 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Linking Real Scenes with Synthetic Data Generation for AI-based Cognitive Robotics and Computer Vision Applications
Jun 18, 2026AI vision models are a driving factor for the potential use case scenarios of cognitive robotics within in the industry and household applications. A large array of methods from semantic environment analysis towards 6D and grasping pose estimation have been proposed based on the latest AI achievements. However, such advancements require further strong and efficient methods w.r.t. training data and AI-architectures, which are capable in synergy to tackle current challenges, precision limits, and scalability beyond domain gaps. In this paper, we discuss these current limits and trends in the related state-of-the-art which are challenging those. Further we discuss our current work in progress on bridging the domain gap between simulations and real world applications by linking those in the training data generation.
Visual Quality Score Assessment of Large White Goods in Remanufacture with Multi-View Deformable-DETR
Jun 12, 2026Remanufacturing large white goods is essential for a circular economy, yet visual quality assessment remains a manual bottleneck for training and pricing. Conventional detection methods require extensive annotation and struggle with small defects in high-resolution multi-view data. We present a multi-view framework based on Deformable-DETR for automated quality scoring that aggregates information across redundant views to extract fine-grained features. To enhance robustness with limited labels, we employ self-supervised pretraining followed by supervised fine-tuning on expert-annotated scores. Additionally, a linear projection over frozen feature maps identifies regions of interest to explain model decisions. Evaluated on an industrial multi-view dataset, our approach delivers precise quality assessments while reducing reliance on manual annotation and per-part customization, enabling scalable and transparent inspection for remanufacturing lines.
A Qualitative Review of GenAI-Based Methods for Data Generation and Augmentation in Industrial Computer Vision Applications
Jun 12, 2026AI-driven computer vision applications require a profound database to ensure predictable behaviors and performance. Such predictable behaviors are especially important for industrial applications in gaining trust from users. However, such a database is not readily available in industrial applications, and its acquisition is not trivial either. Active learning methods can be applied to ramp up data within a project deployment to iteratively increase the database, and thus the application predictability. Unfortunately, we observe that this often leads to a loss of user trust in the application, which is difficult to regain once lost. This leads to a "chicken-and-egg" dilemma in which neither the database nor the application is developed. In this work, we review state-of-the-art methods and approaches to further boost the database the initial active data ramp-up phase. Here, we focus on recent advancements in GenAI-based data generation and augmentation methods and review their adaptability on an industrial computer vision classification use case. Although we observe a potential for automatic data ramp-up, we also see a domain miss match in between the source (training environment) and target (industrial use-case) - regarding context defined in natural language and object characteristics.
Vanishing Depth: A Depth Adapter with Positional Depth Encoding for Generalized Image Encoders
Mar 25, 2025



Generalized metric depth understanding is critical for precise vision-guided robotics, which current state-of-the-art (SOTA) vision-encoders do not support. To address this, we propose Vanishing Depth, a self-supervised training approach that extends pretrained RGB encoders to incorporate and align metric depth into their feature embeddings. Based on our novel positional depth encoding, we enable stable depth density and depth distribution invariant feature extraction. We achieve performance improvements and SOTA results across a spectrum of relevant RGBD downstream tasks - without the necessity of finetuning the encoder. Most notably, we achieve 56.05 mIoU on SUN-RGBD segmentation, 88.3 RMSE on Void's depth completion, and 83.8 Top 1 accuracy on NYUv2 scene classification. In 6D-object pose estimation, we outperform our predecessors of DinoV2, EVA-02, and Omnivore and achieve SOTA results for non-finetuned encoders in several related RGBD downstream tasks.
MVIP -- A Dataset and Methods for Application Oriented Multi-View and Multi-Modal Industrial Part Recognition
Feb 21, 2025We present MVIP, a novel dataset for multi-modal and multi-view application-oriented industrial part recognition. Here we are the first to combine a calibrated RGBD multi-view dataset with additional object context such as physical properties, natural language, and super-classes. The current portfolio of available datasets offers a wide range of representations to design and benchmark related methods. In contrast to existing classification challenges, industrial recognition applications offer controlled multi-modal environments but at the same time have different problems than traditional 2D/3D classification challenges. Frequently, industrial applications must deal with a small amount or increased number of training data, visually similar parts, and varying object sizes, while requiring a robust near 100% top 5 accuracy under cost and time constraints. Current methods tackle such challenges individually, but direct adoption of these methods within industrial applications is complex and requires further research. Our main goal with MVIP is to study and push transferability of various state-of-the-art methods within related downstream tasks towards an efficient deployment of industrial classifiers. Additionally, we intend to push with MVIP research regarding several modality fusion topics, (automated) synthetic data generation, and complex data sampling -- combined in a single application-oriented benchmark.
