 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in the Description Logic ALC under Category Semantics
May 14, 2022



We present in this paper a reformulation of the usual set-theoretical semantics of the description logic $\mathcal{ALC}$ with general TBoxes by using categorical language. In this setting, $\mathcal{ALC}$ concepts are represented as objects, concept subsumptions as arrows, and memberships as logical quantifiers over objects and arrows of categories. Such a category-based semantics provides a more modular representation of the semantics of $\mathcal{ALC}$. This feature allows us to define a sublogic of $\mathcal{ALC}$ by dropping the interaction between existential and universal restrictions, which would be responsible for an exponential complexity in space. Such a sublogic is undefinable in the usual set-theoretical semantics, We show that this sublogic is {\sc{PSPACE}} by proposing a deterministic algorithm for checking concept satisfiability which runs in polynomial space.
Algorithme de recherche approximative dans un dictionnaire fondé sur une distance d'édition définie par blocs
Sep 01, 2021
We propose an algorithm for approximative dictionary lookup, where altered strings are matched against reference forms. The algorithm makes use of a divergence function between strings -- broadly belonging to the family of edit distances; it finds dictionary entries whose distance to the search string is below a certain threshold. The divergence function is not the classical edit distance (DL distance); it is adaptable to a particular corpus, and is based on elementary alteration costs defined on character blocks, rather than on individual characters. Nous proposons un algorithme de recherche approximative de cha\^ines dans un dictionnaire \`a partir de formes alt\'er\'ees. Cet algorithme est fond\'e sur une fonction de divergence entre cha\^ines~ -- une sorte de distance d'\'edition: il recherche des entr\'ees pour lesquelles la distance \`a la cha\^ine cherch\'ee est inf\'erieure \`a un certain seuil. La fonction utilis\'ee n'est pas la distance d'\'edition classique (distance DL); elle est adapt\'ee \`a un corpus, et se fonde sur la prise en compte de co\^uts d'alt\'eration \'el\'ementaires d\'efinis non pas sur des caract\`eres, mais sur des sous-cha\^ines (des blocs de caract\`eres).
Hybrid Approaches for our Participation to the n2c2 Challenge on Cohort Selection for Clinical Trials
Mar 19, 2019

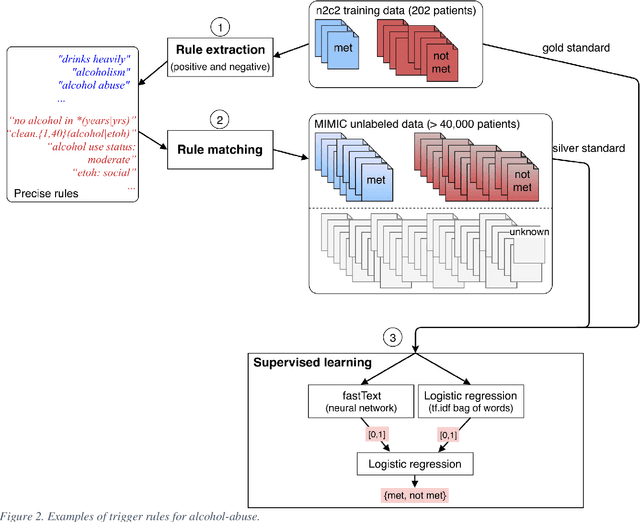
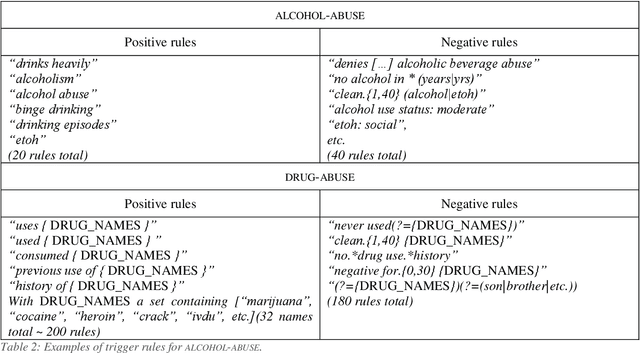
Objective: Natural language processing can help minimize human intervention in identifying patients meeting eligibility criteria for clinical trials, but there is still a long way to go to obtain a general and systematic approach that is useful for researchers. We describe two methods taking a step in this direction and present their results obtained during the n2c2 challenge on cohort selection for clinical trials. Materials and Methods: The first method is a weakly supervised method using an unlabeled corpus (MIMIC) to build a silver standard, by producing semi-automatically a small and very precise set of rules to detect some samples of positive and negative patients. This silver standard is then used to train a traditional supervised model. The second method is a terminology-based approach where a medical expert selects the appropriate concepts, and a procedure is defined to search the terms and check the structural or temporal constraints. Results: On the n2c2 dataset containing annotated data about 13 selection criteria on 288 patients, we obtained an overall F1-measure of 0.8969, which is the third best result out of 45 participant teams, with no statistically significant difference with the best-ranked team. Discussion: Both approaches obtained very encouraging results and apply to different types of criteria. The weakly supervised method requires explicit descriptions of positive and negative examples in some reports. The terminology-based method is very efficient when medical concepts carry most of the relevant information. Conclusion: It is unlikely that much more annotated data will be soon available for the task of identifying a wide range of patient phenotypes. One must focus on weakly or non-supervised learning methods using both structured and unstructured data and relying on a comprehensive representation of the patients.
