 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFW: A Collaborative Filtering System Using Posteriors Over Weights Of Evidence
May 16, 2015

We describe CFW, a computationally efficient algorithm for collaborative filtering that uses posteriors over weights of evidence. In experiments on real data, we show that this method predicts as well or better than other methods in situations where the size of the user query is small. The new approach works particularly well when the user s query CONTAINS low frequency(unpopular) items.The approach complements that OF dependency networks which perform well WHEN the size OF the query IS large.Also IN this paper, we argue that the USE OF posteriors OVER weights OF evidence IS a natural way TO recommend similar items collaborative - filtering task.
Rational Nonmonotonic Reasoning
Mar 27, 2013Nonmonotonic reasoning is a pattern of reasoning that allows an agent to make and retract (tentative) conclusions from inconclusive evidence. This paper gives a possible-worlds interpretation of the nonmonotonic reasoning problem based on standard decision theory and the emerging probability logic. The system's central principle is that a tentative conclusion is a decision to make a bet, not an assertion of fact. The system is rational, and as sound as the proof theory of its underlying probability log.
Empirical Analysis of Predictive Algorithms for Collaborative Filtering
Jan 30, 2013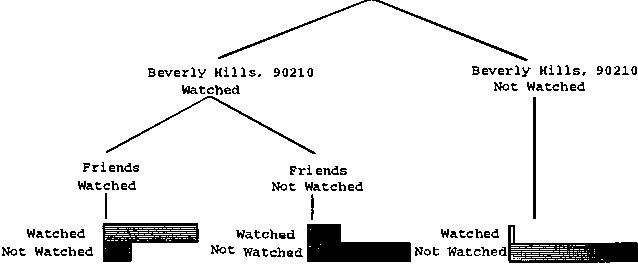

