 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximation of the Sliced-Wasserstein Distance Using Concentration of Random Projections
Jun 29, 2021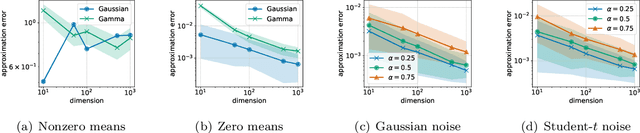
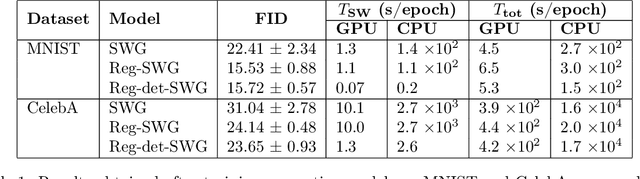
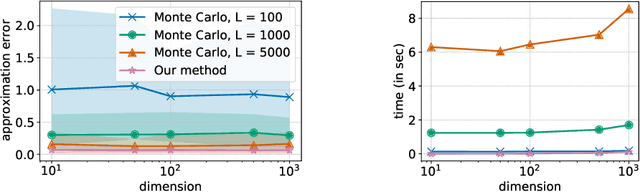

The Sliced-Wasserstein distance (SW) is being increasingly used in machine learning applications as an alternative to the Wasserstein distance and offers significant computational and statistical benefits. Since it is defined as an expectation over random projections, SW is commonly approximated by Monte Carlo. We adopt a new perspective to approximate SW by making use of the concentration of measure phenomenon: under mild assumptions, one-dimensional projections of a high-dimensional random vector are approximately Gaussian. Based on this observation, we develop a simple deterministic approximation for SW. Our method does not require sampling a number of random projections, and is therefore both accurate and easy to use compared to the usual Monte Carlo approximation. We derive nonasymptotical guarantees for our approach, and show that the approximation error goes to zero as the dimension increases, under a weak dependence condition on the data distribution. We validate our theoretical findings on synthetic datasets, and illustrate the proposed approximation on a generative modeling problem.
Schrödinger Bridge Samplers
Dec 31, 2019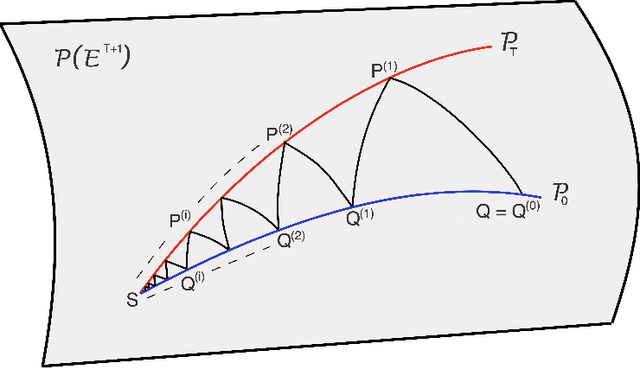
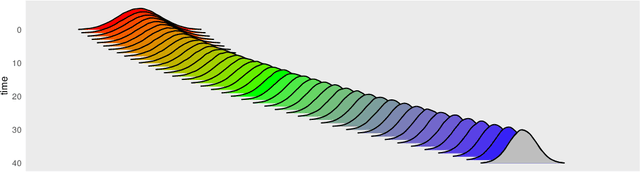
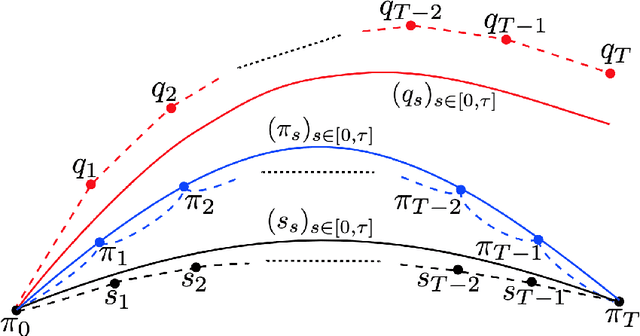
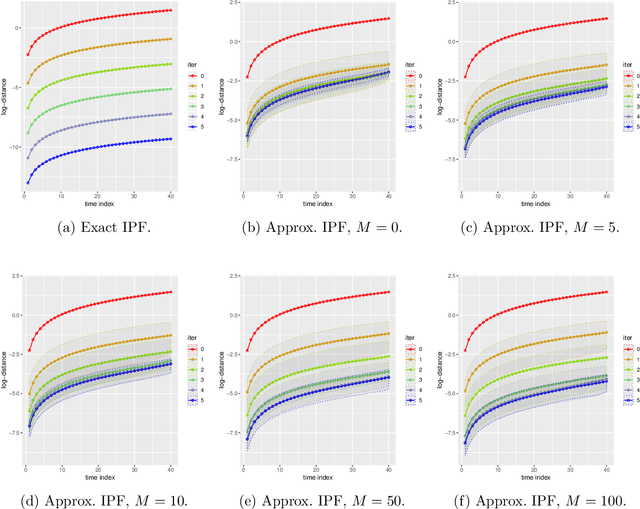
Consider a reference Markov process with initial distribution $\pi_{0}$ and transition kernels $\{M_{t}\}_{t\in[1:T]}$, for some $T\in\mathbb{N}$. Assume that you are given distribution $\pi_{T}$, which is not equal to the marginal distribution of the reference process at time $T$. In this scenario, Schr\"odinger addressed the problem of identifying the Markov process with initial distribution $\pi_{0}$ and terminal distribution