Using graph transformation algorithms to generate natural language equivalents of icons expressing medical concepts
Sep 26, 2014
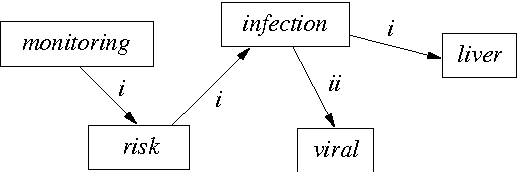
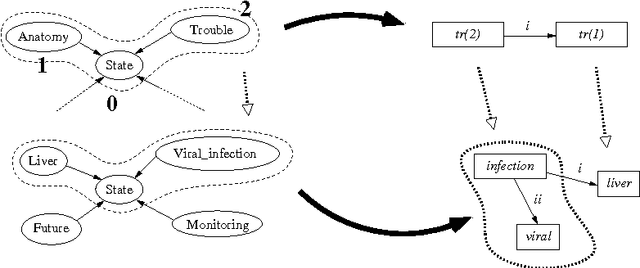
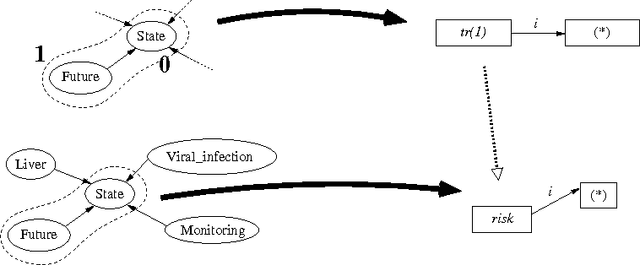
A graphical language addresses the need to communicate medical information in a synthetic way. Medical concepts are expressed by icons conveying fast visual information about patients' current state or about the known effects of drugs. In order to increase the visual language's acceptance and usability, a natural language generation interface is currently developed. In this context, this paper describes the use of an informatics method ---graph transformation--- to prepare data consisting of concepts in an OWL-DL ontology for use in a natural language generation component. The OWL concept may be considered as a star-shaped graph with a central node. The method transforms it into a graph representing the deep semantic structure of a natural language phrase. This work may be of future use in other contexts where ontology concepts have to be mapped to half-formalized natural language expressions.
Soft Uncoupling of Markov Chains for Permeable Language Distinction: A New Algorithm
Oct 07, 2008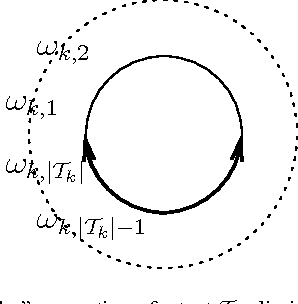


Without prior knowledge, distinguishing different languages may be a hard task, especially when their borders are permeable. We develop an extension of spectral clustering -- a powerful unsupervised classification toolbox -- that is shown to resolve accurately the task of soft language distinction. At the heart of our approach, we replace the usual hard membership assignment of spectral clustering by a soft, probabilistic assignment, which also presents the advantage to bypass a well-known complexity bottleneck of the method. Furthermore, our approach relies on a novel, convenient construction of a Markov chain out of a corpus. Extensive experiments with a readily available system clearly display the potential of the method, which brings a visually appealing soft distinction of languages that may define altogether a whole corpus.
