 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Uncoupling of Markov Chains for Permeable Language Distinction: A New Algorithm
Paper and Code
Oct 07, 2008


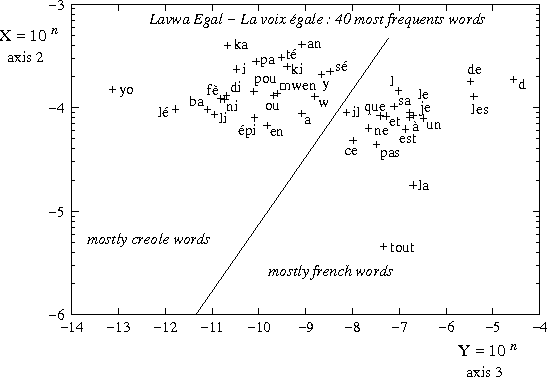
Without prior knowledge, distinguishing different languages may be a hard task, especially when their borders are permeable. We develop an extension of spectral clustering -- a powerful unsupervised classification toolbox -- that is shown to resolve accurately the task of soft language distinction. At the heart of our approach, we replace the usual hard membership assignment of spectral clustering by a soft, probabilistic assignment, which also presents the advantage to bypass a well-known complexity bottleneck of the method. Furthermore, our approach relies on a novel, convenient construction of a Markov chain out of a corpus. Extensive experiments with a readily available system clearly display the potential of the method, which brings a visually appealing soft distinction of languages that may define altogether a whole corpus.