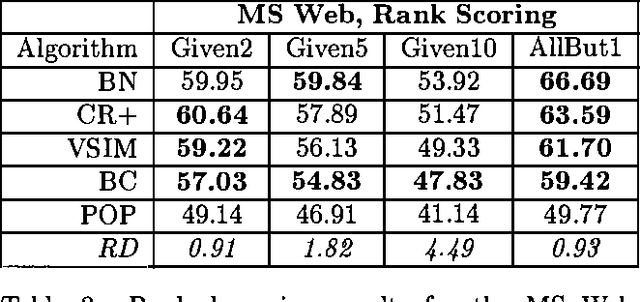

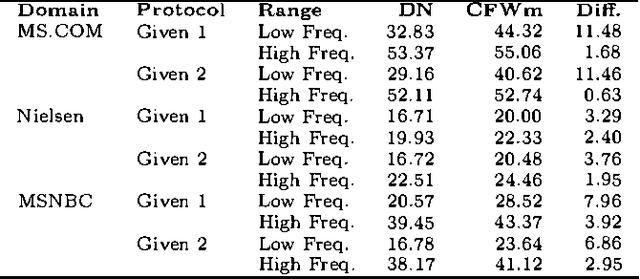
Collaborative filtering or recommender systems use a database about user preferences to predict additional topics or products a new user might like. In this paper we describe several algorithms designed for this task, including techniques based on correlation coefficients, vector-based similarity calculations, and statistical Bayesian methods. We compare the predictive accuracy of the various methods in a set of representative problem domains. We use two basic classes of evaluation metrics. The first characterizes accuracy over a set of individual predictions in terms of average absolute deviation. The second estimates the utility of a ranked list of suggested items. This metric uses an estimate of the probability that a user will see a recommendation in an ordered list. Experiments were run for datasets associated with 3 application areas, 4 experimental protocols, and the 2 evaluation metrics for the various algorithms. Results indicate that for a wide range of conditions, Bayesian networks with decision trees at each node and correlation methods outperform Bayesian-clustering and vector-similarity methods. Between correlation and Bayesian networks, the preferred method depends on the nature of the dataset, nature of the application (ranked versus one-by-one presentation), and the availability of votes with which to make predictions. Other considerations include the size of database, speed of predictions, and learning time.
Dependency Networks for Collaborative Filtering and Data Visualization
Jan 16, 2013
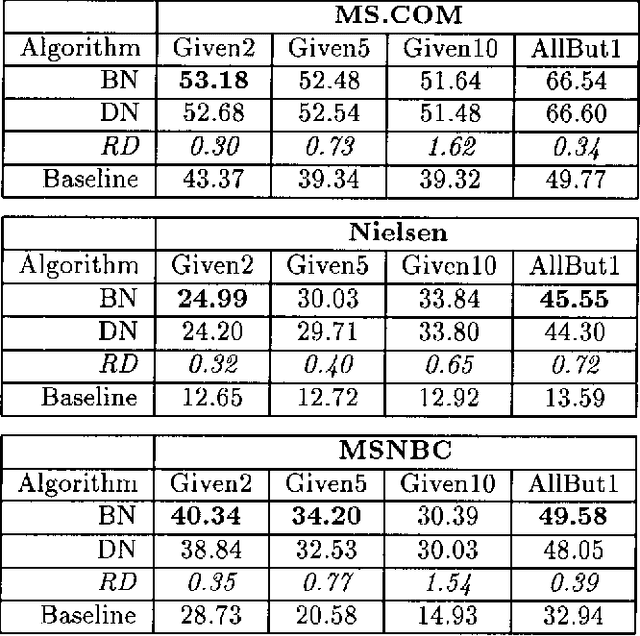
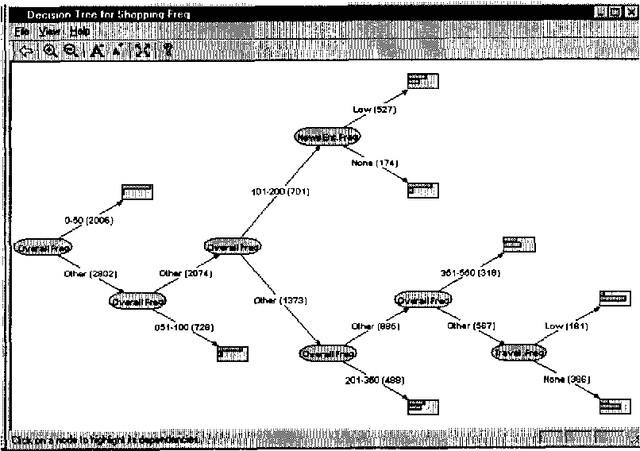
We describe a graphical model for probabilistic relationships---an alternative to the Bayesian network---called a dependency network. The graph of a dependency network, unlike a Bayesian network, is potentially cyclic. The probability component of a dependency network, like a Bayesian network, is a set of conditional distributions, one for each node given its parents. We identify several basic properties of this representation and describe a computationally efficient procedure for learning the graph and probability components from data. We describe the application of this representation to probabilistic inference, collaborative filtering (the task of predicting preferences), and the visualization of acausal predictive relationships.
Coordinates: Probabilistic Forecasting of Presence and Availability
Dec 12, 2012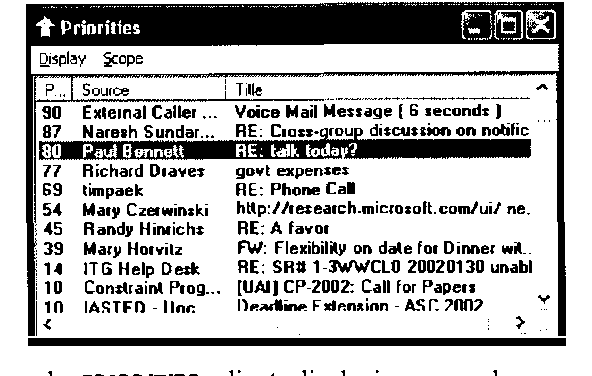
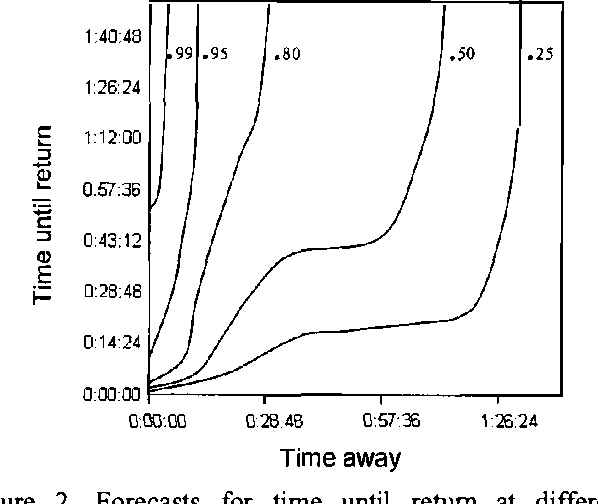
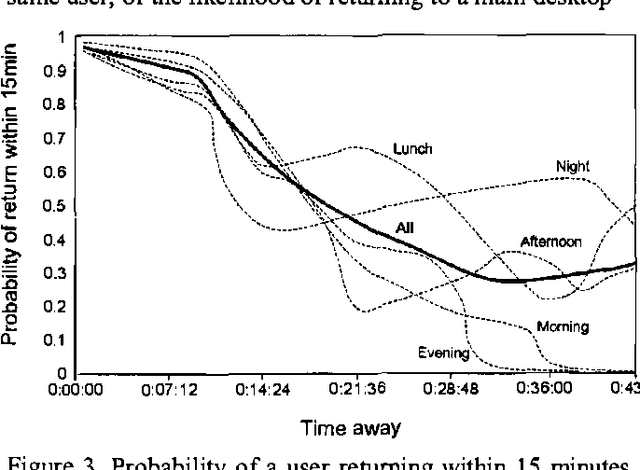

We present methods employed in Coordinate, a prototype service that supports collaboration and communication by learning predictive models that provide forecasts of users s AND availability.We describe how data IS collected about USER activity AND proximity FROM multiple devices, IN addition TO analysis OF the content OF users, the time of day, and day of week. We review applications of presence forecasting embedded in the Priorities application and then present details of the Coordinate service that was informed by the earlier efforts.