 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Prompting in Pre-trained Language Model for Natural Language Understanding
Oct 16, 2022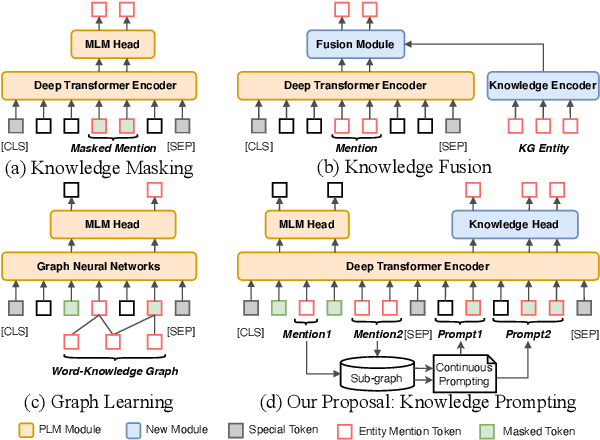
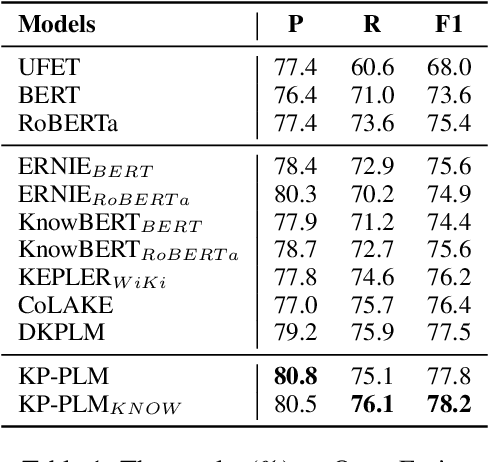
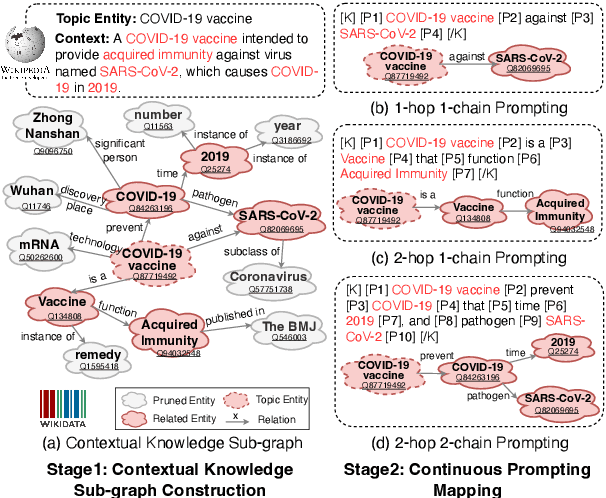
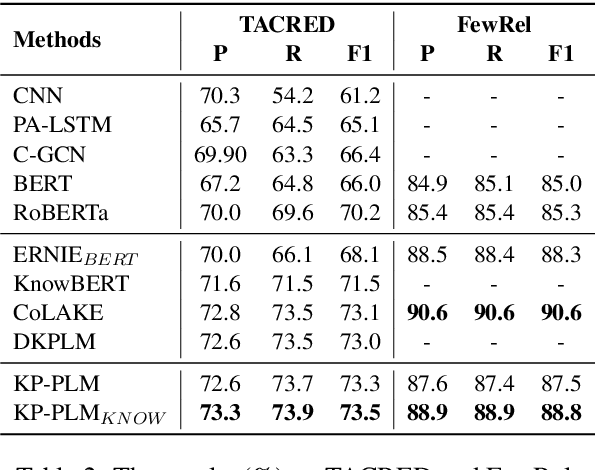
Knowledge-enhanced Pre-trained Language Model (PLM) has recently received significant attention, which aims to incorporate factual knowledge into PLMs. However, most existing methods modify the internal structures of fixed types of PLMs by stacking complicated modules, and introduce redundant and irrelevant factual knowledge from knowledge bases (KBs). In this paper, to address these problems, we introduce a seminal knowledge prompting paradigm and further propose a knowledge-prompting-based PLM framework KP-PLM. This framework can be flexibly combined with existing mainstream PLMs. Specifically, we first construct a knowledge sub-graph from KBs for each context. Then we design multiple continuous prompts rules and transform the knowledge sub-graph into natural language prompts. To further leverage the factual knowledge from these prompts, we propose two novel knowledge-aware self-supervised tasks including prompt relevance inspection and masked prompt modeling. Extensive experiments on multiple natural language understanding (NLU) tasks show the superiority of KP-PLM over other state-of-the-art methods in both full-resource and low-resource settings.
