be extended with context-related variables, respecting the standard expectation-maximization (EM) methodology and, thus, rendering explicit supervision completely redundant. We show that, by direct application of the missing information principle, the compared algorithms' learning behaviour operates between the extremities of supervised and unsupervised learning, proportionally to the information content of contextual assistance. Our simulation results demonstrate the superiority of context-aware FMM training as compared to conventional unsupervised training in terms of estimation precision, standard errors, convergence rates and classification accuracy or regression fitness in various scenarios, while also highlighting important differences among the outlined situations. Finally, the improved classification outcome of contextually enhanced FMMs is showcased in a brain-computer interface application scenario.