Image and AIS Data Fusion Technique for Maritime Computer Vision Applications
Dec 07, 2023



Deep learning object detection methods, like YOLOv5, are effective in identifying maritime vessels but often lack detailed information important for practical applications. In this paper, we addressed this problem by developing a technique that fuses Automatic Identification System (AIS) data with vessels detected in images to create datasets. This fusion enriches ship images with vessel-related data, such as type, size, speed, and direction. Our approach associates detected ships to their corresponding AIS messages by estimating distance and azimuth using a homography-based method suitable for both fixed and periodically panning cameras. This technique is useful for creating datasets for waterway traffic management, encounter detection, and surveillance. We introduce a novel dataset comprising of images taken in various weather conditions and their corresponding AIS messages. This dataset offers a stable baseline for refining vessel detection algorithms and trajectory prediction models. To assess our method's performance, we manually annotated a portion of this dataset. The results are showing an overall association accuracy of 74.76 %, with the association accuracy for fixed cameras reaching 85.06 %. This demonstrates the potential of our approach in creating datasets for vessel detection, pose estimation and auto-labelling pipelines.
Generating Annotated Training Data for 6D Object Pose Estimation in Operational Environments with Minimal User Interaction
Mar 17, 2021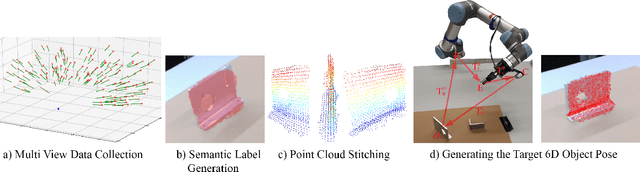



Recently developed deep neural networks achieved state-of-the-art results in the subject of 6D object pose estimation for robot manipulation. However, those supervised deep learning methods require expensive annotated training data. Current methods for reducing those costs frequently use synthetic data from simulations, but rely on expert knowledge and suffer from the "domain gap" when shifting to the real world. Here, we present a proof of concept for a novel approach of autonomously generating annotated training data for 6D object pose estimation. This approach is designed for learning new objects in operational environments while requiring little interaction and no expertise on the part of the user. We evaluate our autonomous data generation approach in two grasping experiments, where we archive a similar grasping success rate as related work on a non autonomously generated data set.
InterpretML: A Unified Framework for Machine Learning Interpretability
Sep 19, 2019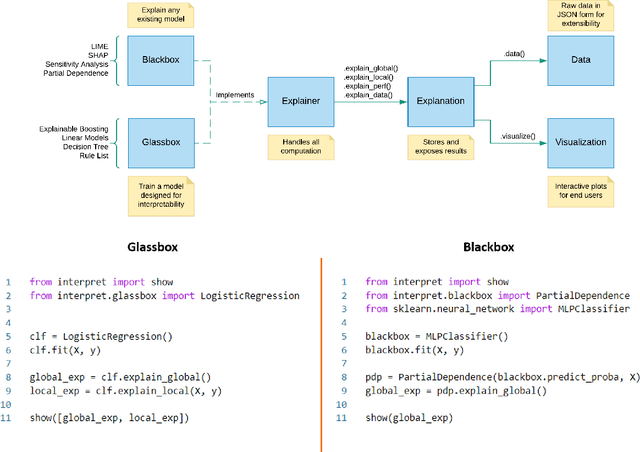
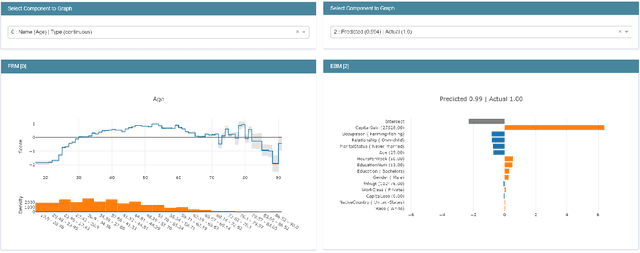
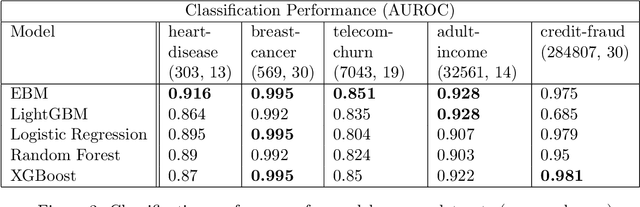
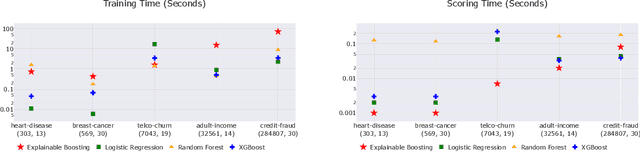
InterpretML is an open-source Python package which exposes machine learning interpretability algorithms to practitioners and researchers. InterpretML exposes two types of interpretability - glassbox models, which are machine learning models designed for interpretability (ex: linear models, rule lists, generalized additive models), and blackbox explainability techniques for explaining existing systems (ex: Partial Dependence, LIME). The package enables practitioners to easily compare interpretability algorithms by exposing multiple methods under a unified API, and by having a built-in, extensible visualization platform. InterpretML also includes the first implementation of the Explainable Boosting Machine, a powerful, interpretable, glassbox model that can be as accurate as many blackbox models. The MIT licensed source code can be downloaded from github.com/microsoft/interpret.