* 6 pages, 7 embedded figures, LaTeX 2e using the ecai2006.cls document class and the algorithm2e.sty style file (+ standard packages like epsfig, amsmath, amssymb, amsfonts...). Extends the short version contained in the ECAI 2006 proceedings
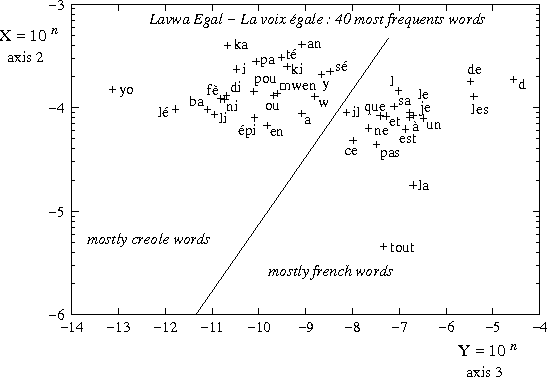
Analyse spectrale des textes: détection automatique des frontières de langue et de discours
Oct 07, 2008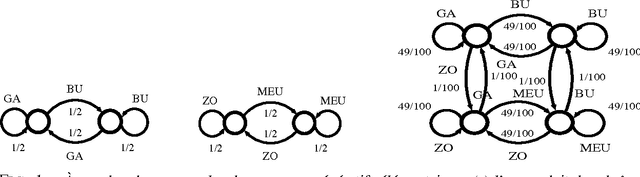

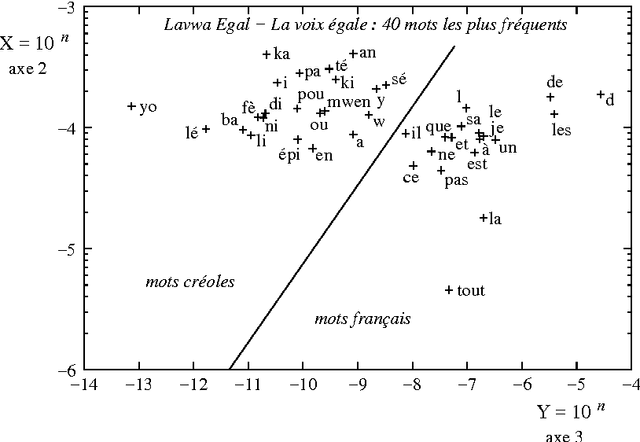
We propose a theoretical framework within which information on the vocabulary of a given corpus can be inferred on the basis of statistical information gathered on that corpus. Inferences can be made on the categories of the words in the vocabulary, and on their syntactical properties within particular languages. Based on the same statistical data, it is possible to build matrices of syntagmatic similarity (bigram transition matrices) or paradigmatic similarity (probability for any pair of words to share common contexts). When clustered with respect to their syntagmatic similarity, words tend to group into sublanguage vocabularies, and when clustered with respect to their paradigmatic similarity, into syntactic or semantic classes. Experiments have explored the first of these two possibilities. Their results are interpreted in the frame of a Markov chain modelling of the corpus' generative processe(s): we show that the results of a spectral analysis of the transition matrix can be interpreted as probability distributions of words within clusters. This method yields a soft clustering of the vocabulary into sublanguages which contribute to the generation of heterogeneous corpora. As an application, we show how multilingual texts can be visually segmented into linguistically homogeneous segments. Our method is specifically useful in the case of related languages which happened to be mixed in corpora.
* In French. 10 pages, 5 figures, LaTeX 2e using EPSF and custom package taln2006.sty (designed by Pierre Zweigenbaum, ATALA). Proceedings of the 13th annual French-speaking conference on Natural Language Processing: `Traitement Automatique des Langues Naturelles' (TALN 2006), Louvain (Leuven), Belgium, 10-13 April 2003
A Layered Grammar Model: Using Tree-Adjoining Grammars to Build a Common Syntactic Kernel for Related Dialects
Oct 07, 2008



This article describes the design of a common syntactic description for the core grammar of a group of related dialects. The common description does not rely on an abstract sub-linguistic structure like a metagrammar: it consists in a single FS-LTAG where the actual specific language is included as one of the attributes in the set of attribute types defined for the features. When the lang attribute is instantiated, the selected subset of the grammar is equivalent to the grammar of one dialect. When it is not, we have a model of a hybrid multidialectal linguistic system. This principle is used for a group of creole languages of the West-Atlantic area, namely the French-based Creoles of Haiti, Guadeloupe, Martinique and French Guiana.