Towards Unified Prompt Tuning for Few-shot Text Classification
May 11, 2022
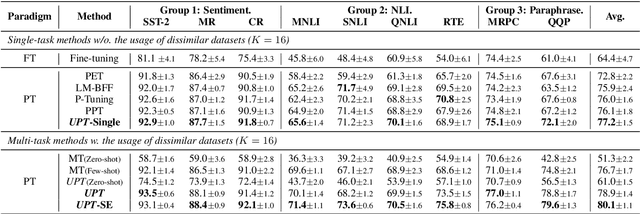
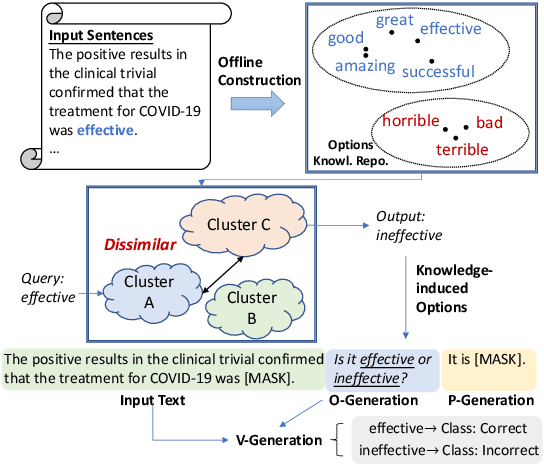
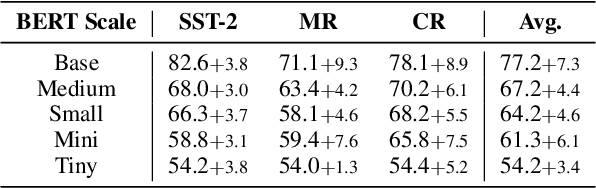
Prompt-based fine-tuning has boosted the performance of Pre-trained Language Models (PLMs) on few-shot text classification by employing task-specific prompts. Yet, PLMs are unfamiliar with prompt-style expressions during pre-training, which limits the few-shot learning performance on downstream tasks. It would be desirable if the models can acquire some prompting knowledge before adaptation to specific NLP tasks. We present the Unified Prompt Tuning (UPT) framework, leading to better few-shot text classification for BERT-style models by explicitly capturing prompting semantics from non-target NLP datasets. In UPT, a novel paradigm Prompt-Options-Verbalizer is proposed for joint prompt learning across different NLP tasks, forcing PLMs to capture task-invariant prompting knowledge. We further design a self-supervised task named Knowledge-enhanced Selective Masked Language Modeling to improve the PLM's generalization abilities for accurate adaptation to previously unseen tasks. After multi-task learning across multiple tasks, the PLM can be better prompt-tuned towards any dissimilar target tasks in low-resourced settings. Experiments over a variety of NLP tasks show that UPT consistently outperforms state-of-the-arts for prompt-based fine-tuning.
