 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVIP -- A Dataset and Methods for Application Oriented Multi-View and Multi-Modal Industrial Part Recognition
Feb 21, 2025We present MVIP, a novel dataset for multi-modal and multi-view application-oriented industrial part recognition. Here we are the first to combine a calibrated RGBD multi-view dataset with additional object context such as physical properties, natural language, and super-classes. The current portfolio of available datasets offers a wide range of representations to design and benchmark related methods. In contrast to existing classification challenges, industrial recognition applications offer controlled multi-modal environments but at the same time have different problems than traditional 2D/3D classification challenges. Frequently, industrial applications must deal with a small amount or increased number of training data, visually similar parts, and varying object sizes, while requiring a robust near 100% top 5 accuracy under cost and time constraints. Current methods tackle such challenges individually, but direct adoption of these methods within industrial applications is complex and requires further research. Our main goal with MVIP is to study and push transferability of various state-of-the-art methods within related downstream tasks towards an efficient deployment of industrial classifiers. Additionally, we intend to push with MVIP research regarding several modality fusion topics, (automated) synthetic data generation, and complex data sampling -- combined in a single application-oriented benchmark.
Generating Annotated Training Data for 6D Object Pose Estimation in Operational Environments with Minimal User Interaction
Mar 17, 2021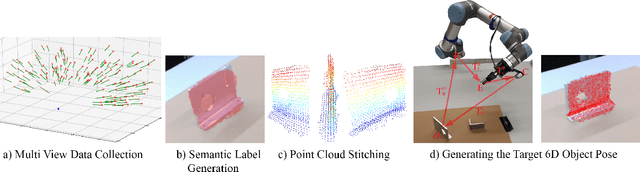



Recently developed deep neural networks achieved state-of-the-art results in the subject of 6D object pose estimation for robot manipulation. However, those supervised deep learning methods require expensive annotated training data. Current methods for reducing those costs frequently use synthetic data from simulations, but rely on expert knowledge and suffer from the "domain gap" when shifting to the real world. Here, we present a proof of concept for a novel approach of autonomously generating annotated training data for 6D object pose estimation. This approach is designed for learning new objects in operational environments while requiring little interaction and no expertise on the part of the user. We evaluate our autonomous data generation approach in two grasping experiments, where we archive a similar grasping success rate as related work on a non autonomously generated data set.