* 8 pages, 3 figures, 2 tables. LaTeX 2e using the coling08 style (and standard packages like epsf, amssymb, multirow, url...). Proceedings of the 9th International Workshop on Tree Adjoining Grammars and Related Formalisms. Tuebingen, Baden-Wurttemberg, Germany, 6-8 June 2008
Une grammaire formelle du créole martiniquais pour la génération automatique
Oct 07, 2008



In this article, some first elements of a computational modelling of the grammar of the Martiniquese French Creole dialect are presented. The sources of inspiration for the modelling is the functional description given by Damoiseau (1984), and Pinalie's & Bernabe's (1999) grammar manual. Based on earlier works in text generation (Vaillant, 1997), a unification grammar formalism, namely Tree Adjoining Grammars (TAG), and a modelling of lexical functional categories based on syntactic and semantic properties, are used to implement a grammar of Martiniquese Creole which is used in a prototype of text generation system. One of the main applications of the system could be its use as a tool software supporting the task of learning Creole as a second language. -- Nous pr\'esenterons dans cette communication les premiers travaux de mod\'elisation informatique d'une grammaire de la langue cr\'eole martiniquaise, en nous inspirant des descriptions fonctionnelles de Damoiseau (1984) ainsi que du manuel de Pinalie & Bernab\'e (1999). Prenant appui sur des travaux ant\'erieurs en g\'en\'eration de texte (Vaillant, 1997), nous utilisons un formalisme de grammaires d'unification, les grammaires d'adjonction d'arbres (TAG d'apr\`es l'acronyme anglais), ainsi qu'une mod\'elisation de cat\'egories lexicales fonctionnelles \`a base syntaxico-s\'emantique, pour mettre en oeuvre une grammaire du cr\'eole martiniquais utilisable dans une maquette de syst\`eme de g\'en\'eration automatique. L'un des int\'er\^ets principaux de ce syst\`eme pourrait \^etre son utilisation comme logiciel outil pour l'aide \`a l'apprentissage du cr\'eole en tant que langue seconde.
* In French. 10 pages, 4 figures, LaTeX 2e using EPSF and custom package Taln2003.sty (JC/PZ, ATALA). Proceedings of the 10th annual French-speaking conference on Natural Language Processing: `Traitement Automatique des Langues Naturelles' (TALN 2003), Batz-sur-mer, France, 10-14 June 2003
A Chart-Parsing Algorithm for Efficient Semantic Analysis
Sep 02, 2002
In some contexts, well-formed natural language cannot be expected as input to information or communication systems. In these contexts, the use of grammar-independent input (sequences of uninflected semantic units like e.g. language-independent icons) can be an answer to the users' needs. A semantic analysis can be performed, based on lexical semantic knowledge: it is equivalent to a dependency analysis with no syntactic or morphological clues. However, this requires that an intelligent system should be able to interpret this input with reasonable accuracy and in reasonable time. Here we propose a method allowing a purely semantic-based analysis of sequences of semantic units. It uses an algorithm inspired by the idea of ``chart parsing'' known in Natural Language Processing, which stores intermediate parsing results in order to bring the calculation time down. In comparison with using declarative logic programming - where the calculation time, left to a prolog engine, is hyperexponential -, this method brings the calculation time down to a polynomial time, where the order depends on the valency of the predicates.
* 7 pages, 1 figure, LaTeX 2e using COLACL and EPSF packages. Proceedings of the 19th International Conference on Computational Linguistics (COLING 2002), Taipei, Republic of China (Taiwan), 24 Aug. - 1 Sept. 2002
Modelling Semantic Association and Conceptual Inheritance for Semantic Analysis
Sep 15, 2001
Allowing users to interact through language borders is an interesting challenge for information technology. For the purpose of a computer assisted language learning system, we have chosen icons for representing meaning on the input interface, since icons do not depend on a particular language. However, a key limitation of this type of communication is the expression of articulated ideas instead of isolated concepts. We propose a method to interpret sequences of icons as complex messages by reconstructing the relations between concepts, so as to build conceptual graphs able to represent meaning and to be used for natural language sentence generation. This method is based on an electronic dictionary containing semantic information.
* 8 pages, 2 figures, LaTeX 2e using Springer LNCS class, with packages epsf and amssymb. Proceedings of the 4th International Conference on Text, Speech and Dialogue (TSD 2001), Zelezna Ruda, Czech Republic, 10-13 Sept. 2001