KECP: Knowledge Enhanced Contrastive Prompting for Few-shot Extractive Question Answering
May 06, 2022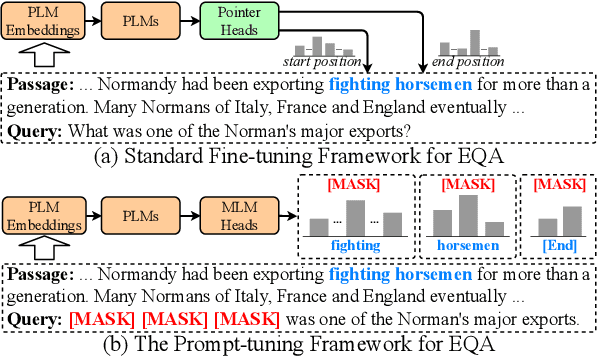
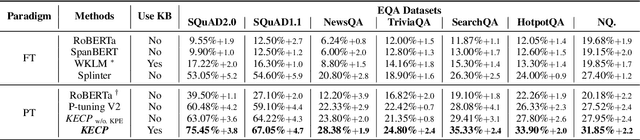
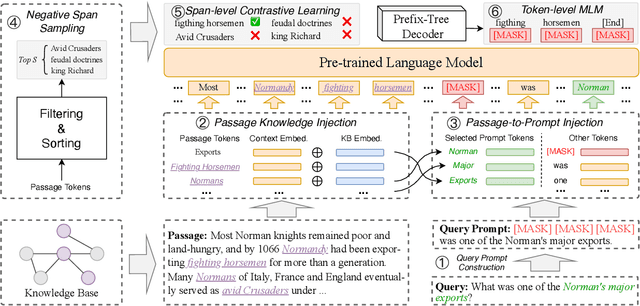
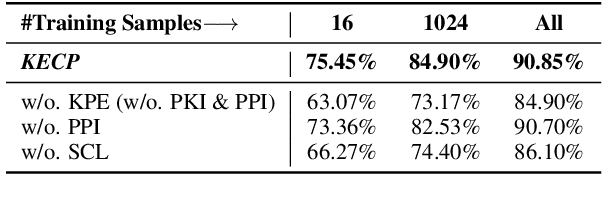
Extractive Question Answering (EQA) is one of the most important tasks in Machine Reading Comprehension (MRC), which can be solved by fine-tuning the span selecting heads of Pre-trained Language Models (PLMs). However, most existing approaches for MRC may perform poorly in the few-shot learning scenario. To solve this issue, we propose a novel framework named Knowledge Enhanced Contrastive Prompt-tuning (KECP). Instead of adding pointer heads to PLMs, we introduce a seminal paradigm for EQA that transform the task into a non-autoregressive Masked Language Modeling (MLM) generation problem. Simultaneously, rich semantics from the external knowledge base (KB) and the passage context are support for enhancing the representations of the query. In addition, to boost the performance of PLMs, we jointly train the model by the MLM and contrastive learning objectives. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches in few-shot settings by a large margin.
Emotion Analysis Platform on Chinese Microblog
Mar 28, 2014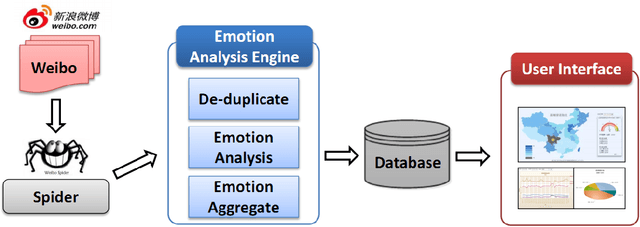
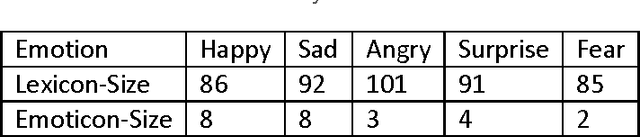
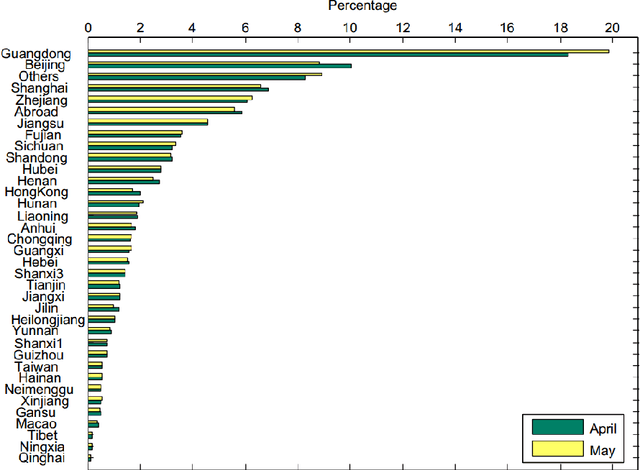

Weibo, as the largest social media service in China, has billions of messages generated every day. The huge number of messages contain rich sentimental information. In order to analyze the emotional changes in accordance with time and space, this paper presents an Emotion Analysis Platform (EAP), which explores the emotional distribution of each province, so that can monitor the global pulse of each province in China. The massive data of Weibo and the real-time requirements make the building of EAP challenging. In order to solve the above problems, emoticons, emotion lexicon and emotion-shifting rules are adopted in EAP to analyze the emotion of each tweet. In order to verify the effectiveness of the platform, case study on the Sichuan earthquake is done, and the analysis result of the platform accords with the fact. In order to analyze from quantity, we manually annotate a test set and conduct experiment on it. The experimental results show that the macro-Precision of EAP reaches 80% and the EAP works effectively.