equal to $\pi_{T}$ which is the closest to the reference process in terms of Kullback--Leibler divergence. This special case of the so-called Schr\"odinger bridge problem can be solved using iterative proportional fitting, also known as the Sinkhorn algorithm. We leverage these ideas to develop novel Monte Carlo schemes, termed Schr\"odinger bridge samplers, to approximate a target distribution $\pi$ on $\mathbb{R}^{d}$ and to estimate its normalizing constant. This is achieved by iteratively modifying the transition kernels of the reference Markov chain to obtain a process whose marginal distribution at time $T$ becomes closer to $\pi_T = \pi$, via regression-based approximations of the corresponding iterative proportional fitting recursion. We report preliminary experiments and make connections with other problems arising in the optimal transport, optimal control and physics literatures.
Unbiased Smoothing using Particle Independent Metropolis-Hastings
Feb 05, 2019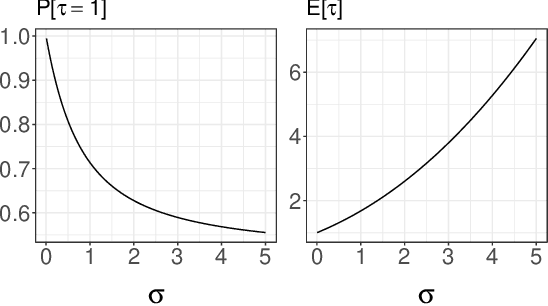
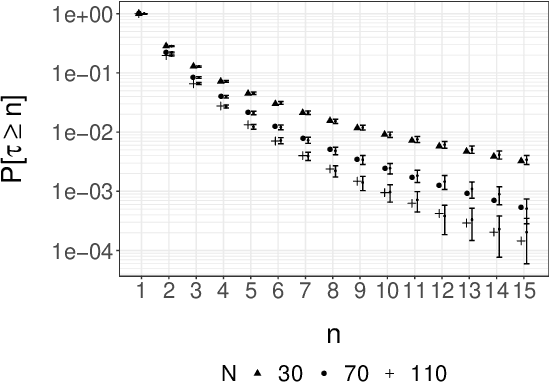
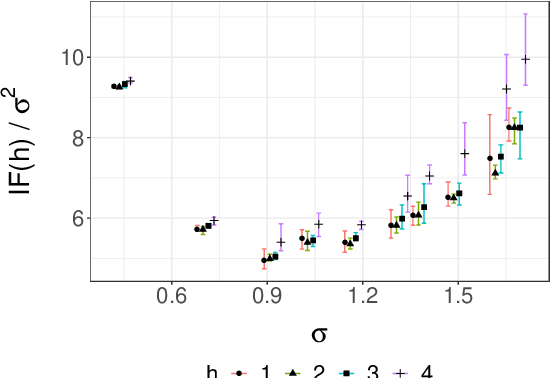
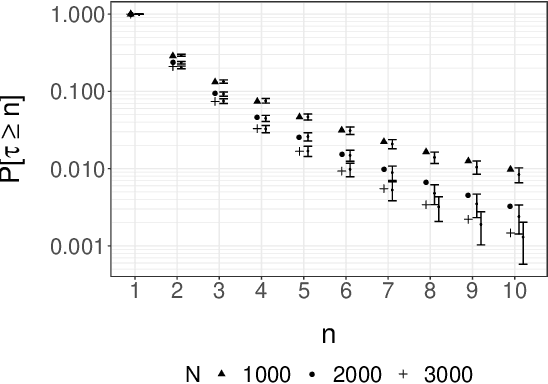
We consider the approximation of expectations with respect to the distribution of a latent Markov process given noisy measurements. This is known as the smoothing problem and is often approached with particle and Markov chain Monte Carlo (MCMC) methods. These methods provide consistent but biased estimators when run for a finite time. We propose a simple way of coupling two MCMC chains built using Particle Independent Metropolis-Hastings (PIMH) to produce unbiased smoothing estimators. Unbiased estimators are appealing in the context of parallel computing, and facilitate the construction of confidence intervals. The proposed scheme only requires access to off-the-shelf Particle Filters (PF) and is thus easier to implement than recently proposed unbiased smoothers. The approach is demonstrated on a L\'evy-driven stochastic volatility model and a stochastic kinetic model.