Interpretability is Harder in the Multiclass Setting: Axiomatic Interpretability for Multiclass Additive Models
Oct 22, 2018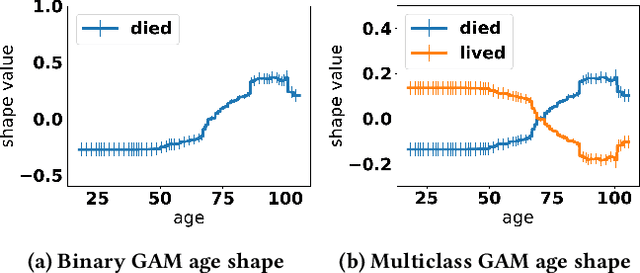
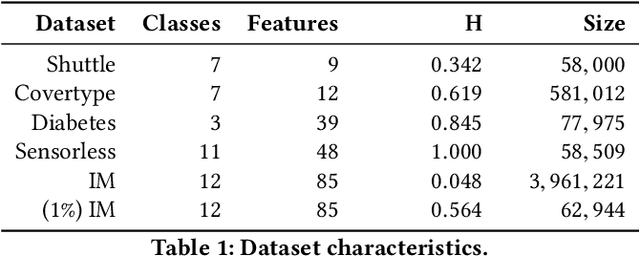
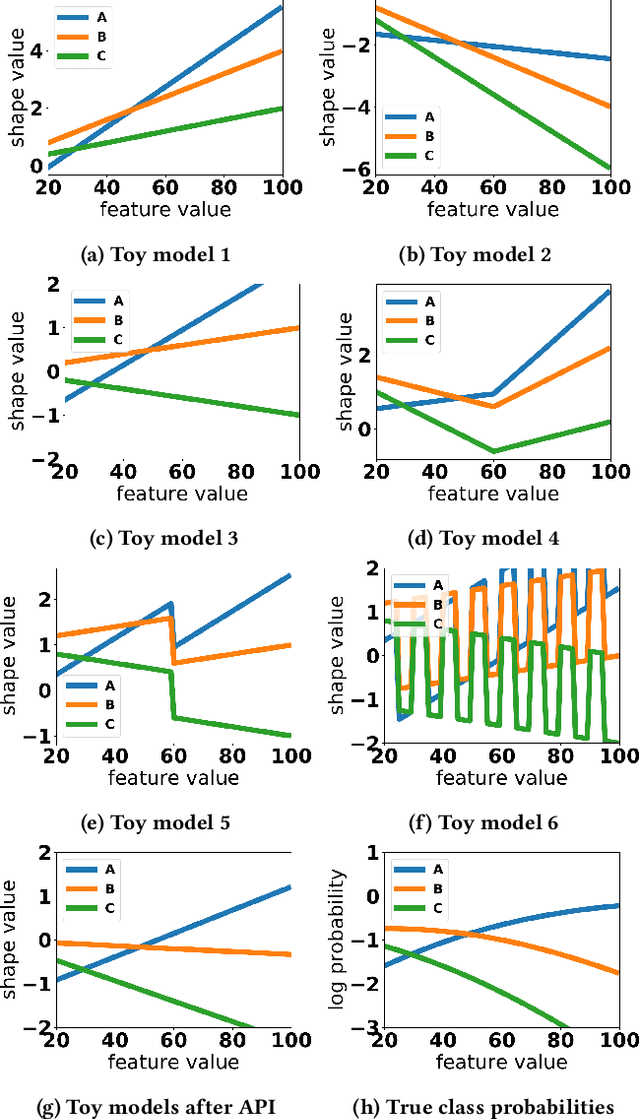
Generalized additive models (GAMs) are favored in many regression and binary classification problems because they are able to fit complex, nonlinear functions while still remaining interpretable. In the first part of this paper, we generalize a state-of-the-art GAM learning algorithm based on boosted trees to the multiclass setting, and show that this multiclass algorithm outperforms existing GAM fitting algorithms and sometimes matches the performance of full complex models. In the second part, we turn our attention to the interpretability of GAMs in the multiclass setting. Surprisingly, the natural interpretability of GAMs breaks down when there are more than two classes. Drawing inspiration from binary GAMs, we identify two axioms that any additive model must satisfy to not be visually misleading. We then develop a post-processing technique (API) that provably transforms pretrained additive models to satisfy the interpretability axioms without sacrificing accuracy. The technique works not just on models trained with our algorithm, but on any multiclass additive model. We demonstrate API on a 12-class infant-mortality dataset.