Clustering Time Series with Nonlinear Dynamics: A Bayesian Non-Parametric and Particle-Based Approach
Oct 24, 2018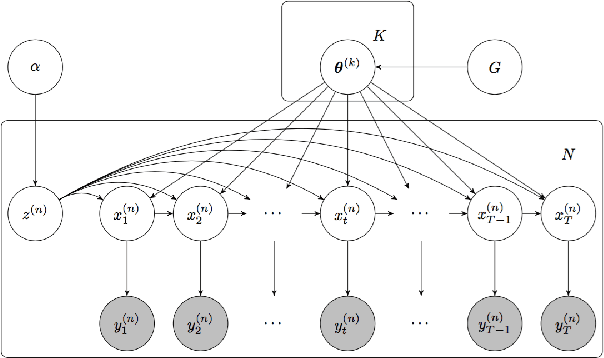



We propose a statistical framework for clustering multiple time series that exhibit nonlinear dynamics into an a-priori-unknown number of sub-groups that each comprise time series with similar dynamics. Our motivation comes from neuroscience where an important problem is to identify, within a large assembly of neurons, sub-groups that respond similarly to a stimulus or contingency. In the neural setting, conditioned on cluster membership and the parameters governing the dynamics, time series within a cluster are assumed independent and generated according to a nonlinear binomial state-space model. We derive a Metropolis-within-Gibbs algorithm for full Bayesian inference that alternates between sampling of cluster membership and sampling of parameters of interest. The Metropolis step is a PMMH iteration that requires an unbiased, low variance estimate of the likelihood function of a nonlinear state-space model. We leverage recent results on controlled sequential Monte Carlo to estimate likelihood functions more efficiently compared to the bootstrap particle filter. We apply the framework to time series acquired from the prefrontal cortex of mice in an experiment designed to characterize the neural underpinnings of fear.
Anytime Monte Carlo
Jun 07, 2017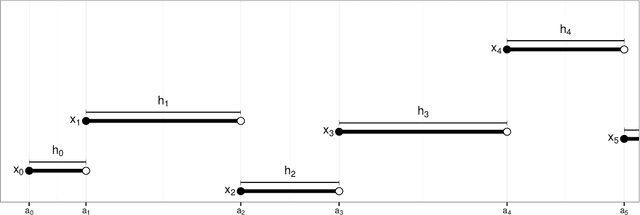
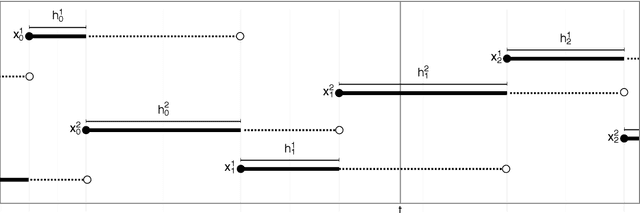
A Monte Carlo algorithm typically simulates some prescribed number of samples, taking some random real time to complete the computations necessary. This work considers the converse: to impose a real-time budget on the computation, so that the number of samples simulated is random. To complicate matters, the real time taken for each simulation may depend on the sample produced, so that the samples themselves are not independent of their number, and a length bias with respect to compute time is apparent. This is especially problematic when a Markov chain Monte Carlo (MCMC) algorithm is used and the final state of the Markov chain---rather than an average over all states---is required. The length bias does not diminish with the compute budget in this case. It occurs, for example, in sequential Monte Carlo (SMC) algorithms. We propose an anytime framework to address the concern, using a continuous-time Markov jump process to study the progress of the computation in real time. We show that the length bias can be eliminated for any MCMC algorithm by using a multiple chain construction. The utility of this construction is demonstrated on a large-scale SMC-squared implementation, using four billion particles distributed across a cluster of 128 graphics processing units on the Amazon EC2 service. The anytime framework imposes a real-time budget on the MCMC move steps within SMC-squared, ensuring that all processors are simultaneously ready for the resampling step, demonstrably reducing wait times and providing substantial control over the total compute budget.