Coordinates: Probabilistic Forecasting of Presence and Availability
Dec 12, 2012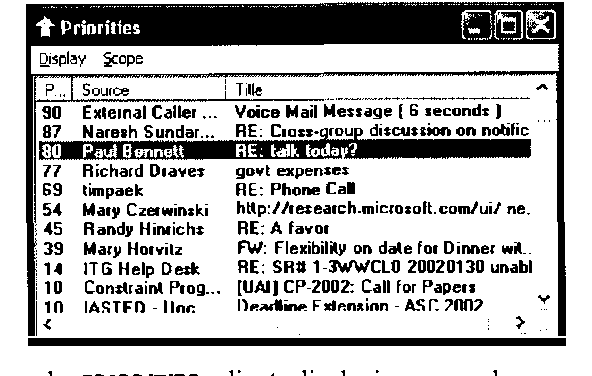
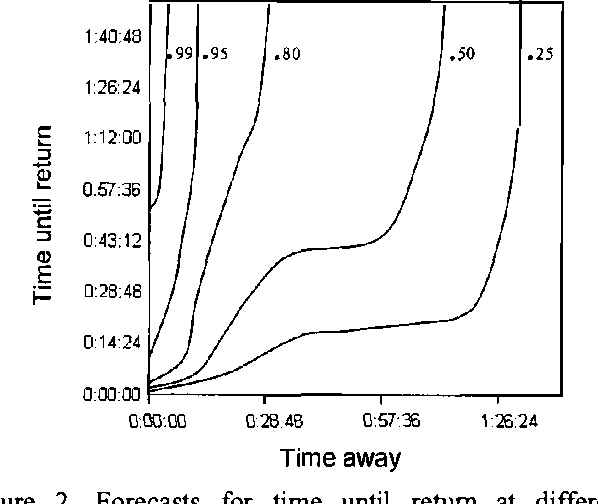
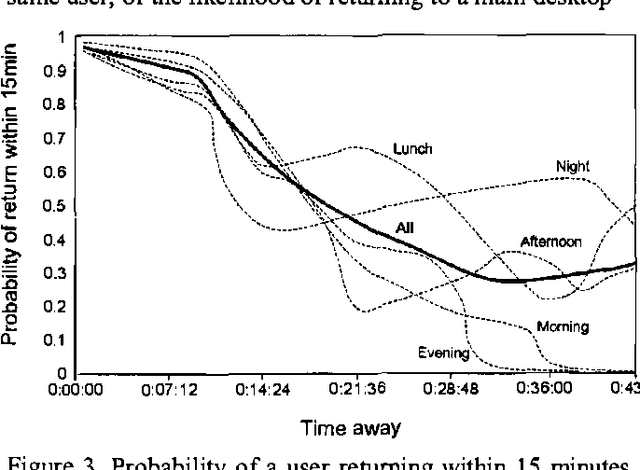

We present methods employed in Coordinate, a prototype service that supports collaboration and communication by learning predictive models that provide forecasts of users s AND availability.We describe how data IS collected about USER activity AND proximity FROM multiple devices, IN addition TO analysis OF the content OF users, the time of day, and day of week. We review applications of presence forecasting embedded in the Priorities application and then present details of the Coordinate service that was informed by the earlier efforts.